小白 Tensorflow学习笔记(1)
说明:本文及之后的tensorflow学习笔记是学习bilibili tensorflow学习视频后为了方便日后复习所做.记录每次学习内容也会写一些遇到的坑和解决方法,大神自动pass.
tensorflow基本概念:
1, 使用图(graphs)来表示计算任务
2,在会话(Session)的上下文(context)中执行图.
3,使用tensor(张量)表示数据
4,通过变量(Variable)维护状态
5,使用feed和fetch可以为任意的操作赋值,或者从其中获取数据.
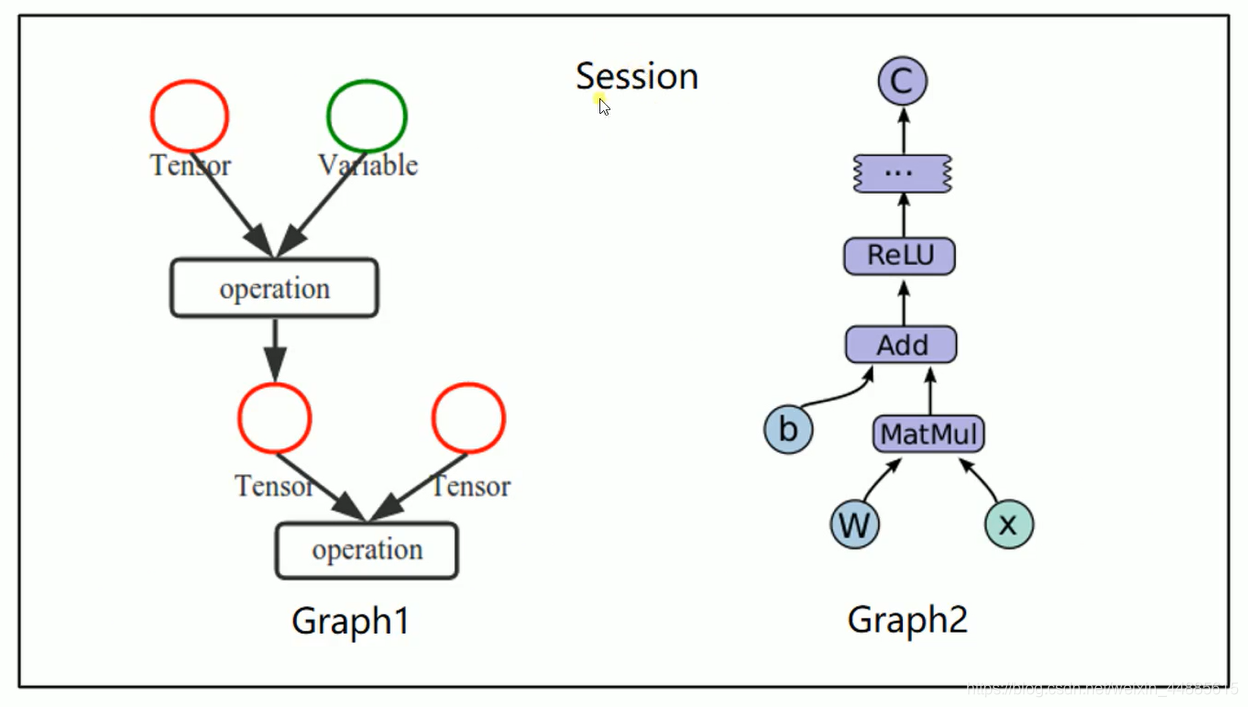
tensorflow是一个编程系统是一个谷歌的深度学习框架,使用graphs来表示计算任务,graphs中的节点称之为(operation),一个op可以获得0个或者多个Tensor来执行计算,产生0个或多个Tensor,Tensor看作是一个n维数组或列表.图必须在会话(Session)里被启动.
copy一下视频中的图.
上代码
import tensorflow as tf
# 创建一个常量op
m1 = tf.constant([[3, 3]])
m2 = tf.constant([[2], [3]])
# 创建一个矩阵乘法op,把m1, m2 传入
product = tf.matmul(m1, m2)
# # 1
# # 定义一个会话,启动默认图
# sess = tf.Session()
# # 调用sess的run方法,来在会话中执行 矩阵乘法op
# # run(product)触发了图中的三个op
# result = sess.run(product)
# print(result)
# sess.close()
# 2
with tf.Session() as sess:
result = sess.run(product)
print(result)
必须加入一个会话,启动tensorflow给我们的默认图,在一般情况下 默认图够我们用了,所有就定义会话即可.
这里还介绍了两种定义会话的方法,通常我们使用第二种方法定义,因为不用关闭会话,在with缩进的范围内执行完内容自动关闭会话.
--------------------------------------------------分割线----------------------------------------
tensorflow中变量的使用:
设置一个变量:
data = tf.Variable(0, name=‘counter’) # 定义一个变量赋初值为0并取名为 counter
设置一个常量
one = tf.constant(1) # 定义一个常量,并赋值为1.
在tensorflow里只要有设置的变量,都要有这一句话:
init = tf.global_variables_initializer() # 初始化所有变量
init = tf.initialize_all_variables() # 或者这句话也行.
但是不是写了这句话就已经初始化了,还要在会话中sess.run(init) run一下这个init才算初始化完成.
后面内容直接上代码了,在注释中有说明一些注意的地方.
"""
变量的使用
"""
# x = tf.Variable([1, 2])
# a = tf.constant([3, 3])
# # 增加一个减法op
# sub = tf.subtract(x, a)
# # 增加一个加法op
# add = tf.add(x, sub)
#
# init = tf.global_variables_initializer() # 初始化所有变量 要使用变量前都要初始化变量 并且要在定义完变量后初始化
#
# with tf.Session() as sess:
# sess.run(init)
# print(sess.run(sub))
# print(sess.run(add))
# """循环变量 使变量自增"""
#
# state = tf.Variable(0, name='counter') # 创建一个变量初始化为0,并且给变量起一个名字为counter
#
# init = tf.global_variables_initializer() # 初始化所有变量 要使用变量前都要初始化变量 并且要在定义完变量后初始化
#
# new_value = tf.add(state, 1)
# update = tf.assign(state, new_value)
# with tf.Session() as sess:
# sess.run(init)
# print(sess.run(state))
# for x in range(5):
# sess.run(update)
# print(sess.run(state))
""" Fetch and Feed"""
# Fetch
# input1 = tf.constant(3)
# input2 = tf.constant(2)
# input3 = tf.constant(5)
#
# # init = tf.global_variables_initializer() # 初始化所有变量 要使用变量前都要初始化变量 并且要在定义完变量后初始化
#
# add = tf.add(input2, input3)
# mu1 = tf.multiply(input1, add)
#
# with tf.Session() as sess:
# result = sess.run([mu1, add])
# print(result)
# # Feed
# # 创建占位符
# input1 = tf.placeholder(tf.float32) # 先不赋值 先占个位置 之后再给他传值
# input2 = tf.placeholder(tf.float32) # 先不赋值 先占个位置 之后再给他传值
# output = tf.multiply(input1, input2)
#
# with tf.Session() as sess:
# # Feed 的数据以字典形式传入
# print(sess.run(output, feed_dict={input1: [8.], input2: [2.]}))
"""
学习
run一下train 会最小化loss ,loss就是y_data-y(误差)的平方值
y_data-y 就会受前面的线性模型影响 所以主要影响loss的因素就k和b,
tensorflow中用优化方法一直改变(训练)k和b的值 会让loss的值越来越小 会让k和b的值越接近0.1和0.2
整体效果就是:让我们定义的梯度模型k和b ,越来越接近样板模型0.1和0.2,每次训练就会更接近一点
"""
# # 使用产生100个随机的点
# x_data = np.random.rand(100)
# y_data = x_data*0.1 + 0.2
#
# # 构造一个线性模型
# b = tf.Variable(0.) # 定义一个初始化值/生成一个随机数
# k = tf.Variable(0.)
# y = k*x_data + b
#
# # 定义一个二次代价函数
# loss = tf.reduce_mean(tf.square(y_data-y)) # (y_data 真实值-预测值 = 误差)平方一下 在求平均值
# # 定义一个梯度下降法--最简单的优化器来进行训练的优化器
# optimizer = tf.train.GradientDescentOptimizer(0.2) # 优化方法 给一个学习率
# # 最小化代价函数
# train = optimizer.minimize(loss) # 目的就是最小化代价函数 loss 越小构造出来的线性模型就越接近真实值
# # 初始化变量
# init = tf.global_variables_initializer() # 初始化所有变量 要使用变量前都要初始化变量 并且要在定义完变量后初始化
# # 定义一个会话
# with tf.Session() as sess:
# sess.run(init) # 所以的变量初始化都要在会话里run一下
# for step in range(201):
# sess.run(train) # 每次迭代都要run一下train
# if step % 20 == 0:
# print(step, sess.run([k, b]))
"""
回归 例子 有错误
"""
# # 使用numpy生成200个随机点
# a = float(-0.5)
# b = float(0.5)
# x_data = np.linspace(a, b, 200)[:, np.newaxis] # 产生200个由-0.5到0.5 均匀分布的点
# noise = np.random.normal(0, 0.02, x_data.shape) # 产生一些干扰项形状和x_data的形状一样
# y_data = np.square(x_data) + noise # 得到一个大致混乱的U的图形 二次函数
#
# # 定义两个placeholder
#
# x = tf.placeholder(tf.float32, [None, 1]) # 行不确定 但是只有一列
# y = tf.placeholder(tf.float32, [None, 1]) # ...
#
# # 构建一个简单的神经网络,输入一个底x_data 会得到一个y_data 希望这个y_data 和真实值很接近即神经网络构建成功
# # 定义神经网络中间层
# weights_L1 = tf.Variable(tf.random_normal([1, 10])) # 得到一个权重 形状是一行十列
# biases_L1 = tf.Variable(tf.zeros([1, 10])) # 有十个神经元
# wx_plus_b_L1 = tf.matmul(x, weights_L1) + biases_L1 # 矩阵乘法 得到信号的总和
# L1 = tf.nn.tanh(wx_plus_b_L1) # 双曲正切函数作用于信号的总和 的到中间层的信号输出
#
# # 定义神经网络输出层
# weights_L2 = tf.Variable(tf.random_normal([10, 1])) # 权重 的形状要做一些改变
# biases_L2 = tf.Variable(tf.zeros([1, 1])) # 输出层只有一个神经元
# wx_plus_b_L2 = tf.matmul(L1, weights_L2) + biases_L2 # 信号的总和
# prediction = tf.nn.tanh(wx_plus_b_L2) # 稽核函数 的到预测结果
#
# # 二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction)) #
# # 使用梯度下降法训练
# train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#
# # 神经网络搭建完 搭建会话
# with tf.Session as sess:
# # 变量初始化
# sess.run(tf.global_variables_initializer())
# for _ in range(2000):
# sess.run(train_step, feed_dict={x: x_data, y: y_data})
# # 获得预测值
# prediction_value = sess.run(prediction, feed_dict={x: x_data})
# # 画图
# plt.figure()
# plt.scatter(x_data, y_data)
# plt.plot(x_data, prediction_value, 'r-', lw=5) # r- 代表画的线是红色的实线
# plt.show()
"""
tensorboard 的使用
"""
a = tf.constant([1.0, 2.0, 3.0], name='input1')
b = tf.Variable(tf.random_uniform([3]), name='input2')
add = tf.add_n([a, b], name='addOP')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter("E:/pictureprocessing/graphs", sess.graph)
print(sess.run(add))
writer.close()
# 用命令提示符打开输入tensorboard --logdir = "E:/pictureprocessing/graphs" --port 6006 在终端会显示一个连接 浏览器进入
# 如果网页进不去的话,关闭wifi试试!!!!!
后记
如果以上代码有错误,有问题,可能会与安装的tensorflow版本有关,现在tensorflow已经出到2.x版本了,有些函数可能出现了变化!
参考文献
bilibili:白夜_叉烧包 深度学习框架Tensorflow学习与应用