版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u010498753/article/details/84936704
文章目录
1.创建数据库
11.【推荐】库名与应用名称尽量一致。
2. 创建表
14.【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明: 如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
2.1 创建名称
2.【强制】表名、字段名必须使用小写字母或数字, 禁止出现数字开头,禁止两个下划线中间只
出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
说明: MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、
表名、字段名,都不允许出现任何大写字母,避免节外生枝。
3. 【强制】表名不使用复数名词。
10.【推荐】表的命名最好是加上“业务名称_表的作用”。
2.2 创建索引
11.【参考】创建索引时避免有如下极端误解:
1) 宁滥勿缺。 认为一个查询就需要建一个索引。
2) 宁缺勿滥。 认为索引会消耗空间、严重拖慢更新和新增速度。
3) 抵制惟一索引。 认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。
3.创建字段
13.【推荐】字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循:
1) 不是频繁修改的字段。
2) 不是 varchar 超长字段,更不能是 text 字段。
正例: 商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存
储类目名称,避免关联查询
6. 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:以学生和成绩的关系为例,学生表中的 student_id是主键,那么成绩表中的 student_id
则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新, 即为
级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群; 级联更新是强阻
塞,存在数据库更新风暴的风险; 外键影响数据库的插入速度。
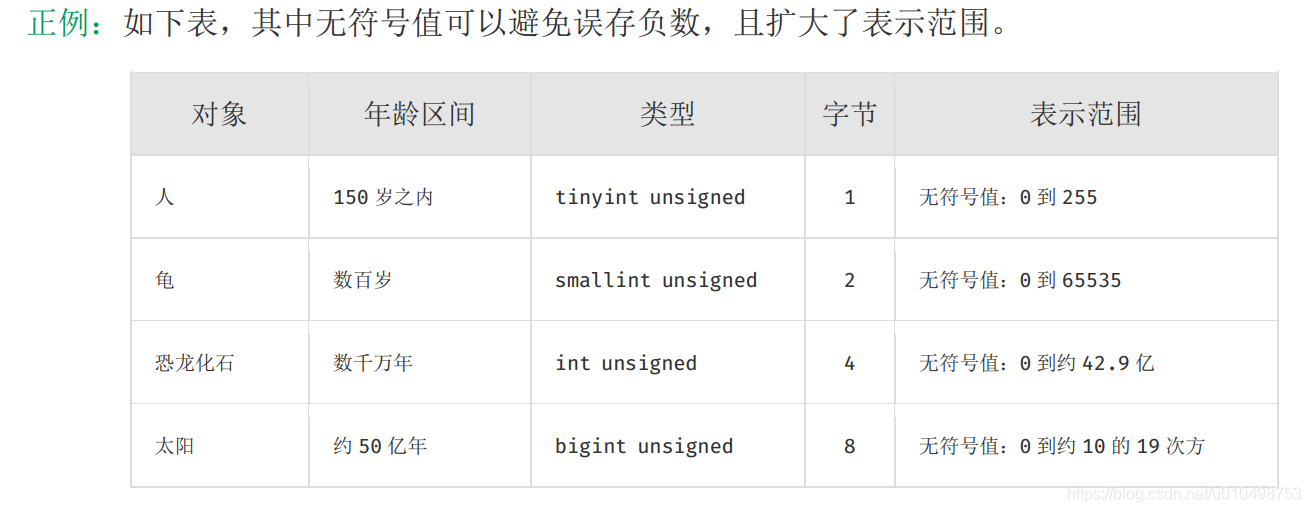
10.【参考】 如果有国际化需要,所有的字符存储与表示,均以 utf-8 编码,注意字符统计函数
的区别。
说明:
SELECT LENGTH("轻松工作"); 返回为 12
SELECT CHARACTER_LENGTH("轻松工作"); 返回为 4
如果需要存储表情,那么选择 utf8mb4 来进行存储,注意它与 utf-8 编码的区别。
3.1 创建名称
1. 【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是, 0 表示否)。
5. 【强制】 主键索引名为 pk_字段名; 唯一索引名为 uk_字段名; 普通索引名则为 idx_字段名。
9. 【强制】表必备三字段: id, gmt_create, gmt_modified
12.【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
3.2 创建类型
6. 【强制】小数类型为 decimal,禁止使用 float 和 double。
7. 【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
8. 【强制】 varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为text,独立出来一张表,用主键来对应,避免影响其它字段索引效率
15. 【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检
索速度。
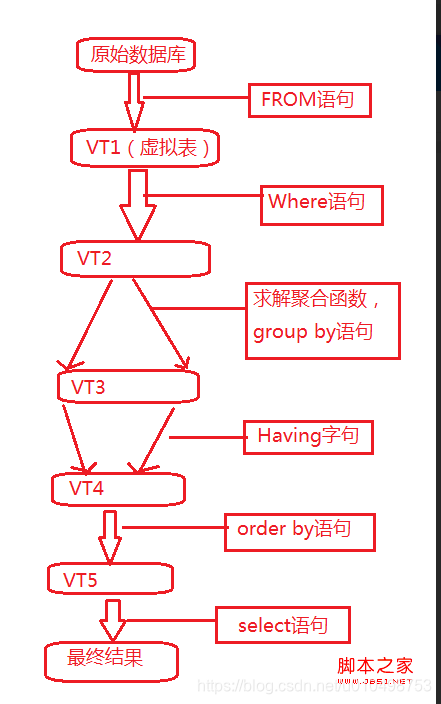
4.sql的运行流程
4.1解析
4.2编写sql
4. 【强制】禁用保留字,如 desc、 range、 match、 delayed 等, 请参考 MySQL 官方保留字。
4.2.1 from 表
2. 【强制】超过三个表禁止 join。需要 join 的字段,数据类型必须绝对一致; 多表关联查询时,
保证被关联的字段需要有索引。
说明: 即使双表 join 也要注意表索引、 SQL 性能。
4.2.2where
4. 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明: 索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索
引
9. 【推荐】 in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控
制在 1000 个之内。
4.2.3 聚合函数
1. 【强制】不要使用 count(列名)或 count(常量)来替代 count(*), count(*)是 SQL92 定义的
标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明: count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2. 【强制】 count(distinct col) 计算该列除 NULL 之外的不重复行数, 注意 count(distinct
col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
3. 【强制】当某一列的值全是 NULL 时, count(col)的返回结果为 0,但 sum(col)的返回结果为
NULL,因此使用 sum()时需注意 NPE 问题。
正例: 可以使用如下方式来避免 sum 的 NPE 问题: SELECT IF(ISNULL(SUM(g)),0,SUM(g))
FROM table;
5. 【强制】 在代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
4.2.4 group-by
4.2.5 having
4.2.6 order by
5. 【推荐】如果有 order by 的场景,请注意利用索引的有序性。 order by 最后的字段是组合
索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
正例: where a=? and b=? order by c; 索引: a_b_c
反例: 索引中有范围查找,那么索引有序性无法利用,如: WHERE a>10 ORDER BY b; 索引
a_b 无法排序。
4.2.6 select
8. 【推荐】 SQL 性能优化的目标:至少要达到 range 级别, 要求是 ref 级别, 如果可以是 consts
最好。
说明:
1) consts 单表中最多只有一个匹配行(主键或者唯一索引) ,在优化阶段即可读取到数据。
2) ref 指的是使用普通的索引(normal index) 。
3) range 对索引进行范围检索。
反例: explain 表的结果, type=index,索引物理文件全扫描,速度非常慢,这个 index 级
别比较 range 还低,与全表扫描是小巫见大巫。
1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明: 1) 增加查询分析器解析成本。 2) 增减字段容易与 resultMap 配置不一致。 3)无用字
段增加网络消耗,尤其是 text 类型的字段。
4.2.7 update 与 delete
11.【参考】 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE
无事务且不触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句。
说明: TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同
8.【强制】数据订正(特别是删除、 修改记录操作) 时,要先 select,避免出现误删除,确认
无误才能执行更新语句。