HDFS简介
HDFS 源于 Google 在2003年10月份发表的GFS(Google File System) 论文。 是 GFS 的一个克隆版本
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
HDFS存储数据的优缺点
HDFS的优点
- 高容错性
- 数据自动保存多个副本。通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。
- 适合批处理
- 通过移动计算而不是移动数据。
- 它会把数据位置暴露给计算框架。
- 适合大数据处理
- 处理数据达到 GB、TB、甚至PB级别的数据。
- 能够处理百万规模以上的文件数量,数量相当之大。
- 能够处理10K节点的规模。
- 流式文件访问
- 一次写入,多次读取。
- 文件一旦写入不能修改,只能追加。
- 能保证数据的一致性。
- 可构建在廉价机器上
- 通过多副本机制,提高可靠性。
- 提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
HDFS的缺点
- 无法低延时数据访问
- 无法毫秒级的来存储数据。
- 适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据
- 不适合小文件存储
- 存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
- 小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
- 不支持并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写。
- 仅支持数据 append(追加),不支持文件的随机修改
以上内容来自:https://www.cnblogs.com/codeOfLife/p/5375120.html
HDFS架构
集群架构
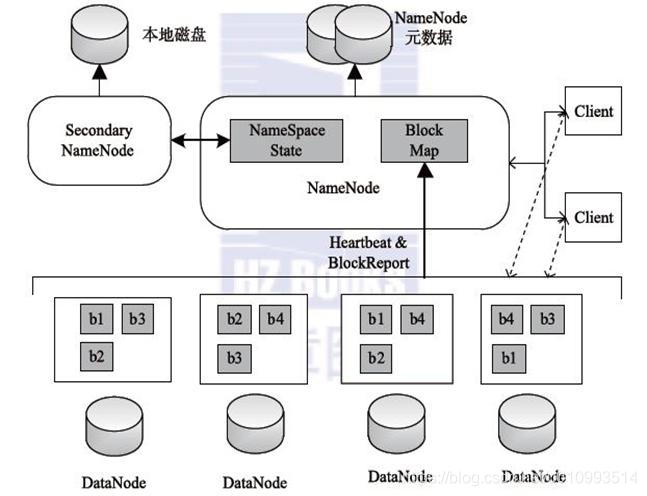
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。这里重点介绍Secondary NameNode,其他架构部分参考下文高可用集群架构
Secondary NameNode
并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务
SecondaryNameNode的工作情况:
SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
此处内容来自:https://blog.csdn.net/xjz729827161/article/details/79463140
高可用集群架构
- HDFS HA(High Availability)是为了解决单点故障问题
- HA集群设置两个名称节点,“活跃(Active)”和“待命(Standby)”
- 两种名称节点的状态同步,可以借助于一个共享存储系统来实现
- 一旦活跃名称节点出现故障,就可以立即切换到待命名称节点
- Zookeeper确保一个名称节点在对外服务
- 名称节点维护映射信息,数据节点同时向两个名称节点汇报信息
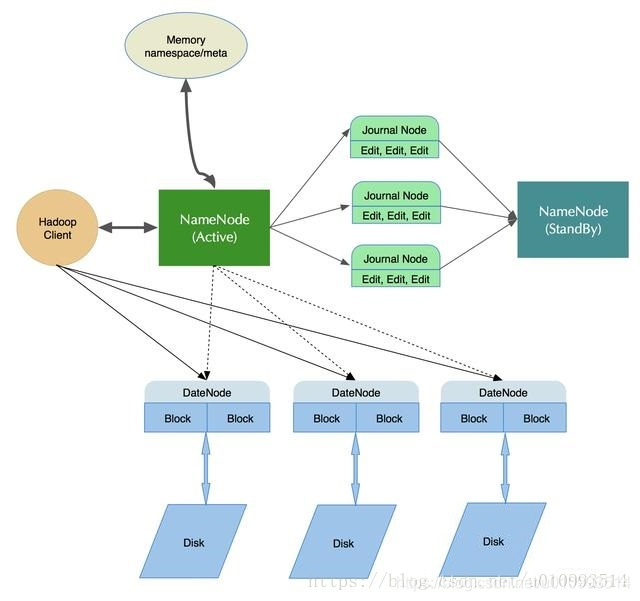
- 主Master,整个Hadoop集群只能有一个
-
管理HDFS文件系统的命名空间
-
维护元数据信息
-
管理副本的配置和信息(默认三个副本)
-
处理客户端读写请求
- Standby Name Node
-
Active Name Node的热备节点
-
Active Name Node故障时可快速切换成新的Active Name Node
-
周期性同步edits编辑日志,定期合并fsimage与edits到本地磁盘
- Journal Node
-
可以被Active Name Node和StandBy Name Node同时访问,用以支持Active Name Node高可用
-
Active Name Node在文件系统被修改时,会向Journal Node写入操作日志(edits)
-
Standby Name Node同步Journal Node edits日志,使集群中的更新操作可以被共享和同步。
- Data Node
-
Slave 工作节点,集群一般会启动多个
-
负责存储数据块和数据块校验
-
执行客户端的读写请求
-
通过心跳机制定期向NameNode汇报运行状态和本地所有块的列表信息
-
在集群启动时DataNode项NameNode提供存储Block块的列表信息
- Block数据块
-
HDSF固定的最小的存储单元(默认128M,可配置修改)
-
写入到HDFS的文件会被切分成Block数据块(若文件大小小于数据块大小,则不会占用整个数据块)
-
默认配置下,每个block有三个副本
- Client
-
与Name Node交互获取文件的元数据信息
-
与Data Node,读取或者写入数据
-
通过客户端可以管理HDFS
更多详情见:https://blog.csdn.net/u010993514/article/details/83009822
HDFS副本存放策略
namenode如何选择在哪个datanode 存储副本(replication)?这里需要对可靠性、写入带宽和读取带宽进行权衡。Hadoop对datanode存储副本有自己的副本策略,在其发展过程中一共有两个版本的副本策略,分别如下所示
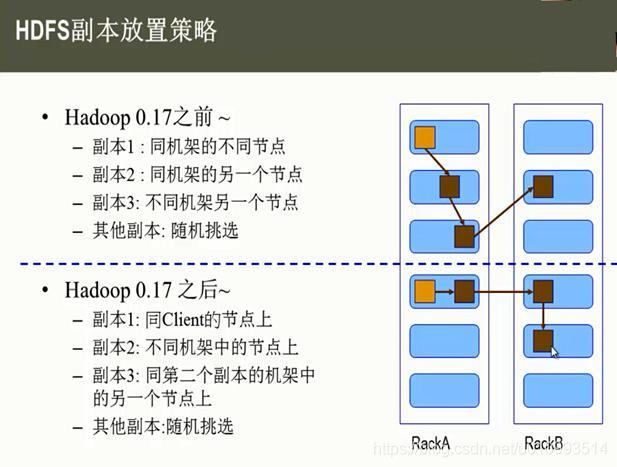
此处内容来自:https://www.cnblogs.com/codeOfLife/p/5375120.html
Hadoop2.x新特性
- 引入了NameNode Federation,解决了横向内存扩展
- 引入了Namenode HA,解决了namenode单点故障
- 引入了YARN,负责资源管理和调度
- 增加了ResourceManager HA解决了ResourceManager单点故障