理解OpenShift(1):网络之 Router 和 Route
理解OpenShift(5):从 Docker Volume 到 OpenShift Persistent Volume
理解OpenShift(7):基于 Prometheus 的集群监控
** 本文基于 OpenShift 3.11,Kubernetes 1.11 进行测试 ***
和日志系统一样,监控系统也是平台一大不可或缺的组成部分。在敏态的OpenShift 和 Kubernetes 平台之中,运行平台组件及业务应用的Pod 时刻都处于变化之中,而且数量可能会巨大。在这种情况下,对监控系统的要求会更高。当前,基于 Prometheus 和 Granfana 的监控系统,对于OpenShfit 和 Kubernetes 这样的平台来说,是一个比较好的选择。但是,Prometheus 本身就相当复杂,再加上复杂的容器云平台,复杂性成倍提高。本文试着对它的原理进行梳理,但肯定无法面面俱到。更多更详细的信息,还请查阅更多资料。
1. Prometheus 概述
关于 Prometheus 的文档非常多,这里不会详细说明,只是一个概述。
它是什么:
- 一个带时序数据库(TSDB)的监控系统。SoundCloud 在2012年开始开发,2015年开源,现在是 CNCF 继 Kuebernetes 之后的第二个项目。
- 通过拉取(pull)方式收集测量数据,并将其保存在TSDB 中。
- 提供策略数据查询功能,实现了 PromSQL 类似于 SQL 的查询语法
- 提供告警功能,能根据定义好的告警规则向外输出告警
- 虽然它自己实现了一个面板,但是现在主流的做法是将它和 Grafana 结合,由 Grafana 提供面板
- 它不处理日志或跟踪(tracing),只处理策略数据
- 它本身不是专门的具有良好扩展性的持久存储。它自身的存储,被设计为用于短时间保存数据。
它的基本架构:

关于架构的简单说明:
- 左侧是被监控的静态对象(target)。如果监控对象自身提供满足Prometheus要求的测量数据的 HTTP API(比如cAdvisor,https://github.com/google/cadvisor),则可以直接和 Prometheus 对接;否则,可以借助 exporter 来实现对接(比如 node exporter)。exporter 会从应用中获取测量数据,然后提供HTTP API,再和 Prometheus 对接。
- 中下部分是 Prometheus。它的开源项目地址是 https://github.com/prometheus。它是监控系统的中心,负责策略数据收集、存储、告警、查询等。
- 中上部分是服务发现,用于动态对象的监控。在很多现代系统中,被监控对象不是静态的,比如 K8S 中的Pod。对于动态的目标,按照静态目标那种监控方式就很难了,所有Prometheus 提供了服务发现功能。它能动态地发现被监控的对象,然后对它们做监控。
- 右上是 AlertManager。其开源项目地址是 https://github.com/prometheus/alertmanager。它接受 Prometheus 根据所配置的告警规则而发过来的告警,然后做去重、分组和路由等处理,然后发给外部的接口组件,比如 PageDuty、邮件系统等。
- 右下是 Grafana。其开源项目地址是 https://github.com/grafana/grafana。它以Prometheus 为一种后端(它支持对接很多种后端),根据配置,从中获取数据,然后以非常漂亮的界面(Dashboard)将数据呈现出来。
网上有很多很多的关于 Prometheus 的文档,比如 https://yunlzheng.gitbook.io/prometheus-book/ 。
2. 利用 Prometheus 对 OpenShfit 集群进行监控
2.1 OpenShfit 集群的监控需求
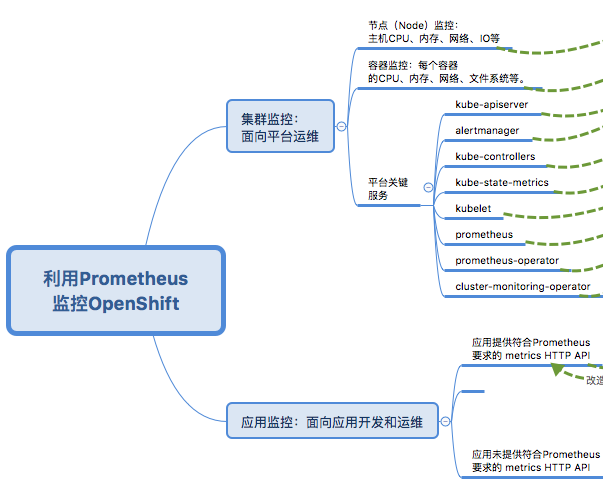
上图整理了OpenShift 集群的监控需求。它包括两大部分:
- 一部分是对OpenShift 平台进行监控,确保它稳定运行。这是平台运维团队的需求。这部分又包括很多内容,包括节点监控(节点的CPU、内存、网络、存储等)、容器监控(每个容器所消耗的资源,包括cpu、内存、网络、文件系统等),以及 OpenShift 核心组件。
- 另一部分是运行在OpenShfit 平台上的业务服务,确保业务服务稳定运行,这是应用开发和运维团队的需求。
2.2 基于 Prometheus 的 OpenShift 监控系统的实现
为了满足上述监控需求,OpenShift 提供了基于 Prometheus + Grafana 的监控系统。针对每个需要被监控的目标(target),都利用了Prometheus提供的某个功能来实现对它的监控。
先上一张官方的架构图:

我细化一些的逻辑图:
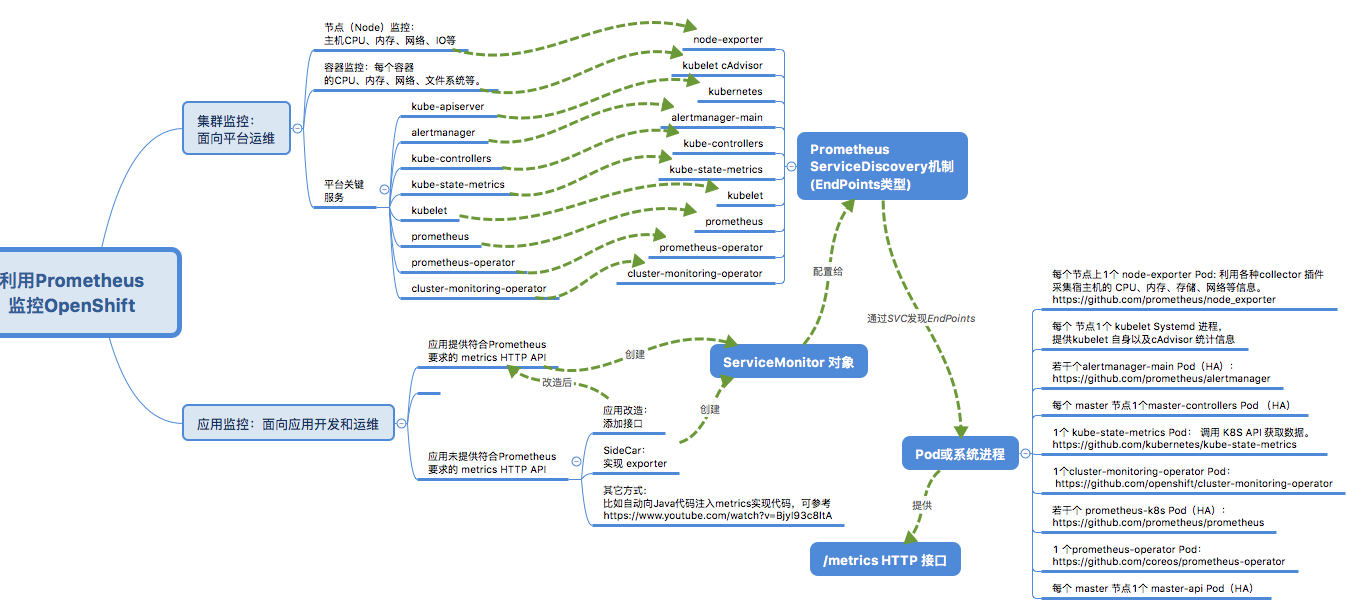
具体每个部分在后文会有相关介绍。
2.3 基于 Prometheus 的 OpenShift 监控系统的部署和维护
OpenShfit 利用 ansible 在某个project(我的是 openshift-monitoring)中部署监控系统,包括 Prometheus 和 Granfana。这里面主要用到两个开源项目:
- 一个是 Cluster Monitoring Operator。它的开源项目地址是 https://github.com/openshift/cluster-monitoring-operator。它负责在 OpenShfit 环境中部署基于 Prometheus 的监控系统。
- 另一个是 Prometheus Operator。 它的开源项目地址是 https://github.com/coreos/prometheus-operator。它负责在 Kubernetes 环境中部署基于 Prometheus 的监控系统。
关于这两个 Operator 的更多信息,请查阅有关文档。下面只介绍某些重点部分。
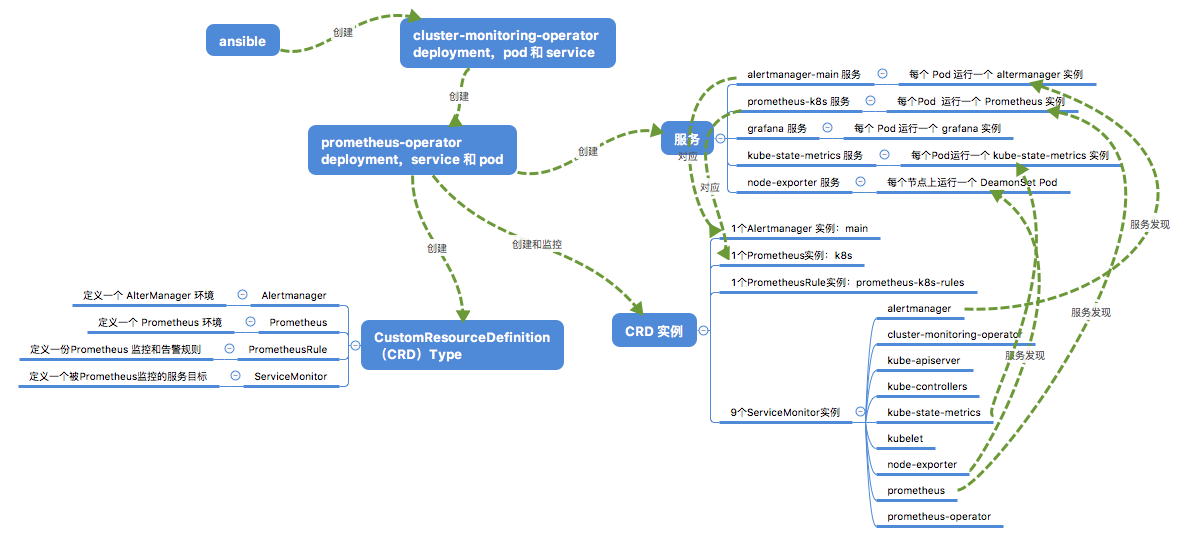
Cluster Monitoring Operator 只是很薄的一层,但是它是入口。它的主要任务是负责把 Prometheus Operator 创建出来。
Prometheus Operator 是 CoreOS 开源的项目,它就很复杂了。以下图为参照,它创建出来三种东西:
- 第一种是 Prometheus 及相关的服务。默认包括 alertmanager 服务、Prometheus 服务、Grafana 服务、kube-state-metrics 服务、node-exporter 服务。
- 第二种是它创建了4个 CRD 类型(实际上有6个,但另两个的用途不明),包括 AlterManager,Prometheus、PrometheusRule 和 ServiceMonitor。
- 每一个 CRD 都是类似 Deployment 的一个配置,从名字上可以看出与实体的对应关系。
- Prometheus Operator 会监控这些实例。如果发现有更改,则会对相应的实体做变更。比如若 PrometheusRule 的内容被修改,那么新的监控和告警规则会被 Prometheus 重新加载。
- 因此,定义这些 CRD 类型的目的,是为了简化对 Prometheus 系统的管理。管理员只需要对这些 CRD 实例做管理,系统就会自动对实例做变更。
- 第三类是这四个 CRD 的一些实例。在部署监控系统时,若干个实例会被自动创建出来,对应第一种里面的那些服务。
- 1 个 alertmanager 实例对应 alertmanager 服务,每个服务默认3 个副本,也就是有3个 Pod。
- 1 个 Prometheus 实例对应 Prometheus 服务,每个服务默认2个副本,也就是有2个 Pod。
- 1 个 PrometheusRule 实例对应当前 Prometheus 实例所使用的监控和告警规则。
- 9 个 ServiceMonitor 实例,对应对 Prometheus 所监控的9个目标,这里的每个目标都是一个 OpenShift 服务。下面会详细说明。
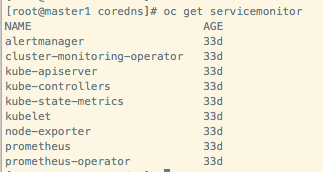
2.4 ServiceMonitor 实例
ServiceMonitor 是 Prometheus Operator 向运维人员暴露出来的被监控的目标。在部署完成后,默认创建了9个 ServiceMonitor 对象,对应9个需要被 Prometheus 监控的核心服务:
2.4.1 alertmanager

AlterManager 是一个 Prometheus 套件中的独立组件,它自身实现了符合 Prometheus 要求的计量信息接口。
2.4.2 cluster-monitoring-operator

这是 OpenShift cluster monitoring opeator 服务。它也实现了计量接口。其中的代码示例如下:
2.4.3 kube-apiserver
这是 OpenShift 的 API 和 DSN 服务。

2.4.4 kube-controllers
这是 K8S master controllers 服务。

2.4.5 kube-state-metrics
这是一个开源项目,地址在 https://github.com/kubernetes/kube-state-metrics。它从 K8S API Server 中获取数据,比如:
ksm_resources_per_scrape{resource="node",quantile="0.99"} 7
ksm_resources_per_scrape_sum{resource="node"} 255444
ksm_resources_per_scrape_count{resource="node"} 36492
ksm_resources_per_scrape{resource="persistentvolume",quantile="0.5"} 15
ksm_resources_per_scrape{resource="persistentvolume",quantile="0.9"} 15

2.4.6 kubelet
kubelet 服务包含多个Static Pod,每个Pod在集群的每个节点上。它除了自身提供 kublet 的计量信息外,还内置了 cAdvisor 服务,因此也提供 cAdvisor 信息。 cAdvisor 对 Node机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,cAdvisor集成在Kubelet中,当kubelet启动时会自动启动cAdvisor,即一个cAdvisor仅对一台Node机器进行监控。

2.4.7 node-exporter

2.4.8 prometheus
这是 Prometheus 服务,它可有多个 StatefulSet Pod,每个 Pod 中运行一个 Prometheus 进程。

2.4.9 prometheus-operator
这是 Prometheus Operator 服务,只有一个pod。

2.5 基于OpenShift ServiceMonitor 和 Prometheus Service Discovery(服务发现)的监控的实现
Prometheus Pod 中,除了 Prometheus 容器外,还有一个 prometheus-config-reloader 容器。它负责导入Prometheus 配置文件。配置文件被以 Secret 形式挂载给 prometheus-config-reloader Pod。一旦配置有变化,它会调用 Prometheus 的接口,使其重新加载配置文件。
配置文件中定义了被监控的目标为这些 ServiceMonitor 对象所对应的服务:

每个 job 都采用 endpoints 类型的 Prometheus 服务发现机制。也就是说,Prometheus 会调用 OpenShift 的API,首先找到每个 job 所配置的 OpenShift 服务,然后找到这服务的端点(endpoint)。每个 OpenShfit endpoint 是一个 Prometheus target(目标),可以在 Prometheus 界面上看到目标列表。然后在每个目标上,调用 metrics HTTP API,以拉取(GET)形式,获得该服务的计量数据。

3. 利用 Prometheus 对部署在 OpenShift 平台上的应用进行监控
3.1 技术实现
3.1.1 监控框架总结
把前面的内容再总结一下,得出下面的监控框架图:
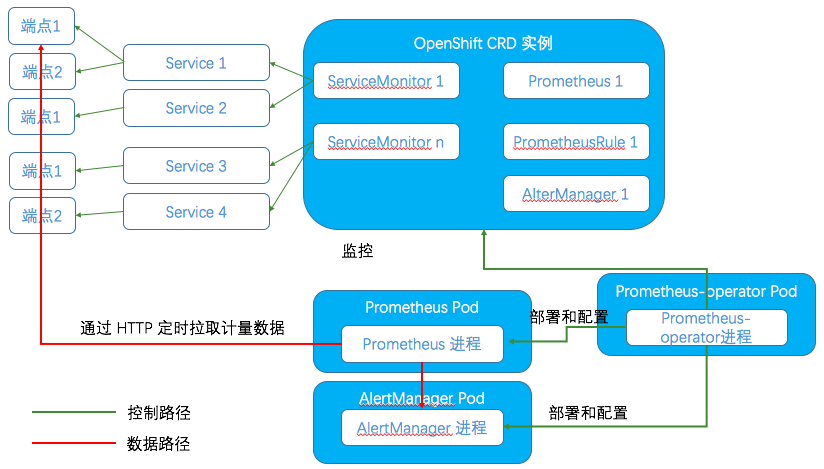
3.1.2 监控一个运行在OpenShift 中的应用
首先,应用的计量数据是应用自己产生的,只不过是被Prometheus获取了。一个应用要被Prometheus 监控,需要满足几个条件:
- 首先的要求是,应用要暴露出计量数据。如果它不提供计量数据,也就不需要被监控了。
- 其次,需要满足Prometheus 的数据格式和数据获取要求。Prometheus 定义了计量数据的规范,同时定义了获取方式(通过HTTP Get 获取)。如果应用需要直接被Prometheus 监控,那么就得满足这些要求。
- 如果应用本身有数据,但是不满足Prometheus 的要求,也有一些办法。其中一个办法是实现一个 sidecar exporter。它负责以应用特有的格式去获取应用的计量数据,然后按照 Prometheus 的要求将数据暴露出来。Prometheus 已经提供了一些实现,比如 HAProxy 的 exporter 在 https://github.com/prometheus/haproxy_exporter。
其次,需要做一些配置,使得 Prometheus 知道如何去获取应用的计量数据。从上图可以看出,通过使用 Prometheus Operator,配置监控的过程被大大简化了。基本上大致步骤为:
- 部署应用服务,检查它的或他的 exporter 的 metrics HTTP API 能否正确运行
- 为该应用服务创建一个 ServiceMonitor 对象
- 修改 PrometheusRule 对象,为应用添加监控和告警规则
然后,Prometheus 就会自动地将这些变动应用到 Prometheus 和 AlterManager 实例中,然后该应用就会被监控到了。
3.2 产品相关
对当前这套基于 Prometheus 的OpenShift/Kubernetes 监控系统,我认为它还不够成熟,在很多地方有待提高。比如Prometheus高可用,目前还没有很好的方法;比如Prometheus 的存储,从设计上它就只能作为短期存储,如果应用于大型的生产环境,短时间内就会产生大量数据,那该怎么办?;比如监控和告警规则配置,还不够灵活和方便;比如服务发现,如果被监控的目标量很大而且变化很快,Prometheus 能否能够及时响应?Grafana 如何做多租户实现?等等。
因此,当前,我认为它还是更加适合于平台监控,也就是面向平台运维人员的。因此此时很多要求都可以被妥协,比如稳定性、扩展性、多租户、灵活性、用户友好等。
如果要用于用户应用的监控,那还有大量工作需要做,包括但不限于:
- 用户如何配置其应用监控(如何创建和管理 CRD 对象等)
- 用户如何创建和管理监控和告警规则
- Grafana 如何实现多租户
- Prometheus 如何支持大量的被监控对象和计量信息
参考链接:
- http://supergiant.io/blog/introduction-to-kubernetes-monitoring-architecture/
- https://segmentfault.com/a/1190000013230914
- https://yunlzheng.gitbook.io/prometheus-book/part-iii-prometheus-shi-zhan/readmd/service-discovery-with-kubernetes
- https://sysdig.com/blog/kubernetes-monitoring-prometheus/
- https://blog.freshtracks.io/a-deep-dive-into-kubernetes-metrics-66936addedae
感谢您的阅读,欢迎关注我的微信公众号:

2.4 ServiceMonitor 实例
ServiceMonitor 是 Prometheus Operator 向运维人员暴露出来的被监控的目标。在部署完成后,默认创建了9个 ServiceMonitor 对象,对应9个需要被 Prometheus 监控的核心服务:
2.4.1 alertmanager
AlterManager 是一个 Prometheus 套件中的独立组件,它自身实现了符合 Prometheus 要求的计量信息接口。
2.4.2 cluster-monitoring-operator
这是 OpenShift cluster monitoring opeator 服务。它也实现了计量接口。其中的代码示例如下:
2.4.3 kube-apiserver
这是 OpenShift 的 API 和 DSN 服务。
2.4.4 kube-controllers
这是 K8S master controllers 服务。
2.4.5 kube-state-metrics
这是一个开源项目,地址在 https://github.com/kubernetes/kube-state-metrics。它从 K8S API Server 中获取数据,比如:
ksm_resources_per_scrape{resource="node",quantile="0.99"} 7
ksm_resources_per_scrape_sum{resource="node"} 255444
ksm_resources_per_scrape_count{resource="node"} 36492
ksm_resources_per_scrape{resource="persistentvolume",quantile="0.5"} 15
ksm_resources_per_scrape{resource="persistentvolume",quantile="0.9"} 15
2.4.6 kubelet
kubelet 服务包含多个Static Pod,每个Pod在集群的每个节点上。它除了自身提供 kublet 的计量信息外,还内置了 cAdvisor 服务,因此也提供 cAdvisor 信息。 cAdvisor 对 Node机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,cAdvisor集成在Kubelet中,当kubelet启动时会自动启动cAdvisor,即一个cAdvisor仅对一台Node机器进行监控。
2.4.7 node-exporter
2.4.8 prometheus
这是 Prometheus 服务,它可有多个 StatefulSet Pod,每个 Pod 中运行一个 Prometheus 进程。
2.4.9 prometheus-operator
这是 Prometheus Operator 服务,只有一个pod。
2.5 基于OpenShift ServiceMonitor 和 Prometheus Service Discovery(服务发现)的监控的实现
Prometheus Pod 中,除了 Prometheus 容器外,还有一个 prometheus-config-reloader 容器。它负责导入Prometheus 配置文件。配置文件被以 Secret 形式挂载给 prometheus-config-reloader Pod。一旦配置有变化,它会调用 Prometheus 的接口,使其重新加载配置文件。
配置文件中定义了被监控的目标为这些 ServiceMonitor 对象所对应的服务:
每个 job 都采用 endpoints 类型的 Prometheus 服务发现机制。也就是说,Prometheus 会调用 OpenShift 的API,首先找到每个 job 所配置的 OpenShift 服务,然后找到这服务的端点(endpoint)。每个 OpenShfit endpoint 是一个 Prometheus target(目标),可以在 Prometheus 界面上看到目标列表。然后在每个目标上,调用 metrics HTTP API,以拉取(GET)形式,获得该服务的计量数据。
3. 利用 Prometheus 对部署在 OpenShift 平台上的应用进行监控
3.1 技术实现
3.1.1 监控框架总结
把前面的内容再总结一下,得出下面的监控框架图:
3.1.2 监控一个运行在OpenShift 中的应用
首先,应用的计量数据是应用自己产生的,只不过是被Prometheus获取了。一个应用要被Prometheus 监控,需要满足几个条件:
- 首先的要求是,应用要暴露出计量数据。如果它不提供计量数据,也就不需要被监控了。
- 其次,需要满足Prometheus 的数据格式和数据获取要求。Prometheus 定义了计量数据的规范,同时定义了获取方式(通过HTTP Get 获取)。如果应用需要直接被Prometheus 监控,那么就得满足这些要求。
- 如果应用本身有数据,但是不满足Prometheus 的要求,也有一些办法。其中一个办法是实现一个 sidecar exporter。它负责以应用特有的格式去获取应用的计量数据,然后按照 Prometheus 的要求将数据暴露出来。Prometheus 已经提供了一些实现,比如 HAProxy 的 exporter 在 https://github.com/prometheus/haproxy_exporter。
其次,需要做一些配置,使得 Prometheus 知道如何去获取应用的计量数据。从上图可以看出,通过使用 Prometheus Operator,配置监控的过程被大大简化了。基本上大致步骤为:
- 部署应用服务,检查它的或他的 exporter 的 metrics HTTP API 能否正确运行
- 为该应用服务创建一个 ServiceMonitor 对象
- 修改 PrometheusRule 对象,为应用添加监控和告警规则
然后,Prometheus 就会自动地将这些变动应用到 Prometheus 和 AlterManager 实例中,然后该应用就会被监控到了。
3.2 产品相关
对当前这套基于 Prometheus 的OpenShift/Kubernetes 监控系统,我认为它还不够成熟,在很多地方有待提高。比如Prometheus高可用,目前还没有很好的方法;比如Prometheus 的存储,从设计上它就只能作为短期存储,如果应用于大型的生产环境,短时间内就会产生大量数据,那该怎么办?;比如监控和告警规则配置,还不够灵活和方便;比如服务发现,如果被监控的目标量很大而且变化很快,Prometheus 能否能够及时响应?Grafana 如何做多租户实现?等等。
因此,当前,我认为它还是更加适合于平台监控,也就是面向平台运维人员的。因此此时很多要求都可以被妥协,比如稳定性、扩展性、多租户、灵活性、用户友好等。
如果要用于用户应用的监控,那还有大量工作需要做,包括但不限于:
- 用户如何配置其应用监控(如何创建和管理 CRD 对象等)
- 用户如何创建和管理监控和告警规则
- Grafana 如何实现多租户
- Prometheus 如何支持大量的被监控对象和计量信息
参考链接:
- http://supergiant.io/blog/introduction-to-kubernetes-monitoring-architecture/
- https://segmentfault.com/a/1190000013230914
- https://yunlzheng.gitbook.io/prometheus-book/part-iii-prometheus-shi-zhan/readmd/service-discovery-with-kubernetes
- https://sysdig.com/blog/kubernetes-monitoring-prometheus/
- https://blog.freshtracks.io/a-deep-dive-into-kubernetes-metrics-66936addedae
感谢您的阅读,欢迎关注我的微信公众号: