前言
本次实验研究完整代码 ->进入 From Github
一.CAPTCHA
提到验证码,生活中各种各样的平台都会在用户常规操作管理下实行验证码机制。对于我浅显的理解,一是区分人与机器的认证交互,在有行为发生的情况下,我们要判断是否是用户主观操作,本意所为,因此加上验证码机制会使得我们的信息数据和资金数字财产得到一定基础屏障。二是对于验证码,尤其为语言验证码,如汉文字验证码和其他语言字符串验证码,对于国外的一些恶意人员也会具有一定作用的防护屏障等等。
那么这个CAPTCHA,在生活工作中的重大存在意义呢?
Completely Automated Public Turing test to Tell Computers and Humans Apart
译为全自动区分计算机和人类的图灵测试
- 其测试内容,主要是利用人类脑中的辨别能力,对一些难以被计算机识别的字符等图像进行辨认,以此用这些 “计算机不能完成”的行为,从根本辨别出“人” 和 “计算机”
。而基于这种测试的程序,必须能生成并评价人类能很容易通过,但计算机却通不过的测试。因此CAPTCHA通俗点的名字,才叫人机验证。- reCAPTCHA,是在原 CAPTCHA 测试基础上进行延展的技术,相比传统的人机验证,其本质更像是 “让计算机求助于人类”,在 2009 年被 Google 收购,并以此基础进行再开发。
- 它实际上由 “NoCAPTCHA” 和 “reCAPTCHA” 两部分组成,其一是一个简单的认证系统,上面只有一句 “我不是机器人”和一个等你打勾的方框,当你确认后,用一系列 “风险分析引擎” 对用户进行无缝分析,并以此来判断你是否是一个 “真人” 。
- 很多网站都在注册、评论系统中使用验证码,以防止别人恶意注册虚假账号或发布垃圾评论。
二.研究内容
随着人工智能的兴起,在计算机视觉(CV)领域上也有重大的突破进展,运用深度神经网络进行图像检测和研发并投入使用的算法已相当成熟,不管是从高校、科研处等教育领域,还是在工业化商用化领域上都投以大量的研制算法用来处理实际问题。这些研发出来的系统模块可以从不同的角度去理解和识别连续动作图像画面中的人和物体。
以往从图像数据中抽取我们认为有价值的信息会很难,而这些图像包含大量原始数据,图像的标准编码单元(像素)提供的信息量很少。图像,尤其是照片可能存在一些难以解决的问题,比如模糊不清、离目标太近、光线很暗或太亮、比例失真、残缺、扭曲等,这会增加计算机系统抽取有用信息的难度。
基于神经网络识别图像中的字母,从而去自动识别验证码。在PycharmIDE,用Python进行数据采集、数据处理、图像识别,并运用网络迭代计算来破解验证码。
- 对PIL/Pillow、Ntlk、Numpy、skimage、sklearn的掌握。
- 创建验证码和字母数据集。
- 使用神经网络进行分类任务。
- 多层感知机。
- 图片英文单词的分割和识别。
- 使用列文斯坦编辑距离提高识别率。
- 进行优化处理提升运作效果。
三.数据集的采集
数据资源来自开源字库(Open Font Library),Download所需字体文件:http://openfontlibrary.org/en/font/bretan
本实验研究使用的是Coval-Black.ttf
四.训练研究过程
-
导入相关模块:
import numpy as np import nltk from nltk.corpus import words from nltk.metrics import edit_distance from matplotlib import pyplot as plt from PIL import Image, ImageDraw, ImageFont from skimage import transform as tf from skimage.transform import resize from skimage.measure import label, regionprops from sklearn.utils import check_random_state from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import OneHotEncoder from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from operator import itemgetter import warnings warnings.filterwarnings("ignore") -
创建用于生成验证码的基础函数
这个函数接收一个单词和错切值(通常在0到0.5之间),返回用numpy数组格式表示的图像。该函数还提供指定图像大小的参数,因为后面还会用它生成只包含单个字母的测试数据。
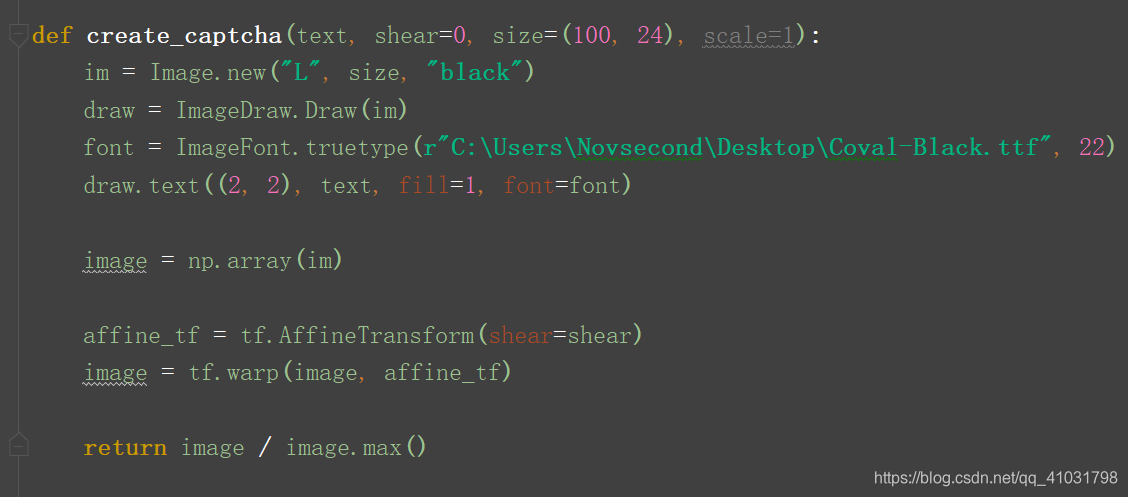
- 用字母’L’来生成一张黑白图像,为
ImageDraw类初始化一个实例。 - 指定验证码文字所使用的字体。这里用到Coval-Black.ttf,
r指向文件存放位置。 - 把PIL图像转换为
numpy数组,以便用scikit-image库为图像添加错切变化效果。 - scikit-image
大部分计算都使用numpy`数组格式。 - 最后
return image / image.max()对图像特征进行归一化处理,确保特征值落在0到1之间。
- 使用pyplot绘制图像

效果图片所示: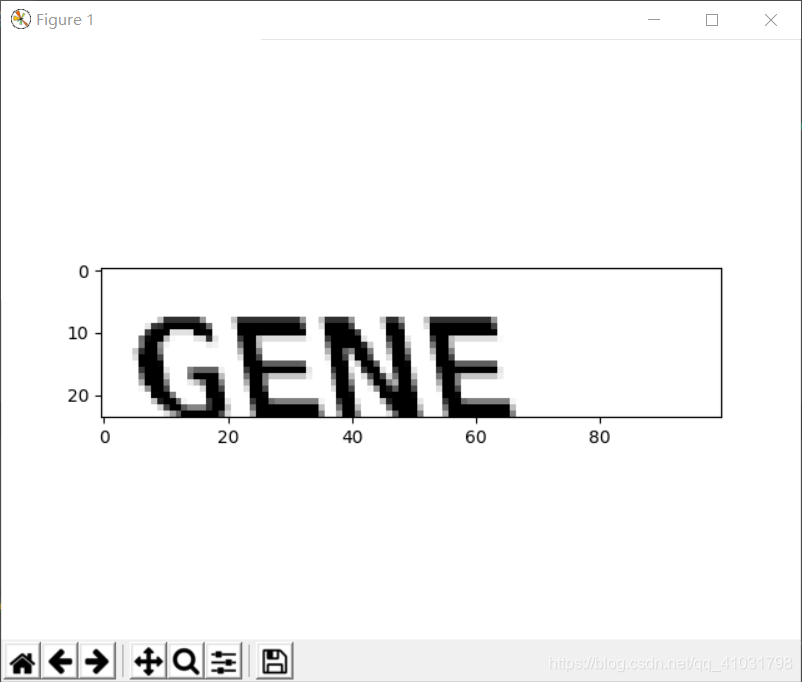
- 分割单词
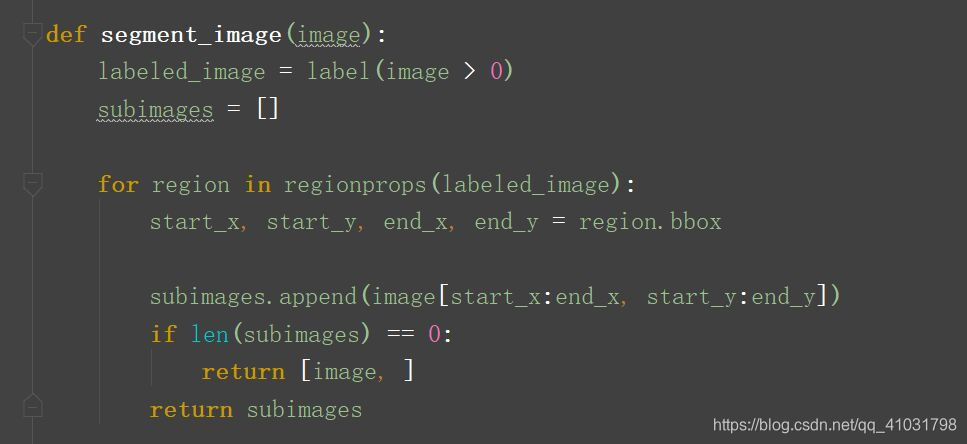
创建一个函数,寻找图像中连续的黑色像素,抽取它们作为新的小图像。 - 创建训练集

-
指定随机状态值,创建字母列表,指定错切值。

-
调用函数生成一条训练数据,用pyplot显示图像。
效果图片所示:
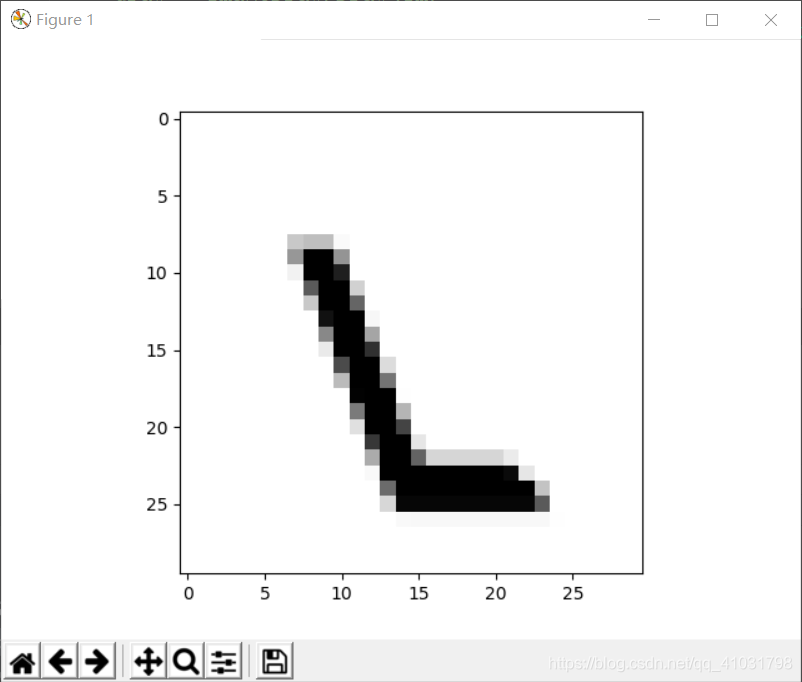
6.调用更多次数函数生成数据
- 调用更多次数的该函数,生成足够的训练数据。
- 把这些数据传入到numpy的数组里。
- 在
sklearn包中,OneHotEncoder函数非常实用,可以实现将分类特征的每个元素转化为一个可以用来计算的值。
String字符串转换成索引IndexDouble
索引转换成SparseVector
OneHotEncoder = String > IndexDouble > SparseVector
更多的了解OneHotEncoder
y=y.todense()将稀疏矩阵转换为密集矩阵。(相关库不支持稀疏矩阵)

7.根据抽取方法调整训练数据集
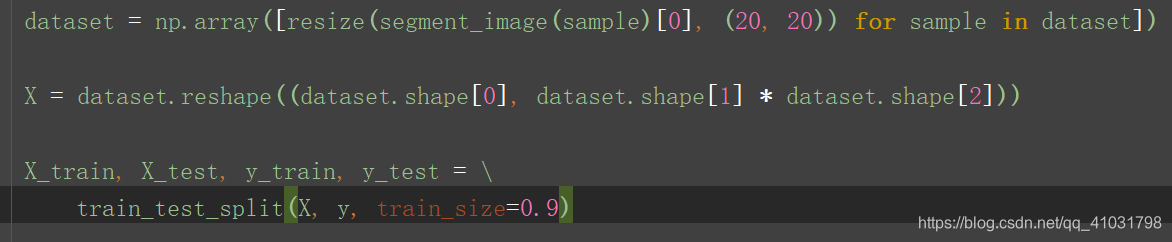
- 在训练集上运行分割函数,返回分割后得到的字母图像 。
- 用到
scikit-image库中的resize函数。