之前写一个库时用到了字典树,可以很方便地进行归类,姓名放进去的时候就会对前部分的字符逐个归类,从而在全局深搜的时候得到的字符串便是按字母排序过的有序表。
于是我突发奇想——0000、0100、0001、1000这个序列,在进入一个左子树代表0,右子树代表1的二叉树为基础的字典树,然后进行左子树为开头的深搜后,就会出现0000、0001、0100、1000的从小到大有序序列,而且如果改为右子树为手的话,就可以变成从大到小的有序序列,并且由于树的独特结构,归类过程可以把数字几何分割成多份轻松地进行多线程排序增强排序效率。那么我们可否把int32的32bit二进制作为等长字符串进行基于此原理的排序呢?答案是可以的,但是为了避免不正常bit串引起的1000、101、1011的非有序排列,因此需要把所有进入的数据前面补0补够32bit。
然后,排序的数里面可能会有重复的数字,所以最后的结点要加一个重复序号。
那么数据结构就如下所示:

根据数据创建字典树和深搜字典树的算法可以参考我之前写的字典树文章:
https://blog.csdn.net/cjzjolly/article/details/83548237
具体实现代码如下:
package com.test.multiTreeSort;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class MultiTreeSort {
private static TreeNode head = new TreeNode();
private static void addNum(TreeNode node, char[] numStr){
for(int i = 0; i < numStr.length; i++) {
if(numStr[i] == '0') {
if(node.left == null) {
node.left = new TreeNode();
}
node = node.left;
} else {
if(node.right == null) {
node.right = new TreeNode();
}
node = node.right;
}
}
node.count ++;
}
private static char numData[] = new char[34];
private static int layer = 0;
private static void readAll(TreeNode node){
if(node != null) {
if(node.count > 0) {
int firstOneIndex = 0;
for(int i = 0; i < numData.length; i++) {
if(numData[i] != '0'){
firstOneIndex = i;
break;
}
}
char realNumData[] = new char[numData.length - firstOneIndex];
for(int i = firstOneIndex, j = 0; i < numData.length; i++, j++) {
realNumData[j] = numData[i];
}
String numDataStr = new String(realNumData);
try{
for(int i = 0; i < node.count; i++) {
System.out.println("numDataStr:" + Integer.parseInt(numDataStr.substring(0, numDataStr.length() - 2), 2));
}
} catch(Exception e){
}
// System.out.println("numDataStr:" + numData);
}
numData[layer++] = '1';
readAll(node.right);
numData[layer--] = 0;
numData[layer++] = '0';
readAll(node.left);
numData[layer--] = 0;
}
}
private static int finishedThread = 0;
private static int threadCount = 1;
public static void multiTreeSort(){
try {
FileInputStream fis = new FileInputStream(new File("F:\\杂物\\biTreeSort\\data.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(fis));
String content;
final List<char[]> contentList = new ArrayList<>();
while((content = br.readLine()) != null) {
int data = Integer.valueOf(content);
char dataBinStr[] = String.format("%32s", Integer.toBinaryString(data)).toCharArray();
for(int i = 0; i < dataBinStr.length; i++) {
if(dataBinStr[i] == ' '){
dataBinStr[i] = '0';
}
}
contentList.add(dataBinStr);
//System.out.println("data:" + new String(dataBinStr));
}
long startTime = System.currentTimeMillis();
if(contentList.size() > 10000) {
final int size = contentList.size();
finishedThread = 0;
for(int i = 0; i < threadCount; i++){
final float start = (float) i / (float) threadCount;
final float end = (float) (i + 1) / (float) threadCount;
new Thread(new Runnable() {
@Override
public void run() {
for(int j = (int) (start * size); j < end * size; j++){
addNum(head, contentList.get(j));
}
finishedThread++;
System.out.println("完成:" + finishedThread + ",start:" + (int) (start * size) + ",end:" + (int)(end * size - 1));
}
}).start();
}
while(finishedThread < threadCount){
Thread.sleep(1);
}
} else {
for(int j = 0; j < contentList.size(); j++){
addNum(head, contentList.get(j));
}
}
System.out.println(String.format("排序%d条数据,用时%d ms", contentList.size(), System.currentTimeMillis() - startTime));
// readAll(head);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
对比组:
package com.test.multiTreeSort;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Traditional {
public static void tradionalSort(){
try {
FileInputStream fis = new FileInputStream(new File("F:\\杂物\\biTreeSort\\data.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(fis));
String content;
final List<Integer> contentList = new ArrayList<>();
while((content = br.readLine()) != null) {
int data = Integer.valueOf(content);
contentList.add(data);
}
long startTime = System.currentTimeMillis();
Collections.sort(contentList);
System.out.println(String.format("排序%d条数据,用时%d ms", contentList.size(), System.currentTimeMillis() - startTime));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Main类:
package com.test.multiTreeSort;
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
System.out.println("我的方式:");
MultiTreeSort.multiTreeSort();
System.out.println("JAVA自带排序:");
Traditional.tradionalSort();
}
}
测试结果:
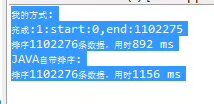
可以看到其对比Java自身Collections的sort排序,速度是要快上一点的,尤其是在多线程的环境下优势较大,但消耗空间非常多,也是一种空间换时间的思路了