协同过滤
协同过滤就是根据实体之间的一些相似性,过滤到所有实体中的一些实体。
例如:下面是一个关于几个用户对几部电影的评分表格。竖着的表头表示不同的用户,横向表头表示不同的电影。

假如,我们想知道Claudia Puig这位童鞋给《Lady in the Water》这部电影评分多少。
那么,我们首先就要找到,谁和Claudia Puig这位童鞋具有相似的喜好。
对于计算用户的相似性的方法,我们一般有以下几种:
1.计算欧氏距离。
2.计算用户之间的余弦相似性。
欧氏距离

我们就每一部电影,将Claudia Puig这位童鞋与其他童鞋评分进行计算。其中,没有评分的不参与计算。最终发现,Lisa Rose与Claudia Puig是最接近的,我们就将Lisa Rose对于《Lady in the Water》这部电影评分作为Lisa Rose对于这部电影的评分进行预测。
但是这里存在这样的问题:
A和B虽然对于同一部电影的观影感受是一样的,但是他们的评分的严厉性是不一样的,那么就会导致我们的估计是不可行的。
我们将优化这个算法:
首先计算每个人的观影评分的平均值:

其次,我们计算对于每部电影的评分,与平均评分的差异(实际值-平均值):

再根据每个人对于不同电影评分与自己评分平均值的差异按照上述的欧式距离的算法,计算不同用户之间的差异。

我们发现,最终还是Lisa Rose和Claudia Puig是最接近的,此时,我们对于Claudia Puig评分预测不再直接根据Lisa的评分直接估计。而是:
Lisa对于《Lady in the Water》的评分比她对于所有电影评分均值低了0.5分。恰好低了8%。按照这样,我们计算Claudia Puig对于《Lady in the Water》的评分:
3.5*(1-0.5/3) = 2.91
我们发现,仅仅靠找到一个最接近的用户的评分习惯对想要预测的用户的评分习惯进行估计是不准确的,应该找到多个用户(K个),对其值进行加权平均,这样会更科学一些。
余弦相似性
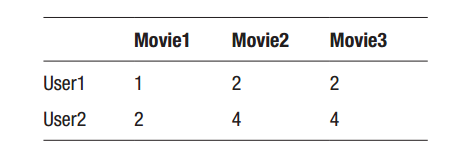
在上表中,我们发现。虽然两个人的观影感受(对于Movie1的评分比Movie2和Movie3的评分要低)是一致的,但是评分的习惯是不同的(对于每部电影的评分不尽相同)。
单纯的用欧氏距离计算是不科学的:
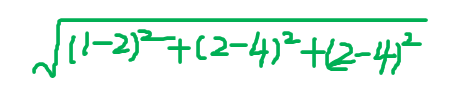
余弦相似性的计算方法:
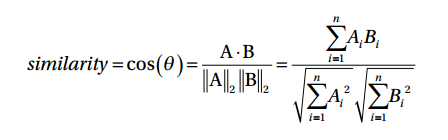
我们按照上表的数据,解释一下公式的使用:
1.A和B是特征向量,例如,A =(1,2,2),B = ( 2 , 4 , 4 )
2.计算A·B:
A·B = (1*2+2*4+2*4)=18
3.计算分母:

4.计算相似性:
18/18 = 1
我们按照给定的公式计算余弦相似性:
1.计算平均评分,并计算对于各个电影评分与平均评分的差:

2.计算向量乘积(A·B)


3.计算各个分量的平方:

4.计算最终结果:

这里需要选定K个用户的评分进行加权平均对未知用户的评分进行预测。
看似Toby与目标用户最为相似,但是他不提供目标电影的评分,所以,我们只能参考其他用户的评分了。
计算评分:
方法一:

方法二:

此问题包含的超参数:
1.与目标用户相似的用户数目确定
2.电影评分参考最佳的部数
3.加权计算的时候采取的方法(采用百分比,还是绝对差值)
算法误差计算(可根据实际进行选择)
1.通过计算所有测试集上的均方误差MSE
2.计算用户在下一次购买商品的时候,购买到的推荐商品的数量