决策树算法的阶段:
1.训练阶段(决策树学习),也就是说:怎么样构造出来这棵树?
2.测试阶段。
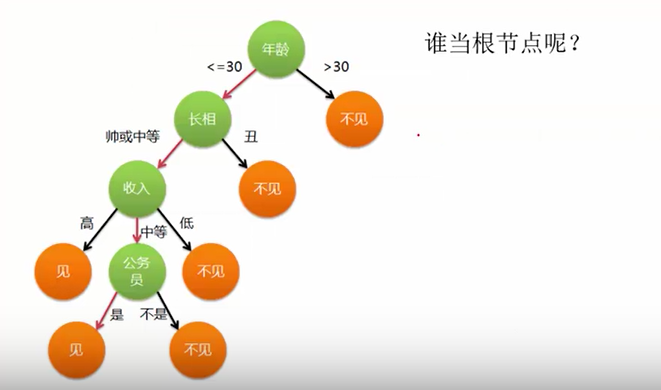
问题:构造决策树,谁当根节点?例:相亲时为啥选年龄作为根节点?
H(X)为事件发生的不确定性。
事件X,Y相互独立,概率P(X),P(Y)。认为:P(几率越大)->H(X)越小,如今天正常上课。P(几率越小)->H(X)越大,如今天翻车了。
熵是表示随机变量不确定性的度量。熵越大,不确定性越大,越混乱。
设X是一个取有限个值的离散随机变量,其概率分布为:P(X=xi)=pi, i=1,2,...,n,则随机变量X的熵定义为:

由定义可知,熵只依赖于X的分布,而与X的取值无关,所以也可将X的熵记做H(p)。![]()
例2:对于两个集合A,B来说,如果A比较混乱,B内部比较单一纯净,那么集合A的熵更大。
思想:构造决策树,随着深度的增加,节点的熵迅速降低。熵降低的速度越快越好,迅速地构建出决策树。\
案例:
1.先计算原始数据的熵,为0.940.


