RDD
RDD全称是Resilient Distributed Dataset ,弹性分布式数据集
1.五个特性
A list of partitions
A function for computing each partition
A list of dependencies on other RDDs
Optionally, a Partitioner for key-value RDDs
Optionally, a list of preferred locations to compute each split on
RDD是由一系列的partition组成
RDD提供的每一个函数实际上作用在每一个partition上
RDD是有一系列的依赖关系,依赖于其他的RDD
可选项 分区器是作用在KV格式的RDD上的
可选项 RDD会提供一系列的最佳的计算位置
RDD依赖关系又被称为血统(Lineage)
RDD五大特性的解析
Q:RDD依赖关系的作用
A:提高了计算的容错性。因为RDD的依赖关系,子RDD知道父RDD是谁,但是父RDD不知道子RDD是谁。如果子RDD数据出错或丢失,子RDD可以基于它的父RDD重新计算获得数据。
Q:分区器的作用?
A:决定数据被哪一个reduce task处理
Q:KV格式的RDD是那种数据类型?
A:如果RDD中的数据是二元组类型的,那么我们就称这个RDD是KV格式的RDD。
Q:RDD如何提供最佳的计算位置?
A:RDD会提供一个方法接口,直接调用这个方法,就能拿到这个RDD的所有partition的位置。
Q:RDD存储的是数据吗?
A:这么问的一看就是xx,肯定不是啊。RDD存储的是计算逻辑,与数据库中的视图类似,只有触发的时候才会处理数据。
Q:RDD是通过什么从HDFS上读取数据的?
A:RDD本身并没有读取数据的方法,RDD依赖的是MR读文件的方法,MR在读文件之前,会先将文件划分成一个个split。正常情况下,split与block存在下列关系:
split size == block size
block num ≈ split num
split num == 第一个RDD的分区数
如果某一个block文件存储的数据是上一个block块最后一条信息的半条信息,会出现特殊情况,导致split num ≠ block num,大多数情况下split num == block num。
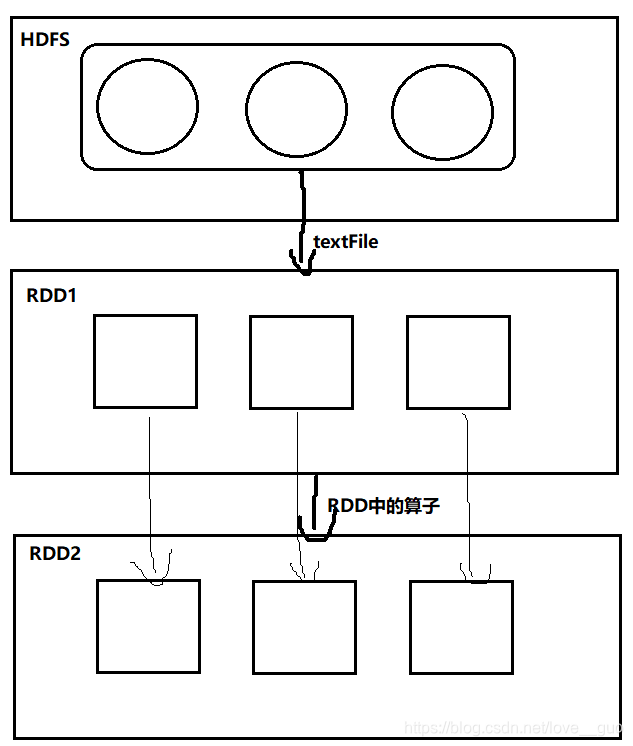
RDD算子
RDD中提供了大量的函数,我们也称之为算子。算子分为两大类:transformations(延迟执行)、action(触发执行)
1.transformations类算子
transformation类算子是懒执行的,当遇到action类算子的时候才会触发执行。
transformation类算子的一大特点是:算子的返回值还是RDD类型的
| 算子 | 使用 | 说明 |
|---|---|---|
| map | map (f: T => U) : RDD[U] | 输入一行输出一行 |
| flatmap | flatMap(f: T =>TraversableOnce[U]): RDD[U] | 将函数f作用在RDD中每个元素上,并展开(flatten),输出的每个结果 |
| mapPartitions | mapPartitions[U](f: Iterator[Int] => Iterator[U], preservesPartitioning: Boolean): RDD[U] | 获 取 到 每 个 分 区 的 迭 代器,在 函 数 中 通 过 这 个 分 区 整 体 的 迭 代 器 对整 个 分 区 的 元 素 进 行 操 作 |
| mapValues | mapValues[U](f: Int => U): RDD[(String, U)] | 针对(Key, Value)型数据中的 Value 进行 Map 操作 |
| filter | filter(f: T => Boolean):RDD[T] | f定义了类型为T的元素是否留下,过滤输入RDD中的元素,将f返回true的元素留下 |
| coalesce | coalesce(numPartitions: Int,b:boolean) : RDD[T] | 重新分区,分区变多一定会发生shuffle |
| repartition | repartition(numPartitions: Int) :RDD[T] | 重新分区,是coalesce(numPartitons, true) 的简写 |
| reduceByKey | reduceByKey(func: (V, V) => V): RDD[(K, V)] | reduceByKey()对key相同的value进行计算 |
| groupByKey | groupByKey(): RDD[(String, Iterable[Int])] | 将RDD[key,value] 按照相同的key进行分组,形成RDD[key,Iterable[value]]的形式 |
| union | RDD.union(RDD) | 将多个RDD合并为一个RDD |
| zip | RDD.zip(RDD) | 将两个RDD组合成Key/Value形式的RDD,如果两个rdd中的partition数量不一致,会报错 |
| zipWithUniqueId | zipWithUniqueId(): RDD[(Int, Long)] | 给RDD中的每一个元素加上一个唯一的索引号,非KV的RDD变成了KV格式的RDD |
| zipWitIndex | zipWithIndex(): RDD[(Int, Long)] | 给RDD中的每一个元素加上一个唯一的索引号,非KV的RDD变成了KV格式的RDD |
| join | RDD.join(RDD) | 返回两个RDD根据K可以关联上的结果,join只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
| distinct | distinct() | 将RDD中的元素进行去重操作 |
| combineByKey | combineByKey[C](createCombiner: Int => C, mergeValue: (C, Int) => C, mergeCombiners: (C, C) => C): RDD[(String, C)] | 和reduceByKey是相同的效果,是reduceByKey的底层 |
| sortByKey | sortByKey(ascending: Boolean, numPartitions: Int): RDD[(String, Int)] | 根据key来排序 |
| sortBy | sortBy(f: ((String, Int)) => K, ascending: Boolean, numPartitions: Int): RDD[(String, Int)] | 指定根据哪一个字段来排序 |
2.action类算子
当程序执行时,遇到action类算子,会触发执行,与前面的transformation类算子一起执行。
| 算子 | 使用 | 说明 |
|---|---|---|
| collect | collect(): Array[T] | 将数据拉回到drive端,此算子慎用! |
| take | take(num: Int): Array[T] | 返回RDD的前num个元素 |
| count | count(): Long | 统计RDD中元素个数 |
| foreach | foreach(f: T => Unit):Unit | 对RDD中每个元素,调用函数f |
| saveAsTextFile | saveAsTextFile(path) | 函数将数据输出,存储到指定目录 |
| reduce | reduce(f: (T, T) => T): T | 按照函数f对RDD中元素,进行规约 |
3.控制类算子
将数据落地,存储再内存或磁盘上。
| 算子 | 使用 | 说明 |
|---|---|---|
| cache | chche () | 将RDD的数据持久化到内存中。cache是懒执行。相当于persist(StorageLevel.Memory_Only) |
| persist | persist(level) | 指定持久化级别,可选择内存、磁盘、持久化、备份 |