之前我有一篇文章《YouTube视频爬虫-批量采集-低成本解决方案-技术难点和细节回顾》 提到过一种u2b视频采集的方案。该方法适用于针对特定的up主进行批量采集,成本确实挺低,速度也蛮好。之前曾在博客下方挂出邮箱地址,寻求技术交流,但是被很多伸手党给打扰,在这里我只想坚决地告诉诸位:给代码是不可能的,我相信思路对你们才是更重要滴。
背景:
1.腾讯云的非香港地区海外服务器均很难连接
2.某些香港地区的服务器也很难连接
3.我们需要根据关键字进行u2b视频采集,用以支撑我们自己开发的视频编辑器的本地素材库
针对上述背景,初步意见:
1.腾讯云如果做视频采集只能用香港的服务器了
2.香港地区的某些服务器无法连接,我目前推测的原因是恰好你使用的ip被禁,你需要绑定弹性ip,更换ip地址,直到换到内地可用ip
3.针对关键字的视频采集,还在想着用爬虫吗?千万别走弯路啊!Google开放了 YouTube Data api ,直接可以拿到结果。
整体思路
1.Rest API:部署在香港服务器,转发YouTube Data api查询结果
2.GUI:运行在使用者电脑,用于用户采集操作,用户根据关键字获取待采集任务列表
3.采集器:运行在香港服务器,依然使用我们的youtube-dl
4.采集完成之后,推到同区的腾讯云对象存储-香港区
5.本地下载器,运行在使用者电脑,用于从腾讯云对象存储下载视频到本地
价格计算

经过计算,每天下载15分钟内的视频200个,每月的运行成本是300多。114元买到1C1G2M的香港服务器,每天的采集极限是160GB
YouTube Data API 开发文档传送门
关于YouTube Data api我有话要讲
在之前的文章中有提到,当时走了弯路去看 youtube-api ,结果发现并没有什么卵用,这次呢?可是沾了光,不走弯路,直达目的地啦~
YouTube API中的Search/list接口,可以直接根据关键字获取符合条件的vedio、channel、playlist,下面是官方给出的demo
# Sample python code for search.list
def search_list_by_keyword(client, **kwargs):
# See full sample for function
kwargs = remove_empty_kwargs(**kwargs)
response = client.search().list(
**kwargs
).execute()
return print_response(response)
search_list_by_keyword(client,
part='snippet',
maxResults=25,
q='surfing',
type='')
其实筛选条件有很多的,甚至具体到结果排序方式都可以配置。
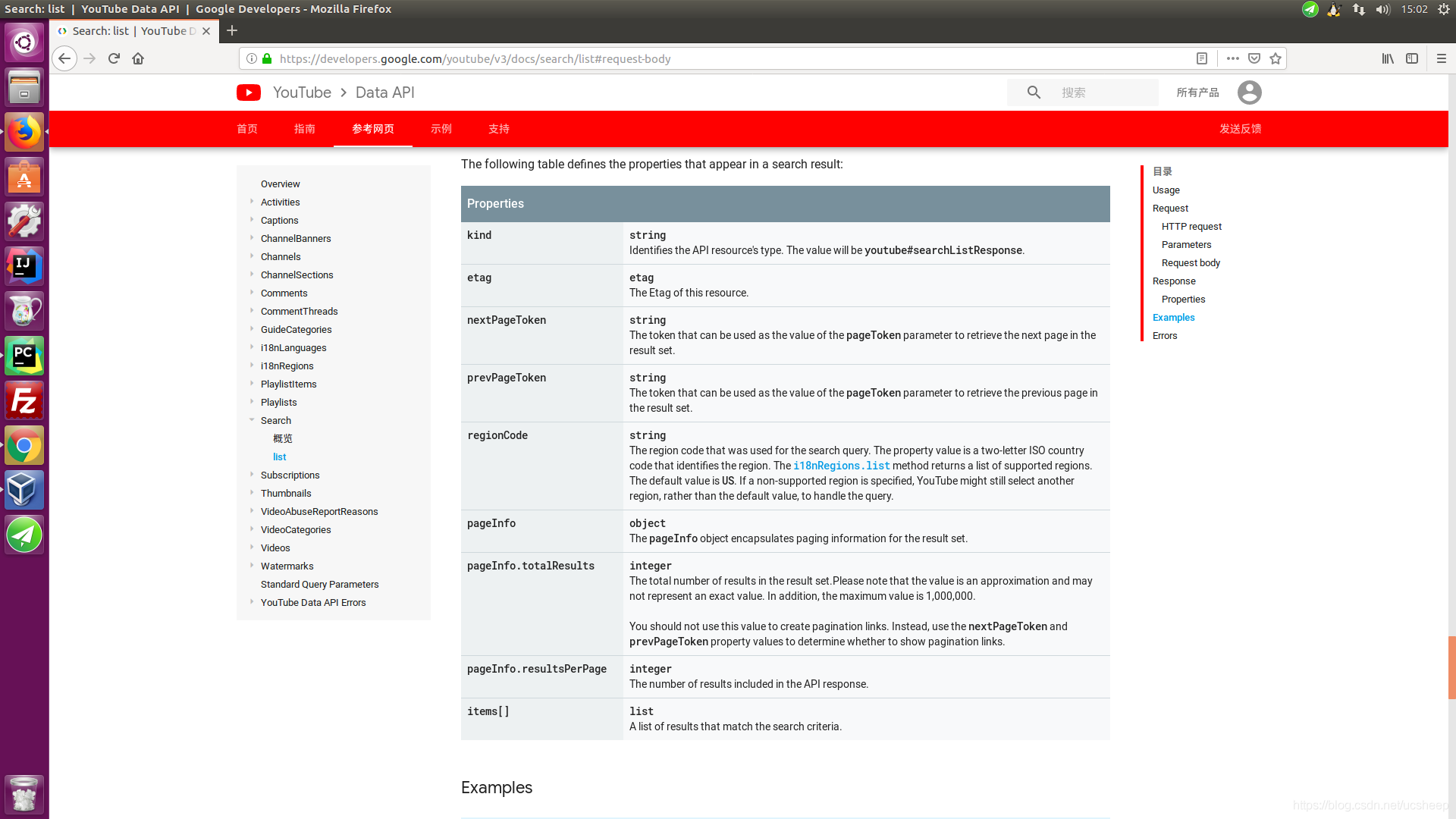
返回
{
"kind": "youtube#searchListResponse",
"etag": etag,
"nextPageToken": string,
"prevPageToken": string,
"regionCode": string,
"pageInfo": {
"totalResults": integer,
"resultsPerPage": integer
},
"items": [
search Resource
]
}