原文:https://www.cnblogs.com/zihe/p/6993891.html
RAM——random-access memory——随机存储器——内存
default——默认值
import sys
sys.getdefaultencoding() 取得系统默认编码
1、文本编辑器存取文件的原理(nodepad++,pycharm,word):
打开编辑器 = 开一个进程(内存中)
例:open new .py file(RAM) ————edit(RAM)————save(RAM to disk)
注:berore Saving , after edit ,——断电——data loss
Python解释器(解释执行文件内容):读取文件,编辑,保存,运行。
文件编辑器:读取文件,编辑,保存。
2、字符编码
起因:
compt只认识0,1(高电平,低电平)
字符--------(翻译过程)------->数字 01
翻译过程:一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
过程:
ASCII:英文字符/键盘上的所有其他字符总个数<2^8=256=8bit=1Bite(后增加了拉丁文)
GBK(Chinese)、Shift_JIS(Japanese)、Euc-kr(Korean)
unicode:万国码(有的语言不行),所有国家的字符总个数<2^16-1=65535=16bit=2Bite
UTF-7, UTF-7.5, UTF-8(变长码),UTF-16, 以及 UTF-32。
注:
UNICODE支持欧洲、非洲、中东、亚洲(包括统一标准的东亚象形汉字和韩国表音文字)。但是,UNICODE并没有提供对诸如Braille(盲文),Cherokee, Ethiopic(埃塞俄比亚语), Khmer(高棉语)等。
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
3、
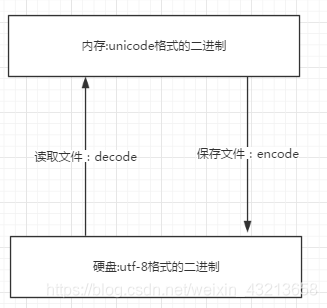
注:
无论是何种编辑器,要防止文件出现乱码
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
4、程序的执行
open new .py file(RAM) ————edit(RAM)————save(RAM to disk)————Run
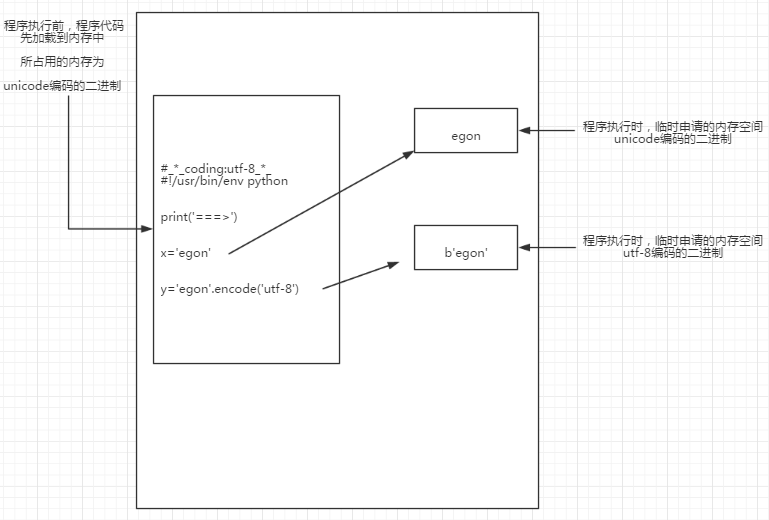
Read:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x=“egon”
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x=“egon”,其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x=“egon”,会被python解释器识别为字符串,会申请内存空间来存放"egon",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x=“egon”.encode(‘utf-8’),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
附:
读取第一行代码
#coding:utf-8 #设置编码格式utf-8
import sys
print(sys.getdefaultencoding()) #查看编码格式
注:python2中默认使用ascii,python3中默认使用utf-8
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
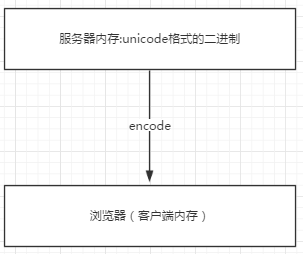
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
5、Python2与Python3
Python2:两种字符串类型str和unicode,str=bytes,unicode=bytes/str
Python3:两种字符串类型str和bytes,str=unicode,bytes=bytes
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk')
print(type(s)) #<class 'str'>
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s1=s.encode('utf-8')
s2=s.encode('gbk')
print(s) #林
print(s1) #b'\xe6\x9e\x97' 在python3中,是什么就打印什么
print(s2) #b'\xc1\xd6' 同上
print(type(s)) #<class 'str'>
print(type(s1)) #<class 'bytes'>
print(type(s2)) #<class 'bytes'>
unicode编码
#coding:utf-8
s=u'林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#print(type(s.encode('utf-8')) #错误,因为u,已经encode为Unicode
print(type(s)) #<class 'str'>