机器学习笔记1-基本概念
机器学习主要包括监督学习、非监督学习、半监督学习和强化学习等。实现方法包括模型、策略、算法三个要素。
- 模型。在监督学习中,模型就是所要学习的条件概率分布或决策函数。
- 策略。策略考虑的是按照什么样的准则学习或选择最优的模型,即选择损失函数。为了防止过拟合,一般会选择正则化的损失函数。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数:
,此处L是损失函数, 是参数向量w的L1范数。 - 算法。算法是指学习模型的具体计算方法,即如何去求解该最优化问题。如梯度下降等算法、最小二乘法等。
在监督学习中,主要包括三类问题:分类问题、标注问题和回归问题。
- 分类问题。当输出变量Y取有限个离散值时,预测问题便成为分类问题。对应的输入变量X可以是离散的,也可以是连续的。很多统计学习方法都可以用于分类,包括k近邻法、感知机、朴素贝叶斯法、决策树、逻辑回归、SVM、提升方法、贝叶斯网络、神经网络等。(这些算法李航《统计学习方法》都有涉及)
- 标注问题。输入变量是一个观测序列,输出变量是标记序列或状态序列。常用的统计学习方法有隐马尔可夫模型和条件随机场。常见的例子有自然语言的词性标注。
- 回归问题。回归用于预测输入变量和输出变量之间的关系。回归问题的学习等价于函数的拟合:选择一条函数曲线使其很好地拟合已知数据且预测未知数据。回归学习最常用的损失函数是平方损失函数,在此情况下,回归问题可以由最小二乘法求解。
为了对学习器的泛化性能进行评估,需要一个测试集,然后以测试误差作为泛化误差的近似。测试集的获取一般包括以下几种方法:
- 留出法:直接将数据集划分为两个互斥的集合,一个作为训练集,一个作为测试集。常见做法是2/3~4/5的样本用于训练,剩余样本用于测试。
- 交叉验证法:将数据集划分为k个大小相同的互斥子集。每次用k-1个子集作为训练集,剩下的作为测试集。这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回这k个测试结果的均值。(在堆栈泛化过程中,交叉验证法返回的结果不是均值,是另外一种组合的形式)当k值等于数据集的样本数m时,即为“留一法”。
- 自助法:对给定m个样本的数据集D,每次从D中选一个样本,拷贝放入D’,然后再将该样本放回D中。重复执行该过程m次,便得到了包含m个样本的数据集D’。(这种做法在随机森林中会用到)自助法会改变初始数据集的分布,这会引入估计偏差。
有了测试集,有了泛化误差后,可将其分解为偏差、方差、噪声之和。偏差度量了算法的预测与真实结果的偏离程度,即刻画了算法本身的拟合能力;方差度量了训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则刻画了当前任务人和算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
补充:
最小二乘法
最小二乘法的核心思想是,通过最小化误差的平方和,使得拟合对象无限接近目标对象。除了“残差平方和最小”这条标准外,还有另外两条标准:
(1) 用“残差和最小”作为标准。但很快发现计算“残差和”存在相互抵消的问题。
(2) 用“残差绝对值和最小”作为标准。但绝对值的计算比较麻烦。
其实从范数的角度考虑这个问题,绝对值和对应的是1范数,平方和对应的就是2范数。从距离角度考虑,绝对值和对应的是曼哈顿距离,平方和对应的就是欧氏距离。假设拟合函数具有如下形式:
(1)
对于方程(1)中的参数向量
,根据其线性形式与非线性形式,最小二乘法又可以分为线性和非线性两种。
- 对于线性最小二乘法,方程(1)可写为:
(2)
令
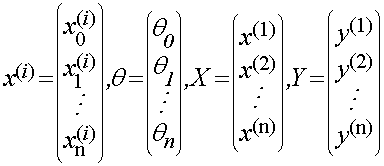
残差函数
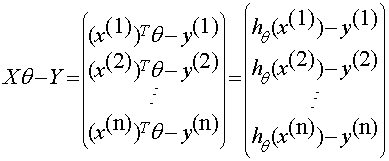
残差和
对 求导,经过一系列推导,可得到
令偏导数为零,可求得极值点
此即为线性最小二乘的解法。 - 对于非线性最小二乘法,通常无法直接写出其导数形式(函数过于复杂),无法找到全局最小值。因此需要通过不断地迭代寻找局部最小值。有两种通用的算法:
- 下降法。通过一个初值,不断地求解下降方向(函数负梯度方向),设置合理的步长,求解得到一些列的中间值,最后收敛到某个局部最小值。(神经网络的后向传输与此相似)
- 高斯牛顿法。该算法的基本思想是将函数 进行一阶泰勒展开 ,其中 为函数的雅克比矩阵,即函数 的一阶导。此时,目标函数展开为 。对其求导并令其为零,可得 ,此方程为关于 的线性方程,称为高斯牛顿方程。这个方程与线性最小二乘法的解有类似的形式。具体的算法步骤包括:1.给点初值;2.对于某次迭代k,求解雅克比矩阵和残差;3.求解增量 ;4.当增量足够小则停止,否则令 。这个算法有个问题,即为了保证求解的 是局部最小值,对应的Hessian矩阵( )需要是正定的。但在实际情况中,Hessian矩阵很有可能是半正定的或者其他情况,因此可能会发生算法不收敛或结果不准确的情况。由于这个缺点,实际优化问题中会更多地使用LM算法(Levenberg-Marquardt Method)。
参考:
李航《统计学习方法》,
周志华《机器学习》,
https://www.cnblogs.com/armysheng/p/3422923.html
https://baijiahao.baidu.com/s?id=1585749800249865895&wfr=spider&for=pc
https://blog.csdn.net/yuxiaoxi21/article/details/71469311
https://blog.csdn.net/wsj998689aa/article/details/41558945
https://www.cnblogs.com/leexiaoming/p/7257198.html