准备工作
Hadoop环境搭建:
1.主机名
2.防火墙关闭
3.免密登录
(ssh-keygen
按4个回车后
ssh-copy-id root@虚拟机主机ip)
4.Jdk(具体安装步骤可以看上一篇文章)
正式搭建步骤
开启虚拟机,进入hadoop目录下
1、vim hadoop-env.sh
1.1、Line 25: 修改JAVA_HOME=jdk的安装目录

2.2、Line 33:修改HADOOP_CONF_DIR=hadoop配置文件所在的目录

2、编辑 core-site.xml
core-site.xml 主要配置的是 namenode所在的地址 及hadoop在运行过程中产生的数据存放的临时目录
vim core-site.xml
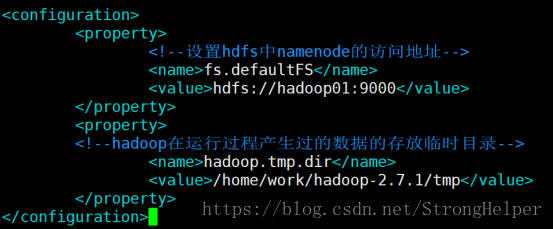
<configuration>
<property>
<!--设置hdfs中namenode的访问地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--hadoop在运行过程产生过的数据的存放临时目录-->
<name>hadoop.tmp.dir</name>
<value>/home/work/hadoop-2.7.1/tmp</value>
</property>
</configuration>3、编辑hdfs-site.xml
hdfs-site.xml针对于hadoop中文件系统配置,主要配置块的副本数及hdfs中权限操作
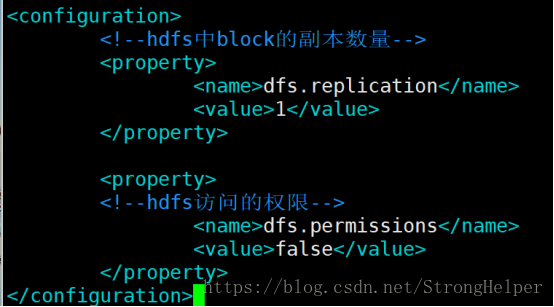
<configuration>
<!--hdfs中block的副本数量-->
<property>
<name>dfs.relipcation</name>
<value>1</value>
</property>
<property>
<!--hdfs访问的权限-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>4、mapred-site.xml
主要配置 mapreduce运行于yarn资源协调框架中
mapred-site.xml这个在hadoop的配置中没有直接存在,将mapred-site.xml.template拷贝为mapred-site.xml,然后对mapred-site.xml进行编辑。
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!--指定mapreduce运行时调用yarn进行资源协调-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
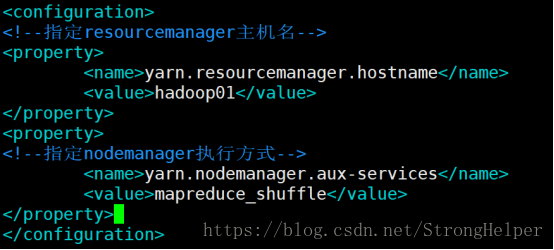
</configuration>5、编辑yarn-site.xml
Yarn-site.xml指定资源协调的方式,其中:指定resourcemanager的主机,指定nodemanager的执行方式

<configuration>
<!--指定resourcemanager主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--指定nodemanager执行方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6、编辑slaves
指定真正数据存储的机器(datanode)

7、配置hadoop环境变量
注意:只要提到linux中系统环境变量,就是对/etc/profile进行编辑。
vim /etc/profile
bin sbin

`
JAVA_HOME=/home/work/jdk1.8.0_65
HADOOP_HOME=/home/work/hadoop-2.7.1
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME PATH HADOOP_HOME
利用:
source /etc/profile 保存并让配置立即生效。`
Hadoop格式化操作:
由于配置了hadoop的环境变量,可以任何目录下执行:
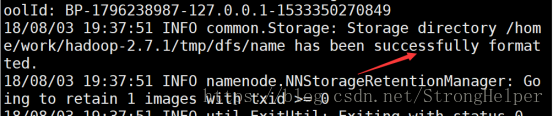
hadoop namenode -format
若没有配置该环境变量,需要到 hadoop安装目录的bin目录下执行,其中./不能省略。
./hadoop namenode -format
如果出现如下标识,代表格式化成功。。。
启动hadoop
由于配置了hadoop的环境变量,可以任何目录下执行:
start-all.sh
若没有配置该环境变量,需要到 hadoop安装目录的sbin目录下执行,其中./不能省略。
./start-all.sh
停止命令:
stop-all.sh
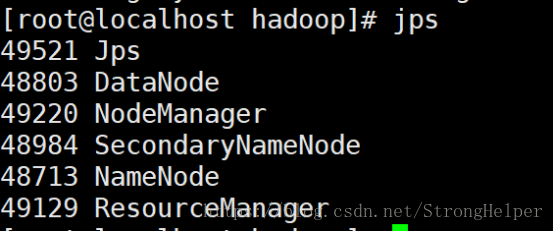
查看进程
利用jps命令查看,如果有如下进程,代表启动成功。
如果出现错误,请查看错误日志追踪错误来源。