1 robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
如:
淘宝网:https://www.taobao.com/robots.txt
User-agent: Baiduspider Allow: /article Allow: /oshtml Disallow: /product/ Disallow: / User-Agent: Googlebot Allow: /article Allow: /oshtml Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: /
...
腾讯网:http://www.qq.com/robots.txt
User-agent: * Disallow: Sitemap: http://www.qq.com/sitemap_index.xml
豆瓣网:https://www.douban.com/robots.txt
马蜂窝:http://www.mafengwo.cn/robots.txt
搜索引擎和DNS解析服务商(DNSPod)合作,新网站域名将被迅速抓取。但搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件内容,如标注为nofollow的链接,或者是Robots协议;另一种则是通过网站的站长主动对搜索引擎提交的网址,搜索引擎则会在接下来派出“蜘蛛”,对该网站进行爬取。
2 网站地图sitemap
网站地图sitemap是网站所有链接的容器;是依据网站的结构、框架、内容生长的导航页面文件,一般存放在根目录下并命名为sitemap。
很多网站的链接层次较深,蜘蛛很难抓取到,网站地图可方便搜索引擎蜘蛛抓取网站页面,增加网站重要内容页面的收录,以便清晰了解网站的架构
网站地图sitemap有两种形式
2.1 HTML
HTML版本的网站地图,也即网站上所有页面的链接,但对于规模较大的网站来说,一种办法是网站地图只列出网站最主要的链接,如一级分类、二级分类;第二种办法是将网站地图分成几个文件,主网站地图列出次级网站的链接,次级网站列出部分页面链接
2.2 XML
XML版本网站地图是由Google首先提出的,其是由XML标签组成的,文件本身必须是utf-8编码,网站地图文件实际上就是列出网站需要被收录页面的URL,最简单的网站地图可以是一个纯文本,文件只要列出页面的URL,一行列一个URL,搜索引擎就能抓取并理解文件内容
也可以使用第三方工具生成某网站的sitemap ,例如小爬虫sitemap网站地图生成工具
3 估算网站的大小
可以使用搜索引擎来估算网站大小,如搜索时添加site。
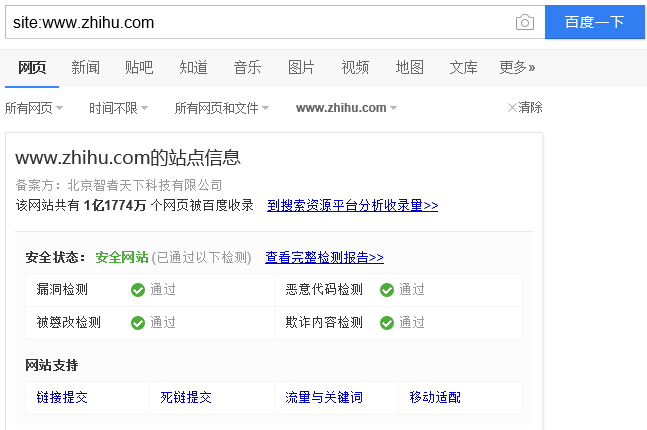
该方法仅是通过百度搜索引擎大致估算网站大小,因有些网站对爬虫的限制,以及搜索引擎本身爬取数据技术的局限性,所以该数据仅是估算值,是估算网站体量量级的经验值。
注:百度只能做一级页面的统计,Google可以做到二级页面的统计
4 识别网站中用了何种技术
为了更好地了解网站,抓取该网站的信息,我们可先了解一下该网站大致所使用的技术架构
builtwith
安装:(windows)pip install bulitwith; (Linux)sudo pip install builtith
使用:在python交互环境下,输入:
import builtwith
builtwith.parse("http://www.sina.com.cn")
5 确定网站的所有着
有时候需要追寻网站的所有者是谁,可以通过python-whois软件查看
whois
安装:(windows)pip install python-whois
使用:在python交互环境下输入:
import whois
whois.whois("http://www.sina.com.cn")