版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012848709/article/details/85145062
楔子
Hadoop 3 高可用搭建记录
1 zookeeper集群
zoo.cfg 文件配置数据文件位置等信息
#其他使用默认
dataDir=/opt/data/zk
server.1=had2:2888:3888
server.2=had3:2888:3888
server.3=had4:2888:3888
分发到其他机器
scp -r zookeeper-3.4.6/ had4:`pwd`
# 使用`pwd` 会把 文件发送到其他机器的相同位置
dataDir目录 放置id
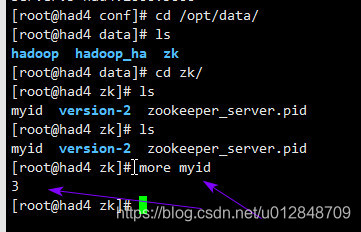
zkServer.sh start 启动(我配置了环境变量)
2 Hadoop配置文件
需要的都可以参考 官方文档
2.1 hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
#export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
2.2 hdfs-site.xml
<configuration>
<!--文件副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>had1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>had2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>had1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>had2:9870</value>
</property>
<!-- JNN节点配置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://had1:8485;had2:8485;had3:8485/mycluster</value>
</property>
<!-- 故障转移代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/hadoopha/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
2.3 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop_ha</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>had2:2181,had3:2181,had4:2181</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
3 启动集群
# 1 启动JournalNode守护程序(在各个机器依次启动)
hdfs --daemon start journalnode
# 2 应首先在其中一个NameNode上运行format命令(hdfs namenode -format)
hdfs namenode -format
# 2_2 格式化后继续在本机器启动namenode
hdfs --daemon start namenode
# 3 应该通过运行命令将NameNode元数据目录的内容复制到其他未格式化的NameNode上
hdfs namenode -bootstrapStandby
3.2 在ZooKeeper中初始化HA状态
在ZooKeeper中初始化所需的状态。可以通过从其中
一个NameNode主机运行以下命令来执行此操作。
hdfs zkfc -formatZK

3.3 启动集群
使用start-dfs.sh启动集群
由于配置中已启用自动故障转移,因此start-dfs.sh脚本现在将在运行NameNode的任何计算机上自动启动ZKFC守护程序。当ZKFC启动时,它们将自动选择其中一个NameNode变为活动状态。
start-dfs.sh