巨人之肩的牛顿 巨人之肩的牛顿 今天
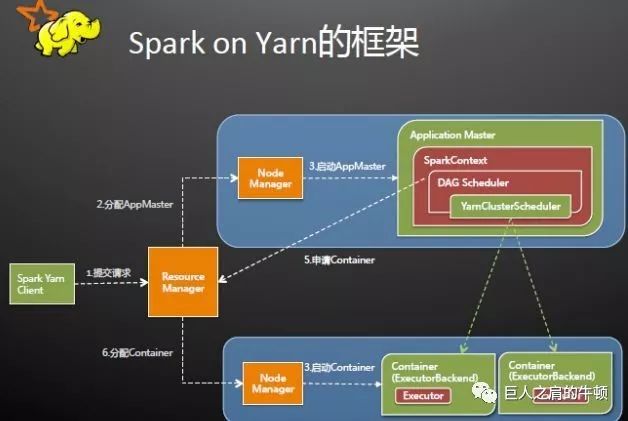
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
请关注测微信公众号,会不断的发出需要的教程。没有套路,没有转发,只是用于大家一起学习。如果下载不了,请立即联系管理员。

教程仅供技术交流,请勿用于商业及非法用途,如产生法律纠纷与本人无关。
链接: https://pan.baidu.com/s/1jREHFEL0awMOtWYSx4qLPg 提取码: i1eg 复制这段内容后打开百度网盘手机App,操作更方便哦