在上采样的情况下,可能需要注意如何使用插值来计算细粒度的观测值
在向下采样的情况下,在选择用于计算新聚合值的汇总统计信息时可能需要小心。
也许有两个主要原因让你对重新采样你的时间序列数据感兴趣:
1.问题框架:如果您的数据与您希望进行预测的频率相同,则可能需要重新采样。
2.特征工程:重采样还可以用于为监督学习模型提供额外的结构或洞察学习问题。
这两种情况有很多重合之处。例如,您可能有每日数据,并希望预测每月的问题。您可以直接使用每日数据,也可以将其下采样为每月数据,并开发您的模型。
https://machinelearningmastery.com/resample-interpolate-time-series-data-python/
上采样:
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
print(series.head())
series.plot()
pyplot.show()数据如下:
Month
1901-01-01 266.0
1901-02-01 145.9
1901-03-01 183.1
1901-04-01 119.3
1901-05-01 180.3
Name: Sales of shampoo over a three year period, dtype: float64
也就是我们现在有月度的数据,想变成日度的数据
首先进行格式转换
from pandas import read_csv
from pandas import datetime
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
upsampled = series.resample('D')
print(upsampled.head(32))这里D代表day,搞完之后变这样
Month
1901-01-01 266.0
1901-01-02 NaN
1901-01-03 NaN
1901-01-04 NaN
1901-01-05 NaN
1901-01-06 NaN
1901-01-07 NaN
1901-01-08 NaN
1901-01-09 NaN
1901-01-10 NaN
1901-01-11 NaN
1901-01-12 NaN
1901-01-13 NaN
1901-01-14 NaN
1901-01-15 NaN
1901-01-16 NaN
1901-01-17 NaN
1901-01-18 NaN
1901-01-19 NaN
1901-01-20 NaN
1901-01-21 NaN
1901-01-22 NaN
1901-01-23 NaN
1901-01-24 NaN
1901-01-25 NaN
1901-01-26 NaN
1901-01-27 NaN
1901-01-28 NaN
1901-01-29 NaN
1901-01-30 NaN
1901-01-31 NaN
1901-02-01 145.9
现在占了位置之后就可以进行插值了,方法有很多,比如线性,多项式,spline等等
from pandas import read_csv
from pandas import datetime
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
upsampled = series.resample('D')
interpolated = upsampled.interpolate(method='linear')
print(interpolated.head(32))效果图如下:
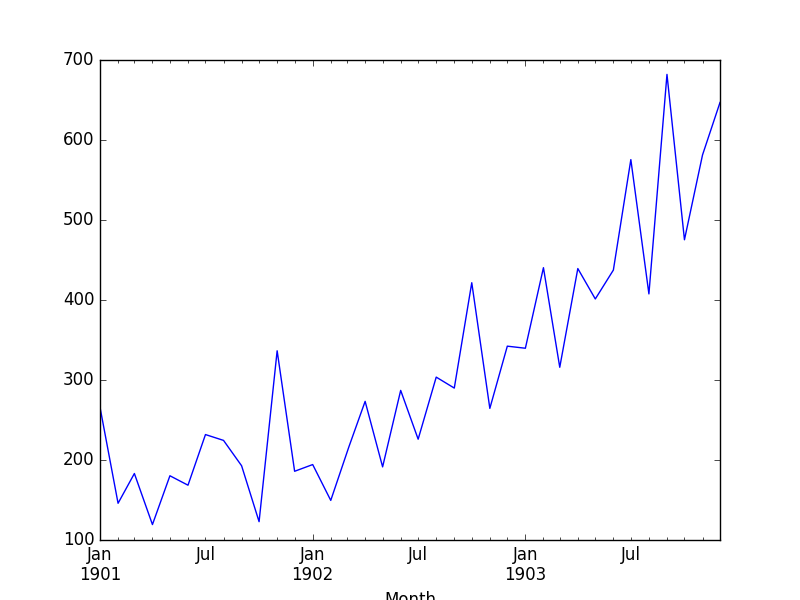
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
upsampled = series.resample('D')
interpolated = upsampled.interpolate(method='spline', order=2)
print(interpolated.head(32))
interpolated.plot()
pyplot.show()效果图如下:
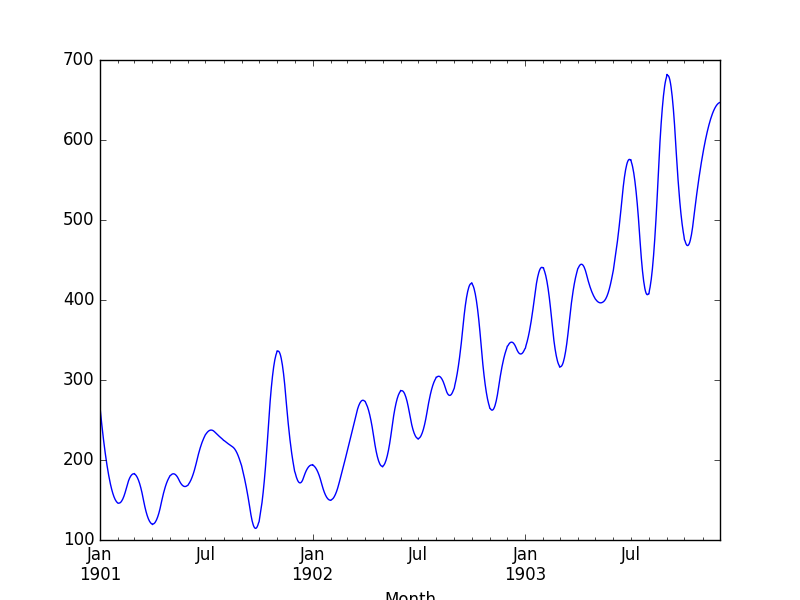
下采样:我们有月度数据,现在想要季度数据
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
resample = series.resample('Q')
quarterly_mean_sales = resample.mean()
print(quarterly_mean_sales.head())
quarterly_mean_sales.plot()
pyplot.show()Q代表季度,mean()代表几个月份的均值去代替
Month
1901-03-31 198.333333
1901-06-30 156.033333
1901-09-30 216.366667
1901-12-31 215.100000
1902-03-31 184.633333
Freq: Q-DEC, Name: Sales, dtype: float64
当然你也可以用年份的,这里用sum
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
resample = series.resample('A')
quarterly_mean_sales = resample.sum()
print(quarterly_mean_sales.head())
quarterly_mean_sales.plot()
pyplot.show()更多细节:
1.http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.resample.html
2.http://pandas.pydata.org/pandas-docs/stable/timeseries.html#resampling
3.http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.interpolate.html