文章目录
机器学习的基本概念
机器学习我们可以理解为“构建一个映射函数”,机器学习的大致过程可以理解为,输入一个数据设为x,输出一个标签y,我们的任务的就是去构建这么一个(复杂地)映射函数。大致地数学过程如下:
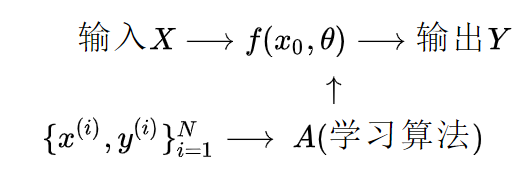
机器学习三要素
我们可以根据机器学习的主要步骤把机器学习分为三个要素,分别是:模型、学习准则、模型优化。
模型
在机器学习中,我们的任务首先需要确定输入空间X和输出空间Y,在机器学习中主要的区别就是在于输出空间Y的不同和其中模型的计算的方法的不同。但是,归根结底就是输出空间的不同。因为又函数的不同,所以最终带来的就是输出空间的不同。
比如,在我们的二分类问题中,输出空间就是
在多分类(或者N(C)分类)中,输出空间就是
在回归问题中,输出空间就是
而,为了让我们的输出空间X和输入空间Y之间存在一种映射关系,所以X与Y之间就存在了一种映射函数,使得X——>Y。主要有以下的两种方式:
而我们建立模型的主要目的就是为了,使我们通过模型的到的Y的值可以更接近真实的Y值。
其中常用的模型主要有以下几种:
线性模型
其中主要包括了权重向量w和偏置向量b,
非线性模型
如果w和b是可学习参数,则就可以说这个函数是神经网路函数。
学习准则
训练集
是由N个独立同分布的样本组成
模型的好坏可以通过期望风险R来衡量,
其中p_r (x,y)为真实的数据分布,L(y,f(x,θ))为损失函数,用来量化两个变量之间的差异。
损失函数
损失函数的的主要作用就是为了衡量模型预测值和真实标签之间的差异。把这种差异具体的量化展示出来。
0-1损失函数
最直观的预测模型的错误率。
平方损失函数
经常用在预测标签y为实数值的任务中。
交叉熵损失函数
一般用于分类问题。
Hinge损失函数
优化
在确定好训练集D和假设空间F以及学习准则之后,我们需要的就是有一个足够好的模型,如何找到一个足够好的模型,就成了一个最优化问题。机器学习的过程其实就是一个寻找最优化的问题。我们需要损失函数的主要目的之一就是为了更好的对模型进行优化。那么我们优化的方法主要以以下几种为主:
梯度下降法
为了充分利用凸优化中一些高效、成熟的优化方法,比如共轭梯度、拟牛顿法等,很多机器学习方法都倾向于选择合适的模型和损失函数以构造一个凸函数作为优化目标(正是因为如此,数学种的“凸优化”也是机器学习的数学基础)。但也有很多模型(比如神经网络)的优化目标是非凸的,只能退而求其次找到局部最优解。
机器学习中,不同算法的的主要区别就是在于模型、学习准则(损失函数)和优化算法。相同的模型也可以有不同的学习算法。比如线性分类模型有感知器、logistic回归和支持向量机,它们之间的差异在于使用了不同的学习准则和优化算法。
在机器学习中,最简单、常用的优化算法就是梯度下降法,即通过迭代的方式计算出训练集D上风险函数的最小值。
其中θ t 为第t次迭代时的参数值,α为搜索步长。在机器学习中,α一般称为学习率(Learning Rate)。
提前停止
在机器学习中经常会出现,因为学习过度而造成的过拟合的现象,或者在相对最优解已经出现,这时我们就可以通过提前停止运行(学习)来达到优化算法的目的。
在我们的输入空间X中包括训练集、验证集、测试集,测试模型在验证集上是否最优。在每次迭代时,把新得到的模型f(x,θ)在验证集上进行测试,并计算错误率。如果在验证集上的错误率不再下降,就停止迭代。这种策略叫提前停止。
随机梯度下降法
批量梯度下降法在每次迭代时需要计算每个样本上损失函数的梯度并求和。当训练集中的样本数量N 很大时,空间复杂度比较高,每次迭代的计算开销也很大。为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只
采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法。
为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法(Stochastic Gradient Descent,SGD)。当经过足够次数的迭代时,随机梯度下降也可以收敛到局部最优解。
总结
的计算复杂度,我们也可以在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法(Stochastic Gradient Descent,SGD)。当经过足够次数的迭代时,随机梯度下降也可以收敛到局部最优解。
总结
在本文中主要讲解了机器学习的基础知识、对机器学习的大致过程进行了一个讲解,在后面的部分会逐个仔细讲解。