写在最前面
作者田毅是清华大学2018年十名特等奖学金获得者之一,其在CVPR这一计算机视觉顶级期刊上发表了这篇文章,从微信推送刷到这一信息起,论文笔记就锁定这篇论文了,我想知道我和同年级同专业第一梯队的人究竟差距多大。其特等奖答辩视频可以在b站上找到。
论文名
Deep Progressive Reinforcement Learning for Skeleton-based Action Recognition
作者
清华大学自动化系田毅
论文地址
摘要渣译
在这篇文章中,我们提出了一种用于骨架体视频动作提取的深度渐进强化学习模型,其目的是为动作识别提取视频中大信息量的帧和去除少信息量的帧。由于每个视频可选择的代表性帧很多,我们把帧的选取视作使用深度强化学习的渐进过程,在这个过程中我们将两个重要因素加入选帧的考量:(1)选取帧的质量(2)选取帧与整个视频间的关系。进一步说,考虑到人体固有的拓扑结构是基于图形的结构,其中顶点和边分别代表关节和骨骼,我们使用基于图形的卷积神经网络来捕捉关节之间的依赖关系,以进行动作识别。在三个常用指标上我们的研究都取得了有竞争力的性能。
前言
怎么运作?
考虑到人体节点的视频,我们首先通过已经被提出的深度渐进强化学习模型训练过的一种帧蒸馏网络(frame distillation network) ,来提取关键的帧。之后我们使用保留了人体关节之间的依赖关系的一种基于图像的卷积神经网络,来使用关键帧进行动作识别。


图的顶点表示为蓝点,其中包含人体关节的三维坐标,而边缘反映关节之间的关系,可以将其分类为内在依赖性(即物理连接)和外在依赖性(即物理关系)。以动作’拍手’为例,内在依赖关系被建议为黑色实线,而外在依赖关系为橙色虚线。
其他
1.动作识别的作用。比较传统视频,骨骼序列的优点(which are robust to variations of viewpoints, body scales and motion speeds)
2.RNN的模型具有模拟时间依赖性的能力,但是在实践中难以训练堆叠的RNN。
3.CNN的模型捕获较低层的相邻帧与较高层的长期依赖关系,基于骨架的动作识别的大多数基于CNN的方法认为序列中的所有帧同样重要,不能关注最具代表性的帧。
4.为了寻找序列中信息最丰富的框架,作者提出了深度渐进强化学习(DPRL)方法。
5.大多数基于CNN的方法采用欧几里德结构来模拟关节,这忽略了人体的内在拓扑。为了解决这个问题,作者将关节及其依赖关系建模为图形。图形的顶点包含身体关节的3D坐标,而相邻矩阵捕获它们的关系。作者将关节图视为位于非欧几里德空间。建议看一下链接的第四部分。
6.利用基于图的卷积神经网络(GCNN)来学习关节之间的空间依赖性。
7.利用三种基于骨架的动作识别数据集进行效果评估,其中竞争性实验结果证明了我们方法的有效性。
近期研究
Skeleton-based Action Recognition: There have been a number of skeleton-based action recognition methods in recent years, and they can be mainly classified into two categories: hand-crafted feature based and deep learning feature based.
基于骨架的动作识别:近年来已经有许多基于骨架的动作识别方法,它们主要分为两类:手工制作的特征和基于深度学习特征
手工制作特征:
1.李代数中实现时间建模和分类法
2.朴素贝叶斯加权法
3.内核的张量表示法
4.无向完整的图形法
深度学习特征:
1.骨图转彩图,CNN分类法
2.双流CNN架构法(结合关节的位置和速度信息,无重点帧)
3.共现特征学习的正则化LSTM模型法
4.一种spatio-temporal attention model,提出不同帧和不同关节,不同的权重
5.提出trust gate来解决骨架数据中的噪声问题
6.RNN与时空图结合,对脊柱,手臂和腿的关系进行建模
本文:将人体的每个关节都作为顶点
之后说了一下强化学习的发展。但强化学习在行动识别方面几乎没有取得任何进展,特别是基于骨架的行动识别。同类型研究中动作仅影响一个帧,作者一次处理所有选择帧的调整。
方法
1.Graph-based Representation Learning
我们构建了一个图形Gs(x,W)来模拟每个单独的人体帧,其中x包含N个关节的3D坐标,W是N×N加权邻接矩阵:
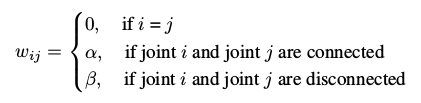
内在依赖性α指的是关节的物理连接,参数β来模拟外在关系。
例如,左手和右手在身体上是断开的,但是他们的关系对于识别动作’拍手’具有显着的重要性,我们使用参数β来模拟外在关系。
最终输入GCNN的张量是:
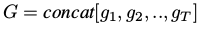
每一个g为一帧的信息,即上文的Gs,最后输入给常见的3D-CNN。
2.Deep Progressive Reinforcement Learning
关键帧的选择被制定为马尔可夫决策过程(MDP),在此基础上我们使用强化学习来在每次迭代时细化帧。图3提供了该过程的示意图,该图基于FDNet实现,如图4所示。与提供奖励和更新其状态的环境进行交互的媒介,通过最大化总折扣奖励来学习以调整所选择的帧,最终得到给定数量m的最可区分的帧。
 图3.逐步选择基于骨架的视频中的关键帧的过程。首先统一采样几个帧,逐步调整之后,我们获得视频中信息量最大的帧。由FDNet选定框架的下一步“向左移动”,“保持相同”或“向右移动”。
图3.逐步选择基于骨架的视频中的关键帧的过程。首先统一采样几个帧,逐步调整之后,我们获得视频中信息量最大的帧。由FDNet选定框架的下一步“向左移动”,“保持相同”或“向右移动”。

图4.用于调整基于骨架的视频中关键帧的FDNet架构。 FDNet分别获取Sa和Sb的输入,其中Sa包含整个视频F的信息以及所选择的帧M,并且Sb是所选索引的f维二元掩模,其中f元素为 1,其余为0。然后,Sa由3个卷积层的CNN处理,其中内核大小为3×3,并且完全连接层(fc1),而Sb通过fc2。这两个部分的提取特征在被送入fc3之前被连接起来。然后使用Softmax函数来规范fc3的输出。输出是一组操作,指导下一步的精炼过程。
3.Combination of GCNN and FDNet
对于训练集中的所有基于骨架的视频,我们首先均匀地对其帧进行采样,以获得固定大小的序列。 这些序列用于训练GCNN以捕获空间域中的联合依赖性。 然后,我们修复GCNN中的参数以训练FDNet并更新临时域中每个视频的选定帧,这些帧用于优化GCNN。 这两个模型相互促进,因为GCNN为FDNet提供奖励,FDNet选择关键帧来修整GCNN。 GCNN越好,奖励就越准确。 所选帧的质量越高,GCNN就越好。 在测试时,每个视频通过FDNet产生其信息帧的相应序列,最终将其发送到GCNN以提供动作标签。
实践
1.数据集:NTU+RGBD Dataset (NTU) ; SYSU-3D Dataset (SYSU) ; UT-Kinect Dataset (UT)
2.我们将每个视频组织为T×N×3张量,其中T表示均匀采样的帧,N是身体关节的数量,3表示关节的3D坐标。我们根据经验将T设置为30,并且对于NTU,SYSU和UT,N分别等于25,20和20。然后,采用具有3个卷积层和3个完全连接层的基于CNN的模型来识别动作。 3个卷积层的核心大小为3×3,通道数为32,64和128.在每个卷积层后,我们采用了3个最大池化层,大小为2×2。
3.而网络架构是在两个Nvidia GTX 1080 GPU上构建的。这两个子网络都是从头开始训练的。对于GCNN,我们选择ELU 作为激活函数,并将丢失率设置为0.5。基于图形的卷积层的knelnel大小设置为5,并且对于NTU,SYSU和UT数据集,batchsize分别设置为64,16,8。
4.与其他论文的结果比较。
句式总结
In this paper, we propose XXX for XXX, which aims to XXX.
工作与目的
Since XXX, we model XXX as a XXX process, during which we XXX by taking two important factors into account:
问题与解决
Our approach achieves very competitive performance on three widely used benchmarks.
效果的提出
The pipeline of our proposed method for XXX
工作的过程
deal with A for B
使用A解决B
aN×Nweighted adjacency matrix
一个N×N的加权邻接矩阵