7.1 专家系统的产生和发展 7.2 专家系统的概念 7.3 专家系统的工作原理 7.4 知识获取的主要过程与模式 7.5 机器学习 7.6 知识发现与数据挖掘 7.7 专家系统的建立 7.8 专家系统实例 7.9 专家系统的开发工具
特点:高度的专业化。 专门问题求解能力强。 结构、功能不完整。 移植性差。 缺乏解释功能。
专家系统的定义:

1、具有专家水平的专业知识。 2、能进行有效的推理。 3、启发性。 4、灵活性。 5、透明性。 6、交互性。
专家系统与传统程序的比较:
1、编程思想
传统程序 = 数据结构+算法
专家系统 = 知识+推理
2、传统程序关于问题求解的知识隐含于程序中。
专家系统知识单独组成知识库,与推理机分离。
3、处理对象
传统程序数值计算和数据处理。
专家系统符号处理。
4、传统程序不具有解释功能。
专家系统具有解释功能。
5、传统程序产生正确的答案。
专家系统通常产生正确的答案,有时产生错误的答案。
6、系统的体系结构不同。
工作原理

抽取知识、知识的转换、知识的输入、知识的检测 。
知识获取的模式:非自动知识获取、自动知识获取、半自动知识获取。
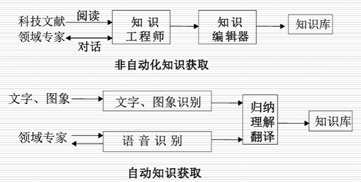
机器学习
机器学习Machine learning、使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。
一个学习系统一般应该有环境、学习、知识库、执行与评价(à学习)等四个基本部分组成。
“示例空间”是所有可对系统进行训练的示例集合。
“搜索”的作用是从示例空间中查找所需的示例。
“解释”是从搜索到的示例中抽象出所需的有关信息形成知识。
“形成知识”是把解释得到的信息综合、归纳形成一般性的知识。
“验证”的作用是检验所形成的知识的正确性。
知识发现与数据挖掘
31 知识发现和数据挖掘的目的:从数据集中抽取和精化一般规律或模式。
知识发现过程分为数据准备、数据挖掘以及结果的解释评估等三步。
- 数据准备数据选、数据预处理和数据变换。
数据选取就是根据用户的需要从原始数据库中抽取的一组数据。
数据预处理一般可能包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换等。
数据变换是从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数
- 数据挖掘
数据挖掘阶段首先要确定挖掘的任务或目的是什么,如数据总结、分类、聚类、关联规则或序列模式等。
确定了挖掘任务后,就要决定使用什么样的挖掘算法。同样的任务可以用不同的算法来实现。
选择实现算法有两个考虑因素:
一是不同的数据有不同的特点,因此需要用与之相关的算法来挖掘
二是用户或实际运行系统的要求,有的用户可能希望获取描述型的、容易理解的知识,而有的用户系统的目的是获取预测准确度尽可能高的预测型知识。
- 结果解释和评价
数据挖掘阶段发现的知识模式中可能存在冗余或无关的模式,所以还要经过用户或机器的评价。
若发现所得模式不满足用户要求,则需要退回到发现阶段之前,如重新选取数据,采用新的数据变换方法,设定新的数据挖掘参数值,甚至换一种挖掘算法。
由于KDD最终是面向人的,因此可能要对发现的模式进行可视化,或者把结果转换为用户易懂的另一种表示,如把分类决策树转换为“if-then…”规则。
知识发现的任务:
数据总结:对数据进行浓缩,给出它的紧凑描述。
概念描述:从学习任务相关的数据中提取总体特征。
分类:提出一个分类函数或分类模型 也常常称作分类器,该模型能把数据库中的数据项映射到给定类别中的一个。
聚类:根据数据的不同特征,将其划分为不同的类。包括统计方法、机器学习方法、神经网络方法和面向数据库的聚类方法等。 (聚类-无监督学习)
相关性分析:发现特征之间或数据之间的相互依赖关系。
偏差分析:寻找观察结果与参照量之间的有意义的差别。
建模:通过数据挖掘,构造出能描述一种活动、状态或现象的数学模型。
知识发现的主要方法: 1.统计方法:从事物的外在数量上的表现去推断事物可能的规律性。常见的有回归分析、判别分析、聚类分析以及探索分析等。 2.粗糙集:粗糙集是具有三值隶属函数的模糊集,即是、不是、也许。常与规则归纳、分类和聚类方法结合起来使用。 3.可视化:把数据、信息和知识转化为图形等,使抽象的数据信息形象化。信息可视化也是知识发现的一个有用的手段。 4.传统机器学习方法:包括符号学习和连接学习。
知识发现的对象 1.数据库当前研究比较多的是关系数据库的知识发现。 2.数据仓库数据挖掘为数据仓库提供深层次数据分析的手段,数据仓库为数据挖掘提供经过良好预处理的数据源。 3. Web信息Web知识发现主要分内容发现和结构发现。内容发现是指从Web文档的内容中提取知识;结构发现是指从Web文档的结构信息中推导知识。 4. 图像和视频数据图像和视频数据中也存在有用的信息。比如,地球资源卫星每天都要拍摄大量的图像或录像。
专家系统的建立
什么情况下开发专家系统是可能的
1,主要依靠经验性知识,不需运用大量常识性知识就可解决的任务。 2,存在真正的领域专家。 3,有明确的开发目标且任务不太难实现。
什么情况下开发专家系统是合理的
1,具有较高的经济效益。 2,人类专家奇缺但在许多地方又十分需要。 3,人类专家经验不断丢失。 4,危险场合需要专业知识 。
什么情况下开发专家系统是合适的
1,本质问题能通过符号操作和符号结构进行求解且需使用启发式知识、经验规则才能得到答案。 2,复杂性。 3,范围所选任务的大小可驾驭、 任务有实用价值。
专家系统的设计原则与开发步骤

专家系统的评价
1. 正确性 1,系统设计的正确性: 系统设计思想的正确性。 系统设计方法的正确性。 设计开发工具的正确性。 2,系统测试的正确性: 测试目的、方法、条件的正确性。 测试结果、数据、记录的正确性。3系统运行的正确性 推理结论、求解结果、咨询建议的正确性。 推理解释及可信度估算的正确性。 知识库知识的正确性。
2. 有用性
专家系统实例
专家系统的开发工具
骨架型工具
骨架型工具是从被实践证明了有实用价值的专家系统中,抽出了实际领域的知识背景,并保留了系统中推理机的结构所形成的一类工具。EMYCIN、EXPERT和PC等均属于此类型。EMYCIN疾病诊断专家系统MYCIN的基础上,抽去了医疗专业知识,修改了不精确推理,增强了知识获取和推理解释功能之后构造而成的世上最早的专家系统工具之一。EXPERT是从石油勘探和计算机故障诊断专家系统中抽象并构造出来的,适用于开发诊断解释型专家系统。
通用型知识表达语言OPS5
专家系统开发环境:AGEattempt to generalize)一种典型的模块组合式开发工具。
专家系统程序设计语言
- 符号处理语言(面向 AI 的语言或 AI 语言
PROLOG语言 LISP语言
2. 面向问题的语言C语言、 C++语言。