1、什么是算法


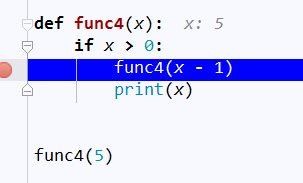
2、递归





# 一直递归,递归完成再打印 def func4(x): if x > 0: func4(x - 1) print(x) func4(5)



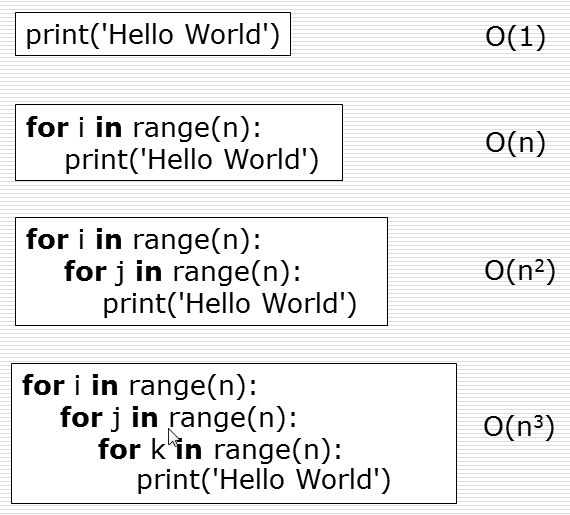
3、时间 复杂度
(1)引入
时间复杂度:用来评估算法运行效率的一个东西



(2)小结
时间复杂度是用来估计算法运行时间的一个式子(单位)。 一般来说,时间复杂度高的算法比复杂度低的算法快


(3)判断标准


(4)空间复杂度

4、列表查找:二分查找

(1)线性查找(顺序查找)


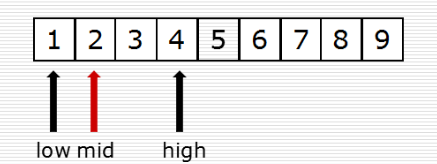
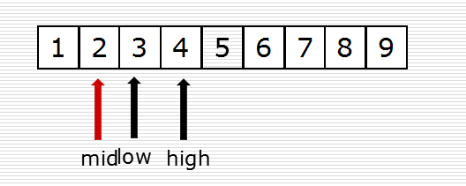
(2)二分查找


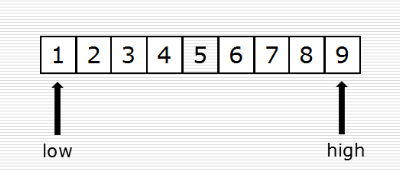
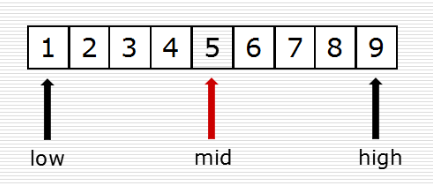


(3)alex版本
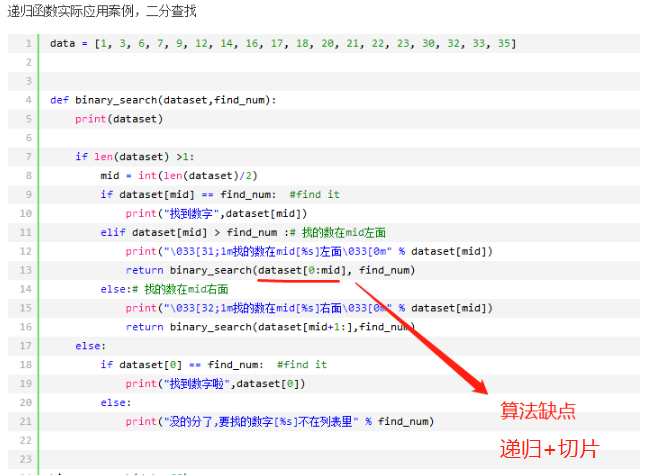
重新开辟了一块字典空间

(5)对比
不要在一个递归函数上直接加装饰器

#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 9:54 # @Author : Venicid # @Site : # @File : 02_half_search.py # @Software: PyCharm import time def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() x = func(*args, **kwargs) t2 = time.time() print("Time cost: ",func.__name__, t2-t1) return x return wrapper # 线性查找 @cal_time def linear_search(data_set,value): for i in range(len(data_set)): if data_set[i] == value: return i return 0 # alex版本的 # 不要在一个递归函数上直接加装饰器 # @cal_time def _binary_search(dataset, find_num): if len(dataset) > 1: mid = int(len(dataset) / 2) if dataset[mid] == find_num: # find it pass # print("找到数字", dataset[mid]) elif dataset[mid] > find_num: # 找的数在mid左面 # print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid]) return _binary_search(dataset[0:mid], find_num) else: # 找的数在mid右面 # print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid]) return _binary_search(dataset[mid + 1:], find_num) else: if dataset[0] == find_num: # find it pass # print("找到数字啦", dataset[0]) else: pass # print("没的分了,要找的数字[%s]不在列表里" % find_num) @cal_time def binary_search(data_set, val): return _binary_search(data_set, val) # 二分法必须是有序列表 @cal_time def half_search(data_set, value): low = 0 high = len(data_set) - 1 while low <= high: mid = (low + high) // 2 if data_set[mid] == value: return mid elif data_set[mid] > value: high = mid - 1 else: low = mid + 1 data = list(range(100000000)) linear_search(data, 153) binary_search(data, 153) half_search(data, 153)
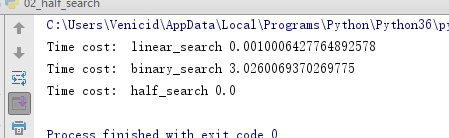
(6)列表查找:练习
![]()
[ {id:1001, name:"张三", age:20}, {id:1002, name:"李四", age:25}, {id:1004, name:"王五", age:23}, {id:1007, name:"赵六", age:33} ]

# -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 11:42 # @Author : Venicid
import random def random_list(n): """生成学生信息表""" ret = [] ids = list(range(100,100+n)) name_1 = ['赵','钱','孙','李','王'] name_2 = ['打','算','发','的','撒','个','法','师'] name_3 = ['梅','兰','竹','菊','天','下','第','一'] for i in range(n): dic = {} dic['id'] = ids[i] dic['name'] = random.choice(name_1)+random.choice(name_2)+random.choice(name_3) dic['age'] = random.randint(18, 55) ret.append(dic) return ret def half_search(data_set, value): low = 0 high = len(data_set) - 1 while low <= high: mid = (low+high) //2 if data_set[mid]['id'] == value: return mid elif data_set[mid]['id'] > value: high = mid-1 else: low = mid+1 stus = random_list(5) ret = half_search(stus,104) print('index',ret) print(stus[ret])
5、列表排序


6、冒泡排序
(1)冒泡排序思路
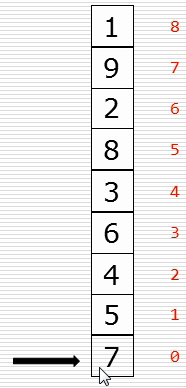
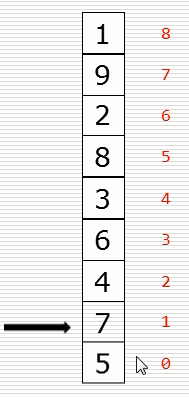

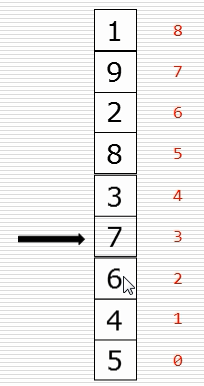
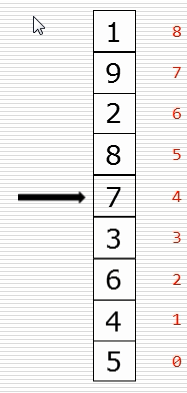



(2)基础版本


(3)冒泡排序-优化
如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。

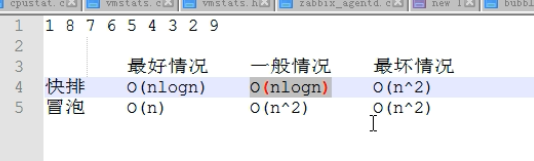
(4)最优时间复杂度,最坏时间复杂度

# -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 13:06 # @Author : Venicid import random import time def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() x = func(*args, **kwargs) t2 = time.time() print("Time cost: ",func.__name__, t2-t1) return x return wrapper # 冒泡排序 O(n) 最坏时间复杂度 @cal_time def bubble_sort(li): for i in range(len(li) - 1): # 趟数 for j in range(len(li) - i - 1): # j表示每次遍历需要比较的次数,是逐渐减小的 if li[j] > li[j + 1]: # 从小到大 # if li[j] < li[j + 1]: # 从大到小 li[j], li[j + 1] = li[j + 1], li[j] # 冒泡排序 优化 @cal_time def bubble_sort_1(li): for i in range(len(li) - 1): exchange = False for j in range(len(li) - i - 1): if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] exchange = True if not exchange: break data = list(range(1000)) # 理想状态的,有序list 最优时间复杂度 # random.shuffle(data) # 洗牌 bubble_sort(data) bubble_sort_1(data) print(data)

7 、选择排序
(1)选择排序思路


(2)选择排序代码


def select_sort(li): for i in range(len(li)-1): min_index = i # 记录最小位置 for j in range(i+1, len(li)): if li[j] < li[min_index]: min_index = j if min_index != i: # 如果选择出的数据不在正确位置,进行交换 li[i],li[min_index] = li[min_index],li[i] data = list(range(1000)) random.shuffle(data) # 洗牌 select_sort(data) print(data)
8、插入排序
(1)思路



(2)演示图
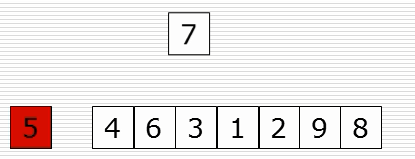
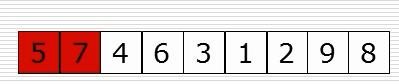



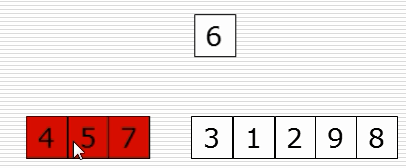



def insert_sort(li): for i in range(1, len(li)): # 从第二个位置,即下标为1的元素开始向前插入 tmp = li[i] j = i - 1 while j >= 0 and li[j] > tmp: li[j + 1] = li[j] j = j - 1 li[j + 1] = tmp data = list(range(1000)) random.shuffle(data) # 洗牌 insert_sort(data) print(data)
9、总结--排序Lowb 三人组


# -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 11:42 # @Author : Venicid import random import time def random_list(n): """生成学生信息表""" ret = [] ids = list(range(100,100+n)) name_1 = ['赵','钱','孙','李','王'] name_2 = ['打','算','发','的','撒','个','法','师'] name_3 = ['梅','兰','竹','菊','天','下','第','一'] for i in range(n): dic = {} dic['id'] = ids[i] dic['name'] = random.choice(name_1)+random.choice(name_2)+random.choice(name_3) dic['age'] = random.randint(18, 55) ret.append(dic) return ret def bubble_sort(li): for i in range(len(li)-1): for j in range(len(li)-i-1): if li[j]['id'] > li[j+1]['id']: li[j],li[j+1]=li[j+1],li[j] stus = random_list(5) random.shuffle(stus) print(stus) bubble_sort(stus) print(stus)

10、快速排序:选出基准元素

(1)思路

(2)过程图
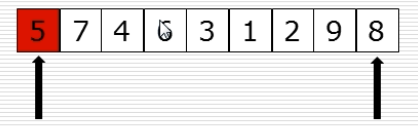




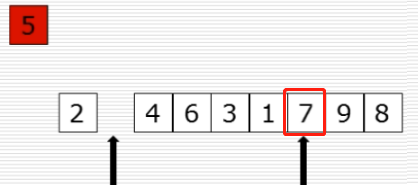
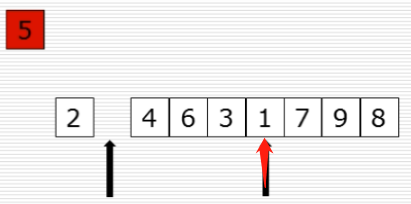
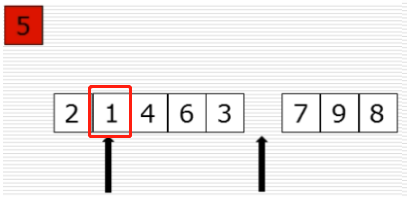

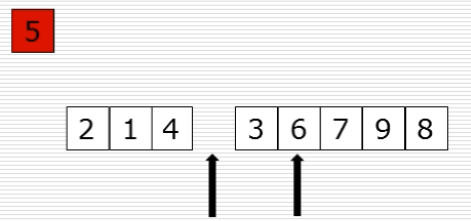
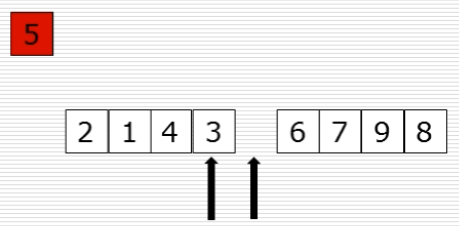
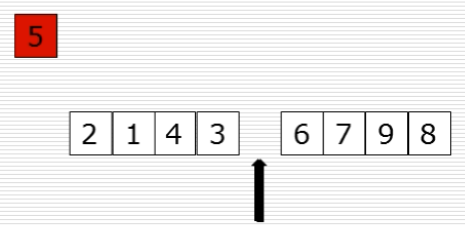
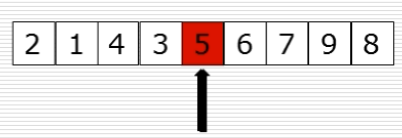
(3)快速排序代码第一步


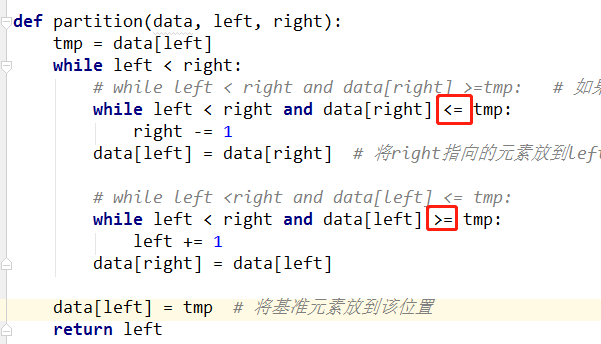
(4)partition函数

def quick_sort(data, left, right): if left<right: # 递归的退出条件 mid = partition(data, left,right) quick_sort(data,left,mid-1) # 对基准元素左边的子序列进行快速排序 quick_sort(data,mid+1, right) # 对基准元素右边的子序列进行快速排序 def partition(data,left, right): tmp = data[left] while left<right: while left < right and data[right] >=tmp: # 如果left与right未重合,right指向的元素不比基准元素小,则right向左移动 right -=1 data[left] = data[right] # 将right指向的元素放到left的位置上 while left <right and data[left] <= tmp: left+=1 data[right] = data[left] data[left] = tmp # 将基准元素放到该位置 return left data = list(range(1000)) random.shuffle(data) # 洗牌 quick_sort(data,0,len(data)-1) print(data)
(5)冒泡,快速,sort对比
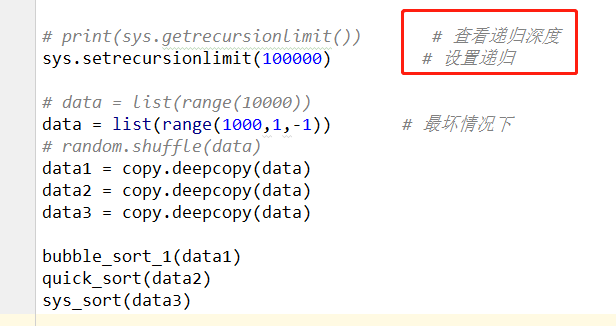
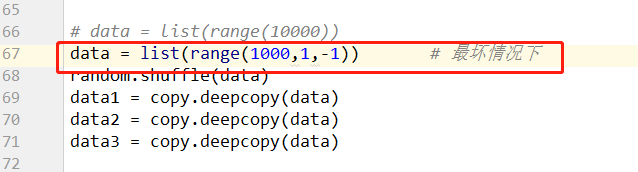
# -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 15:34 # @Author : Venicid import time import copy import sys def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() x = func(*args, **kwargs) t2 = time.time() print("Time cost: ", func.__name__, t2 - t1) return x return wrapper # 冒泡排序 优化 @cal_time def bubble_sort_1(li): for i in range(len(li) - 1): exchange = False for j in range(len(li) - i - 1): if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] exchange = True if not exchange: break # 快速排序 # 不能直接在递归函数上写装饰器 def quick_sort__(data, left, right): if left<right: # 递归的退出条件 mid = partition(data, left,right) quick_sort__(data,left,mid-1) # 对基准元素左边的子序列进行快速排序 quick_sort__(data,mid+1, right) # 对基准元素右边的子序列进行快速排序 def partition(data,left, right): tmp = data[left] while left<right: while left < right and data[right] >=tmp: # 如果left与right未重合,right指向的元素不比基准元素小,则right向左移动 right -=1 data[left] = data[right] # 将right指向的元素放到left的位置上 while left <right and data[left] <= tmp: left+=1 data[right] = data[left] data[left] = tmp # 将基准元素放到该位置 return left @cal_time def quick_sort(data): return quick_sort__(data, 0, len(data)-1) # python自带的sort (底层是c语言) @cal_time def sys_sort(data): return data.sort() # print(sys.getrecursionlimit()) # 查看递归深度 sys.setrecursionlimit(100000) # 设置递归 # data = list(range(10000)) data = list(range(1000,1,-1)) # 最坏情况下 # random.shuffle(data) data1 = copy.deepcopy(data) data2 = copy.deepcopy(data) data3 = copy.deepcopy(data) bubble_sort_1(data1) quick_sort(data2) sys_sort(data3)

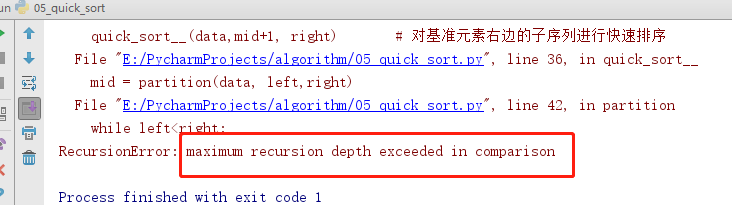
递归问题
python的递归深度为999
正常情况下

系统的sort底层是c

最坏情况下

(6)快速排序练习

学生表排序
# -*- coding: utf-8 -*- # @Time : 2018/07/30 0030 16:07 # @Author : Venicid import random def random_list(n): """生成学生信息表""" ret = [] ids = list(range(100,100+n)) name_1 = ['赵','钱','孙','李','王'] name_2 = ['打','算','发','的','撒','个','法','师'] name_3 = ['梅','兰','竹','菊','天','下','第','一'] for i in range(n): dic = {} dic['id'] = ids[i] dic['name'] = random.choice(name_1)+random.choice(name_2)+random.choice(name_3) dic['age'] = random.randint(18, 55) ret.append(dic) return ret def quick_sort(data, left, right): if left<right: # 递归的退出条件 mid = partition(data, left,right) quick_sort(data,left,mid-1) quick_sort(data,mid+1, right) def partition(data,left, right): tmp = data[left] while left<right: while left < right and data[right]['id'] >=tmp['id']: right -=1 data[left] = data[right] while left <right and data[left]['id'] <= tmp['id']: left+=1 data[right] = data[left] data[left] = tmp # 将基准元素放到该位置 return left stus = random_list(5) random.shuffle(stus) print(stus) quick_sort(stus,0,len(stus)-1) print(stus)
