快速排序
- 随便取个数,作为标志值,这里就默认为索引位置为0的值
- 记录左索引和右索引,从右往左找比标志值小的,小值和左索引值交换,右索引变化,然后从左往右找比标志值大的,大值和右索引值交换,左索引变化
- 循环第二步骤直到左索引和右索引碰头,标志值和当期左索引(右)交换,这样一个循环下,就得出一个标志值左边都比它小,右边都比大的数据样本
- 利用递归,对数据进行上述过程的最终标志值索引分割,分割到递归底层只有两个数,那么上述过程排序就一定有序了
实现要点:随机取标志值,循环右取小、左取大,利用左右索引碰头位置进行递归分割
def partition(li, left, right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp: #从右面找比tmp小的数
right -= 1 # 往左走一步
li[left] = li[right] #把右边的值写到左边空位上
# print(li, 'right')
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left] #把左边的值写到右边空位上
# print(li, 'left')
li[left] = tmp # 把tmp归位
return left
def _quick_sort(li, left, right):
if left<right: # 至少两个元素
mid = partition(li, left, right)
_quick_sort(li, left, mid-1)
_quick_sort(li, mid+1, right)
快速排序一般情况很快,但是遇到最坏情况(倒序的情况),算法复杂度为O(n2),最好的情况(正序),算法复杂度为O(n)
快速排序有可能超过最大递归深度
堆排序
堆排序难点就是有一堆的概念需要你理解,开始前,那就必须讲讲概念了
树结构:我们程序见到的结构很像生活中的树,不过这里的是倒挂的,根在上,叶子在下,而根,在结构中,我们称为根节点,叶子称为叶子节点,中间的为枝节点
满二叉树和完全二叉树:
- 二叉树,就是每个节点最多两个枝节点或叶子节点
- 深度k,数下树有多少层,比如下图就是深度为4
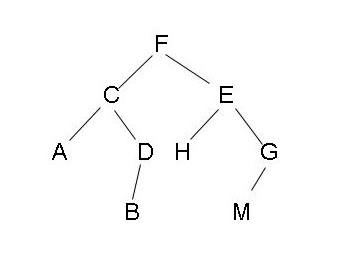
- 满二叉树,除最后一层叶子节点,其他层节点都有两个子节点,节点数满足2^k-1
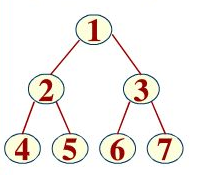
- 完全二叉树,节点数满足至少有2k-1个,至多有2k-1个,最后一层叶子节点可缺,但是这个缺,要连续缺,比如上图,缺7或缺67或缺567
大根堆和小根堆:
- 大根堆:满足父节点都比子节点大的完全二叉树
- 小根堆:满足父节点都比子节点小的完全二叉树
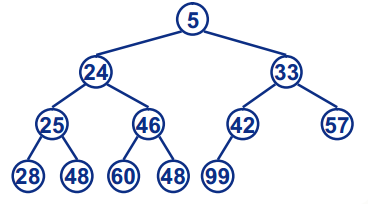
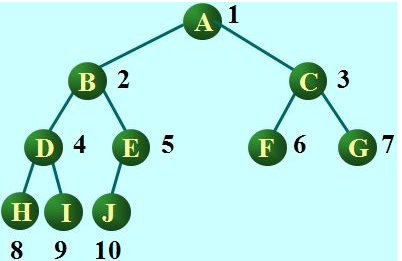
树的存储:存储时,我们用的就是列表存储,不过你会想,那怎么体现树的结构在里面的呢?从根节点开始,根节点放入索引位置为0的地方,下一层,从左为右依次放入,就如下图
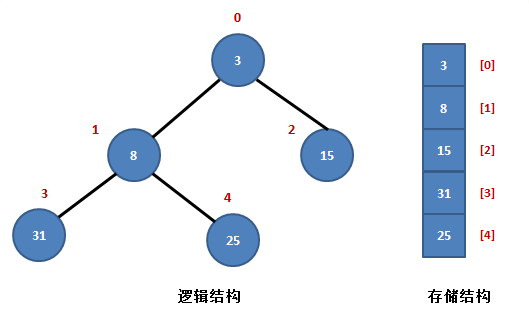
树的存储规律:
- 已知父节点位置为i,获取左子节点位置为:2i+1,获取右子节点位置为:2i+2
- 已知子节点位置为i,获取父节点:无论这个子节点是左子还是右子,(i-1) // 2
堆的向下调整和建堆
由于刚开始拿到堆并不满足大根堆(大根堆用于从小到大排序,因为每次取完根节点最大数都是放在树的最后位置,也就是列表的最后位置,小根堆则用于从大到小排序)的情况,所以还需要了解堆的向下调整和建堆
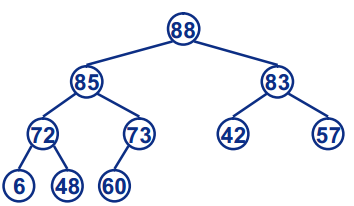
- 堆的向下调整,如下图,刚开始堆不满足大根堆,因为不满足根节点30比47,91大,所以需要进行向下调整,第一步:左右子节点比较,91大,并且大于根节点,发生位置交换 第二步:30下一层左右子节点比较,85大,也比30大,发生位置交换
经过上面过程,此时的堆就是大根堆了,不过这个调整过程有个前提,就是根节点下的子堆已经满足大根堆的条件,建立这个条件,我们叫建堆
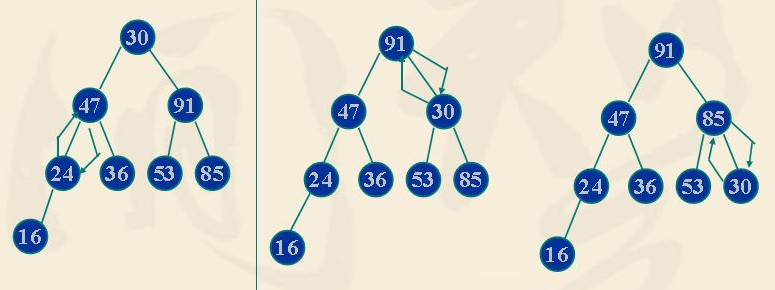
- 建堆:过程就要从底层的堆开,好比民主选择样,先从村选村长,再从村长中选县长,层层推举上去,如下图
第一步:85-91堆选举,91大,当村长,91目前就是村长,不用换
第二步:12-24-30堆选举,30大,当县长,情况满足不用换
第三步:85-47-91-36堆选举,91大,当县长,36-91交换,而且36比85小,村长也当不了,85-36交换,该过程就是向下调整的过程,村级对满足大根堆条件
第四步:整个堆推选市长,53小,又是向下调整的过程

所以建堆本质上也就是小堆基础上进行向下调整就能达到建堆的目的
代码实现要点:
- 堆向下调整:堆调整的上下边界,循环过程从2i+1左子节点开始,左右(前提是有右子)子节点比较大小-然后和父节点值比较确定是否交换
- 建堆:确定最后叶子节点(n-1)的父节点((n-2) // 2), 倒序循环调用向下调整
- 取数:根节点数与最后位置发生交换,调用向下调整(注意下边界high的变化,排除取好的最大数在调整范围)
def sift(li, low, high):
"""
:param li: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return:
"""
i = low # i最开始指向根节点
j = 2 * i + 1 # j开始是左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有数
if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子有并且比较大
j = j + 1 # j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j # 往下看一层
j = 2 * i + 1
else: # tmp更大,把tmp放到i的位置上
li[i] = tmp # 把tmp放到某一级领导位置上
break
else:
li[i] = tmp # 把tmp放到叶子节点上
def heap_sort(li):
n = len(li)
for i in range((n-2)//2, -1, -1):
# i表示建堆的时候调整的部分的根的下标
sift(li, i, n-1)
# 建堆完成了
for i in range(n-1, -1, -1):
# i 指向当前堆的最后一个元素
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1) #i-1是新的high
li = [i for i in range(100)]
import random
random.shuffle(li)
print(li)
heap_sort(li)
print(li)
利用堆排序解决topK问题
思路:需要多少k,就建立以k个节点的小根堆,循环剩下数,如果比当前堆的根节点大,放入堆中,进行向下调整
def sift(li, low, high):
i = low
j = 2 * i + 1
tmp = li[low]
while j <= high:
if j + 1 <= high and li[j+1] < li[j]:
j = j + 1
if li[j] < tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
break
li[i] = tmp
def topk(li, k):
heap = li[0:k]
for i in range((k-2)//2, -1, -1):
sift(heap, i, k-1)
# 1.建堆
for i in range(k, len(li)-1):
if li[i] > heap[0]:
heap[0] = li[i]
sift(heap, 0, k-1)
# 2.遍历
for i in range(k-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
sift(heap, 0, i - 1)
# 3.出数
return heap
import random
li = list(range(1000))
random.shuffle(li)
print(topk(li, 10))
归并排序
归并排序的原理是两个已经有序的列表合并为大的有序列表,合并过程中,两个列表各自最小的数进行比较,把小的放入到一个新的列表
归并排序分为两个过程:拆分过程和合并过程,拆分过程好弄,就按一半一半的拆,直到底层为一个数的列表,此时开始合并,此时合并的前提--两个有序的列表已经满足
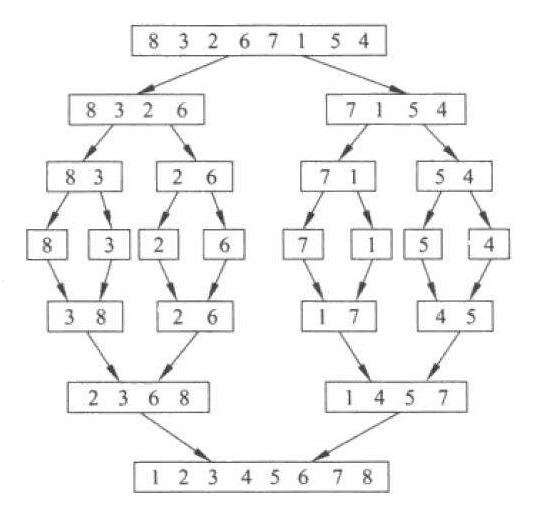
代码实现点:利用递归一半一半的分,合并:确定两个列表的边界范围,两个各取最小数进行比较-小的添加到新列表-对应的索引变化
注意:肯定有一边的数因为普遍小,先循环完,所以最后只要还有数的列表进行循环添加就可以了
def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i<=mid and j<=high: # 只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
# while执行完,肯定有一部分没数了
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp
# li = [2,4,5,7,1,3,6,8]
# merge(li, 0, 3, 7)
# print(li)
def merge_sort(li, low, high):
if low < high: #至少有两个元素,递归
mid = (low + high) //2
merge_sort(li, low, mid)
merge_sort(li, mid+1, high)
merge(li, low, mid, high)
li = list(range(1000))
import random
random.shuffle(li)
print(li)
merge_sort(li, 0, len(li)-1)
print(li)