如何使用BERT模型实现中文的文本分类
前言
Pytorch
readme
- 请先安装pytorch的BERT代码,代码源见前言(2)
pip install pytorch-pretrained-bert
参数表
| data_dir | bert_model | task_name |
|---|---|---|
| 输入数据目录 | 加载的bert模型,对于中文文本请输入’bert-base-chinese’ | 输入数据预处理模块,最好根据应用场景自定义 |
| model_save_pth | max_seq_length* | train_batch_size |
| 模型参数保存地址 | 最大文本长度 | batch大小 |
| learning_rate | num_train_epochs | |
| Adam初始学习步长 | 最大epoch数 |
* max_seq_length = 所设定的文本长度 + 2 ,BERT会给每个输入文本开头和结尾分别加上[CLS]和[SEP]标识符,因此会占用2个字符空间,其作用会在后续进行详细说明。
算法流程
1. 概述
2. 读取数据
- 对应于参数表中的task_name,是用于数据读取的模块
- 可以根据自身需要自定义新的数据读取模块
- 以输入数据为json文件时为例,数据读取模块包含两个部分:
- 基类DataProcessor:
class DataProcessor(object): def get_train_examples(self, data_dir): raise NotImplementedError() def get_dev_examples(self, data_dir): raise NotImplementedError() def get_test_examples(self, data_dir): raise NotImplementedError() def get_labels(self): raise NotImplementedError() @classmethod def _read_json(cls, input_file, quotechar=None): """Reads a tab separated value file.""" dicts = [] with codecs.open(input_file, 'r', 'utf-8') as infs: for inf in infs: inf = inf.strip() dicts.append(json.loads(inf)) return dicts - 用于数据读取的模块MyPro:
class MyPro(DataProcessor): def get_train_examples(self, data_dir): return self._create_examples( self._read_json(os.path.join(data_dir, "train.json")), 'train') def get_dev_examples(self, data_dir): return self._create_examples( self._read_json(os.path.join(data_dir, "val.json")), 'dev') def get_test_examples(self, data_dir): return self._create_examples( self._read_json(os.path.join(data_dir, "test.json")), 'test') def get_labels(self): return [0, 1] def _create_examples(self, dicts, set_type): examples = [] for (i, infor) in enumerate(dicts): guid = "%s-%s" % (set_type, i) text_a = infor['question'] label = infor['label'] examples.append( InputExample(guid=guid, text_a=text_a, label=label)) return examples
- 基类DataProcessor:
- 需要注意的几点是:
- data_dir目录下应包含名为train、val、test的三个文件,根据文件格式不同需要对读取方式进行修改
- get_labels()返回的是所有可能的类别label_list,比如
['数学', '英语', '语文']、[1, 2, 3]… - 模块最终返回一个名为examples的列表,每个列表元素中包含序号、中文文本、类别三个元素
3. 特征转换
- convert_examples_to_features是用于将examples转换为特征,也即features的函数。
- features包含4个数据:
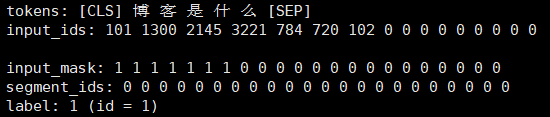
- input_ids:分词后每个词语在vocabulary中的id,补全符号对应的id为0,[CLS]和[SEP]的id分别为101和102。应注意的是,在中文BERT模型中,中文分词是基于字而非词的分词。
- input_mask:真实字符/补全字符标识符,真实文本的每个字对应1,补全符号对应0,[CLS]和[SEP]也为1。
- segment_ids:句子A和句子B分隔符,句子A对应的全为0,句子B对应的全为1。但是在多数文本分类情况下并不会用到句子B,所以基本不用管。
- label_id :将label_list中的元素利用字典转换为index标识,即
label_map = {} for (i, label) in enumerate(label_list): label_map[label] = i
- features中一个元素的例子是:
- 转换完成后的特征值就可以作为输入,用于模型的训练和测试
4. 模型训练
- 完成读取数据、特征转换之后,将特征送入模型进行训练
- 训练算法为BERT专用的Adam算法
- 训练集、测试集、验证集比例为6:2:2
- 每一个epoch后会在验证集上进行验证,并给出相应的f1值,如果f1值大于此前最高分则保存模型参数,否则flags加1。如果flags大于6,也即连续6个epoch模型的性能都没有继续优化,停止训练过程。
f1 = val(model, processor, args, label_list, tokenizer, device) if f1 > best_score: best_score = f1 print('*f1 score = {}'.format(f1)) flags = 0 checkpoint = { 'state_dict': model.state_dict() } torch.save(checkpoint, args.model_save_pth) else: print('f1 score = {}'.format(f1)) flags += 1 if flags >=6: break - 如果epoch数超过先前设定的num_train_epochs,同样会停止迭代。
5. 模型测试
- 先加载模型
- 送数据,取得分,完事
- 暂时还没加打印测试结果到文件的功能,后续会加上
6. 测试结果
| val_F1 | test_F1 | |
|---|---|---|
| Fast text | 0.7218 | 0.7094 |
| Text rnn + bigru | 0.7383 | 0.7194 |
| Text cnn | 0.7292 | 0.7088 |
| bigru + attention | 0.7335 | 0.7146 |
| RCNN | 0.7355 | 0.7213 |
| BERT | 0.7938 | 0.787 |
- 基于真实数据做的文本分类,用过不少模型,BERT的性能可以说是独一档
- BERT确实牛逼,不过一部分原因也是模型量级就不一样
7. 总结
- 使用代码的时候按照参数表修改下参数,把数据按照命名规范放data_dir目录下一般就没啥问题了
- 最多还要修改下读取数据的代码(如果数据不是.json格式的),就可以跑通了
- 最后可以根据个人需要,对模型训练逻辑、epoch数、学习步长等地方做进一步修改
- 代码地址已经放在前言(3)里了
Tensorflow
readme
涂壁抗体纽的