以下是我的学习笔记,以及总结,如有错误之处请不吝赐教
本文主要介绍一些爬虫基础知识。
HTTP协议:
http是一个请求<->响应模式的典型范例,即客户端向服务器发送一个请求信息系,服务器来响应这个信息。在老的http版本中,每个请求都将被创建一个新的客户端->服务器的链接,在这个连接上发送请求,然后节后请求。这样的模式有一个很大的有点就是,简单,容易理解和编程实现;特也有一个缺点就是效率低,因此Keep-Alive被提出用来解决效率低的问题。keep-alive功能使客户端的链接持续有效,当出现对服务器的后继请求时,keep-alive功能避免了建立或者重新建立连接。
http/1.1默认情况下所有连接都被保持,除非在请求头或者响应头中指明要关闭:connection:close。
主要包括:物理层(电器连接)、数据链路层(交换机、STP、帧中继)、网络层(路由器、IP协议)、传输层(TCP、UDP协议)、会话层(建立通信连接、拨号上网)、表示层(每次连接只处理一个请求)、应用层(HTTP、FTP),具体如下图:

特点:①应用层的协议,②无连接:每次连接只处理一个请求,③无状态:每次连接、传输都是独立的。
HTTP HEADER:
- request:

- response:

HTTP请求方法:主要有get、head、post等等,具体如下表:

HTTP响应状态码:
- 2**:成功
- 3**:跳转

- 4**:客户端错误
错误处理:

- 500服务器错误
错误处理:

HTML语言:
是超文本标记语言,简单来说是可以认为一种规范或者协议,浏览器根据html的语言规范来解析。html中与爬虫相关的规范有以下几个:

DOM树:是用来做网页数据分析及提取,我们可以利用Tag、Class、ID来找某一类或某一种元素并提取内容:
Javascript语言:
是运行在前端的编程语言,最典型的是用在动态网页的数据、内容加载及呈现上,Javascript做网络请求的时候最常用的技术称为:AJAX(asynchoronous javascript and xml),专门用来异步请求数据。具体如下图示例:

网页抓取原理:
根据抓取对象类型:①静态网页、②动态网页、③web service进行抓取,分为深度优先策略和宽度优先策略两种:


策略选择:
- 网页距离种子站点的距离
- 万维网深度并没有很深,一个网页有很多路径课到达
- 宽度优先有利于多爬虫并行合作抓取
- 深度限制于宽度优先相结合
不重复策略:
记录抓取历史的方法:
- 将访问过的url保存到数据库:效率太低
- 用hashset将访问过的url保存起来,只需要接近o(1)的代价就可以查到一个url是否被访问过了:消耗内存
- MD5方法:url经过MD5户SHA-1等单项哈希后再保存到HashSet或数据库

- Bit-Map方法:建立一个bitset,将每个url经过一个哈希函数映射到某一位,①评用site方法估网站的网页数量,②选择合适的hash算法和空间阈值,降低碰撞几率,③选择合适的存储结构和算法,具体如下图:
 优势:对村抽进行进一步压缩,在MD5的基础上,可以冲128位压缩到1位,一般情况,如果用4bit或者8bit表示一个url,也能压缩32或者16倍;缺陷:碰撞概率增加
优势:对村抽进行进一步压缩,在MD5的基础上,可以冲128位压缩到1位,一般情况,如果用4bit或者8bit表示一个url,也能压缩32或者16倍;缺陷:碰撞概率增加 - Bloom Filter方法:使用了多个哈希函数,而不是一个。创建一个m位bitset,先将所以有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str的结果记为h(i,str),且h(i,str)的范围是0到m-1。只能插入,不能删除。具体结构如图:

如何使用以上方法:
- 多数情况下不需要压缩,尤其网页数量少的情况
- 网页数量大的情况下,使用Bloom Filter压缩
- 重点是计算碰撞概率,并根据碰撞概率来确定存储空间的阈值
- 分布式系统,将散列映射到多台主机的内存
网站结构分析:
- 一般网站对爬虫都有限制,例如打开robots.txt网页:

- 利用sitemap里的的信息:大多数网站都会存在明确的top-down的分类的目录结构,我们可以利用sitemap来分析网站结构和估算目标网页的规模:


- 对网站目录结构进行分析:例如www.mafengwo.cn这个网站,所有旅游游记都位于www.mafengwo.cn/mdd下,按照城市进行了分类,每个城市的游记都位于城市的首页,如下图:
游记的分页格式:
游记的页面:

XPath语言:
是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。具体教程可以看:W3school
- 基本语法:
@属性:在DOM树,以路径的方式查询节点,通过@符号来选取属性,如下图所示:rel class href都是属性,可以通过“//*[@class='external text']”来选取对应元素;=符号要求属性完全匹配,可以用contain方法来部分匹配,例如:“//*[contain(@class,'external')]”可以匹配,而“//*[@class='external']”则不能。
运算符:and和or运算符:选择p或者span或者h1标签的元素:
选择class为editor或者tag的元素:

正则表达式:
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特性字符,及这些特定字符的组合,组成一个规则字符串,这个规则字符串用来表发对字符串的一种过滤逻辑。一些常用规则:

在爬虫的解析中,经常会将正则表达式与Dom选择器结合使用。正则表达式适用于字符串特征比较明显的情况,但是同样的正则表达式可能在HTML源码中多次出现,而DOM选择器可以通过class及id来精确找到DOM块,从而缩小查找范围。以下是一些常用爬虫正则规则:
- 获取标签下的文本:

- 查找特定类别的链接,例如/wiki/不包含category目录:

- 查找商品外链,例如jd的商品外链为7位数字的a标签节点:
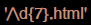
- 查找淘宝的商品信息,或者开始及结尾:

贪婪模式及非贪婪模式:?该字符紧跟任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配搜索的字符串,而默认的贪婪模式则尽可能多得匹配搜索的字符串,具体如下图:
To be continue......