文章目录
Request模块简介
我们可以在浏览器中抓取到这些请求与响应的内容,那么我们可以“伪造”请求吗?也就是不再通过浏览器发送这些数据,而是通过python来模拟浏览器发送请求。答案是可行的。而Request模块就可以完成这种功能。
Requests模块就是Python实现的简单易用的HTTP库
还有其他库吗?回答也是肯定的,例如urllib,urllib2,httplib,httplib2等模块。但是目前来说Requests模块是最流行的。而且也是做好用的模块
发送请求:
使用Requests发送网络请求非常简单,一开始要导入requests模块
import requests
然后,尝试获取某个网页,在本例中,我们来获取搜狗网页首页:
r=requests.get('https://www.sogou.com/')
现在,我们有一个名为r 的Response对象,我们可以从这个对象中获取我们想要的信息。例如:打印出返回的内容
r.text
实际上,如果我们在浏览器上打开这个网址,右键选择“查看网页源代码”,你会发现,跟我们刚才打印出来的是一模一样(如果没有反爬或者网站是静态网站)。也就是说,上面几行代码已经帮我们把搜狗的首页的全部源代码爬了下来。
拼接网址:
1.
import requests
url='https://www.sogou.com/web?query='+'挖掘机小王子'
response=request.get(url)
print(response.text)
import requests
url='https://www.sogou.com/web?‘
param={
'query' : '挖掘机小王子'
}
response=request.get(url,params=param)
print(response.text)
注意:字典里的值为None的键都不会被添加到URL的查询字符串中
拓展知识:
你还可以将一个列表传入:
import requests
payload={
’key1‘:'value1','key2':['value2','value3']}
r=requests.get('http://httpbin.org/get',params=payload)
print(r.url)
打印的结果是: http://httpbin.org/get?key1=vavlue1&key2=value2&key2=value3
文本响应内容
我们能读取服务器响应的内容。在此之前我们使用r.text来访问服务器返回给我们的内容。并且我们可以看到返回的内容,神奇的是我们竟然没有做任何关于编码解码的事情。其实
requests会自动解码来自服务器的内容。大多数UNICODE字符集都能被无缝地解码。
请求发出后,Requests会基于HTTP头部队响应的编码作出有根据的推测。当你访问r.text之时,requests会使用其推测的文本编码。你可以找出Requests使用了什么编码,并且能够使用e.encoding属性来改变它:
r.encoding
结果是’utf-8’
r.encoding='gb2312'
如果你改变了编码,每当你访问了r.text,Request都将会使用r.encoding的新值
HTML页面是可以设置编码信息的,可以查看该编码信息,然后设置r.encoding为相应的编码
这样就能使用正确的编码解析r.text了。而网页的编码可以在浏览器中去查看
二进制:
Requests会自动为你解码gzip和deflate传输编码的响应数据
例如对于图片信息,可以很方便的保存到文件中。对于图片,mp3,视频等数据,往往要使用二进制的方式读取
import requests
url='https://pic.sogou.com/pics/recompic/detail.jsp?category=%E7%BE%8E%E5%A5%B3&tag=%E5%86%99%E7%9C%9F#1%263976741'
r=requests.get(url)
print(r.content)
with open('baidu.png','wb') as f:
f.write(r.content)
1.r.content是二进制信息
2.open()打开文件对象 with是上下文管理器,它可以帮我们 自动关闭文件
f=open()
f.write()
f.close()
3.as是取一个别名,昵称
4.wb w是写入,即使打开一个文件用来写入数据,b是写入二进制数据
r是读取数据
a是追加数据,不覆盖数据
gbk gb2312
定制请求头:
建立网站的最终目的是为了让人来访问,其实几乎每个网站都不欢迎爬虫。甚至现在越来越多的网站发现对方是爬虫程序的时候就会 直接禁止该爬虫访问。也就是不会返回给爬虫任何信息,有的会返回提示:您当前属于非法访问!!
那网站服务器它怎么知道我们是爬虫呢?判断方式有很多,其中比较常见的就是通过请求头来判断。
在发送HTTP请求的时候浏览器都会带上请求头信息等,(程序发的时候默认不带的)如果我们的程序没有带上,或者带上的请求头信息是错误的,也就是不被服务器认可的,那么就会遭到服务器的拒绝。
请求头的验证也是最简单的反爬虫策略了
添加请求头
我们的应对方案就是尽可能的模拟浏览器的功能或者行为。既然浏览器有请求头的发送,那么我们的程序自然也应该加上。在Requests中我们通过headers参数添加请求头信息

imports requests
url=''
headers={
'User-Agent':' '
}
e=requests.get(url,headers=headers)
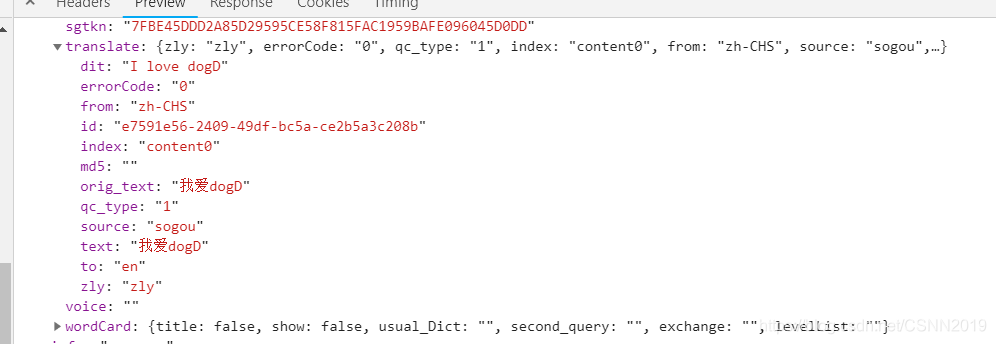
POST请求主要用来提交表单数据,然后服务器根据表单数据进行分析,再决定返回什么样的数据给客户端
Form表单提交数据
在Requests中发生POST请求也是比较容易的操作,要实现这个,只需简单地传递一个字典给data参数,你的数据字典在发出请求时会自动编码为表单形式:
payload={‘key1’:‘value1’,‘key2’:‘value2’}
r=requests.post{’’,data=payload}
当然Request中的post方法只是相对于get方法多了一个data参数,其他参数都是相似的,例如我们也可以为post中的网址添加查询字符串params参数,也可以像get方法一样添加headers参数等。
POST传递数据
Content-Type是传递数据的类型
1.Content-Type:application/x-www-form-urlencoded(Form形式)表单形式Form
传递数据的时候使用data参数,接受一个字典
2.Content-Type:application/json(json格式传递数据)
传递数据时候采用json参数,接受一个字典
也可以采用data=json.dumps()转化一下格式(将字典转换成字符串)
响应状态码
响应状态码可以很方便的查看我们的响应状态,我们可以检测响应状态码:
r=requests.get(‘https://httpbin.org/get’)
r.status_code
如果发送了一个错误请求(一个4XX 客户端错误,或者5XX 服务器错误响应),我们可以通过
response.raise_for_status()来抛出异常:
r=requests.get(‘https://httpbin.org/status/404’)
r.status_code #404
r.raise_for_status() #抛出异常
#异常错误
Traceback(most recent call last):
File “requests/models.py”,line 832,in raise_for_status
raise http_errorrequests.exceptions.HTTPError:404 Client Error
如果例子中r 的status_code是200,当我们调用raise_for_status()时,得到的是:
r.raise_for_status() #200
None
查看状态码 r.status_code 200 常用来判断,请求是否成功
响应头
我们可以查看以一个Python字典形式展示服务器的响应头
r.headers
#结果是
{‘content-encoding’:‘gzip’,‘transfer-encoding’:‘chunked’,‘connection’:‘close’}
但是这个字典比较特殊?:它是仅为HTTP头而生的,根据RFC2616(HTTP1.1协议),HTTP头部是大小写不敏感的
因此,我们可以使用任意大写形式来访问这些响应头字段:
r.headers[‘Content-Type’]#‘application/json’
r.headers.get(‘Content-Type’)#‘application/json’
响应头 r.headers 返回响应头信息 是个字典格式 可以用字典的方式访问
Cookie
现在的网站中有这样的一种网站类型,也就是需要用户注册以后,并且登陆才能访问的网站,或者说在不登录的情况下不能访问自己的私有数据,例如微博,微信等等
网站记录用户信息的方式就是通过客户端的Cookie值,例如:当我们在浏览器中保存账号和密码的同时,浏览器在我们的电脑上保存了我们的用户信息,并且在下次访问这个页面的时候会自动为我们加载cookie信息
在需要登录的网站中,浏览器将cookie中的信息发送出去,服务器验证cookie信息,确认登录。既然浏览器在发送请求的时候带有cookie信息,那么我们的程序同样也要携带cookie信息
cookie是当你访问某个站点或者特定页面的时候,留存在电脑里面的一段文本,它用于跟踪记录网站访问者的相关数据信息,比如,搜索偏好,行为点击,账号,密码等内容
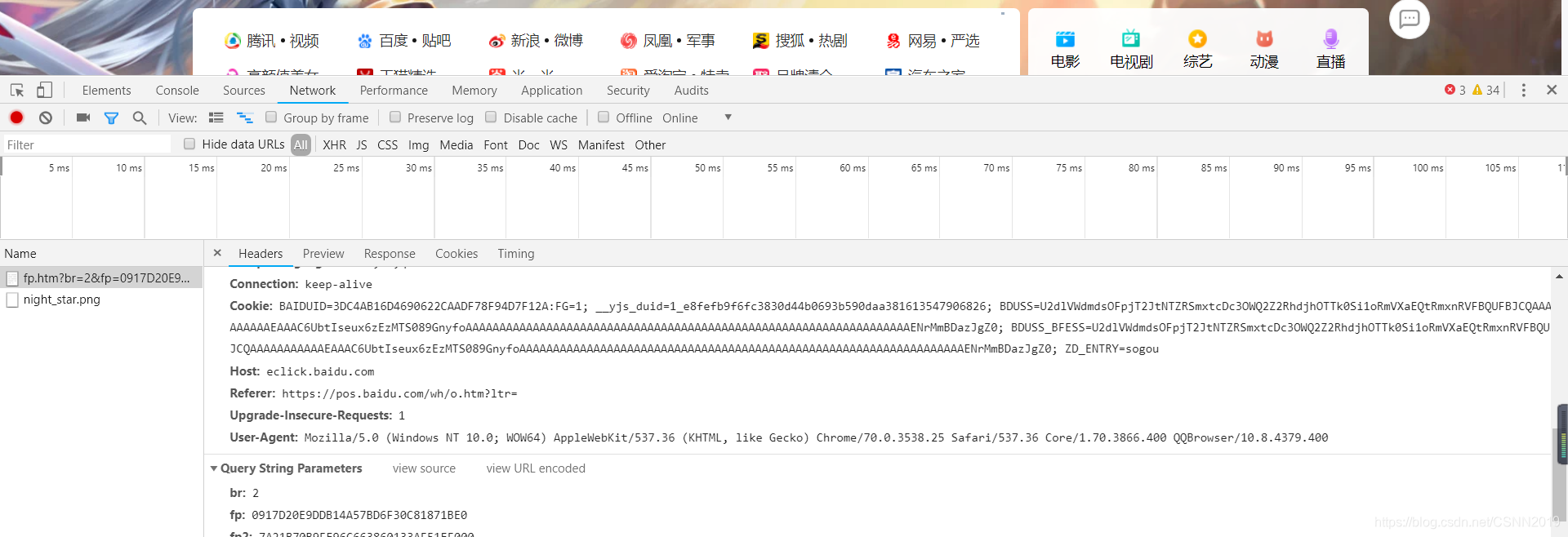
通常cookie值信息可以在浏览器中复制过来,放在headers中
headers={
‘Accept’:‘application/json,text/javascript,/;q=0.01’,
‘Accept-Encoding’:‘gzip,deflate,br’,
‘Connection’:‘keep-alive’
‘Cookie’:‘xxxxxxxxxxxxxxxxxxxxxx’ #浏览器中复制
…………………………
}
这样就可以随着请求头一起发出去了,当然requests也提供了cookies参数,供我们提交cookie信息:
import requests
url=xxx
cookies={
'Cookie':'你的cookie值'}
r=request.get(url,cookies=cookies)
B站访问案列
import requests
url='https://account.bilibili.com/home/userInfo'
r=requests.get(url)
print(r.json())
重定向与请求历史
重定向
重定向就是通过各种方法将一个网络请求重新定个方向转到其它位置。可能原因是有些网址现在已经废弃不准备再使用等
处理重定向
默认情况下,对于我们常用的GET和POST请求等,Requests会自动处理所有重定向。例如Github把所有的HTTP请求重定向到HTTPS:
r=requests.get('http://github.com')
r.url #'https://github.com'
r.status_code #200
如果你使用的是GET和POST等,那么你可以通过allow_redirects参数禁用重定向处理:
r=requests.get('http://github.com',allow_redirects=Flase)
r.status_code #301
可以使用响应对象的history方法来追踪重定向。response.history是一个Response对象的列表,为了完成请求而创建了这些对象,这个对象列表按照从最老到最近的请求进行排序
r=requests.get('http://github.com')
r.history #[<Response[301]>]
超时
有时候我们由于时间或者对方网站的原因,不想等待很长时间,等待响应的回传,那么我们就可以加上一个时间超时参数,如果超过我们设定的时间,响应还没有返回,那么就不再等待。
你可以告诉requests在讲过以timeout参数设定的秒数时间之后停止等待响应。建议所有的生产代码都应该使用这一参数
requests.get((‘http://github.com’,timeout=0.001)
错误与异常
遇到网络问题(如:DNS查询失败,拒绝连接等)时,Requests会抛出一个ConnectionError异常
1.如果HTTP请求返回了不成功的状态码,Response.raise_for_status()会抛出一个HTTPError异常
2.若请求超时,则抛出一个Timeout异常
3.若请求超过了设定的最大重定的次数,则会抛出一个TooManyRedirects异常
所有Requests显式抛出的异常继承自requests.exceptions.RequestException
字符是各种文字和符号的总称,包括各国家文字,标点符号,图形符号,数字等。字符集是多个字符的集合
字符集包括:ASCII字符集,GB2313字符集,GB18030字符集,Unicode字符集等
ASCII编码是1个字节,而Unicode编码通常是2个字节
User-Agent:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400

XP对应的是Windows NT 5.1
Windows 7对应的是Windows NT 6.1
Windows 8对应的是Windows NT 6.3
GET请求是指从服务器请求获得数据
User-Agent:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400
修改headers
通过Request的headers参数修改
import requests
url='https://www.baidu.com/'
heads={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400'
}
e=requests.get(url,headers=heads)
print(e.status_code)
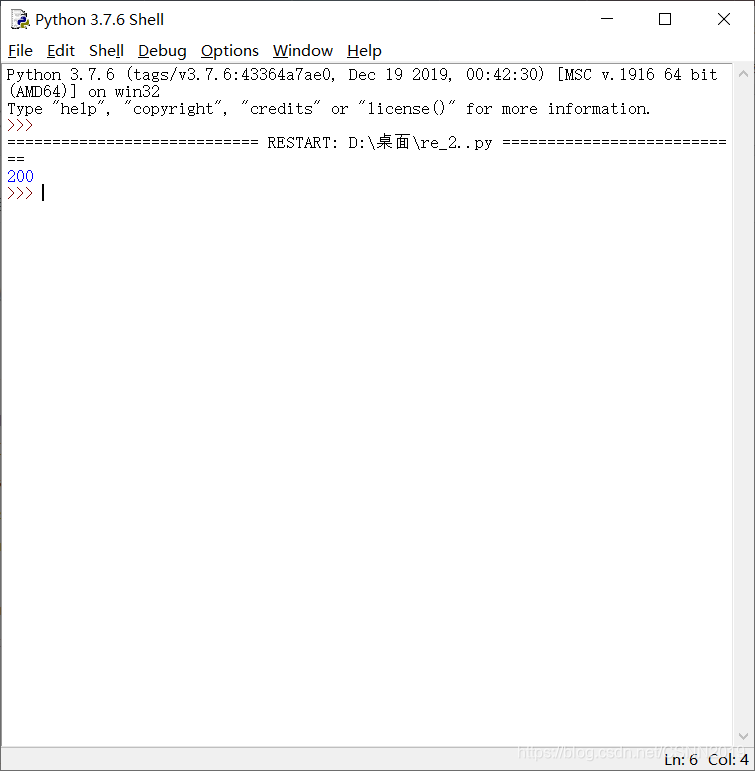
import json
import urllib.request
import urllib.parse
url='https://www.baidu.com/'
heads={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400'
}
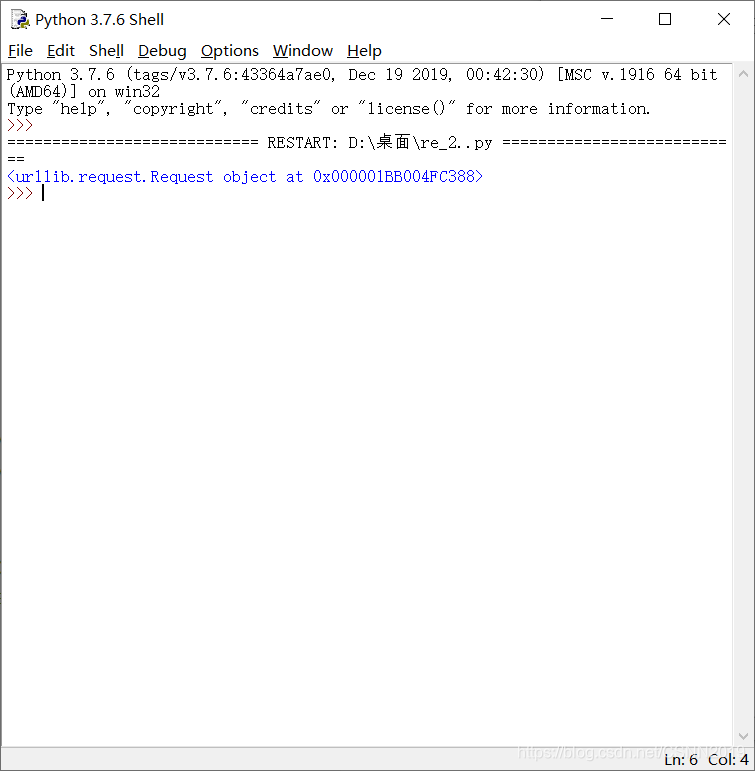
e=urllib.request.Request(url,heads)
print(e)
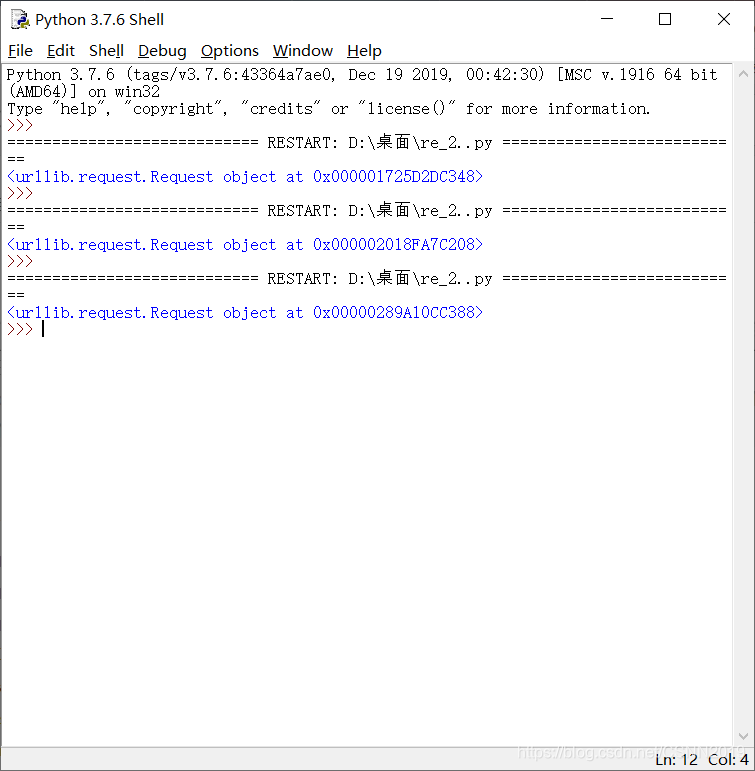
通过request.add_header()方法修改
import json
import urllib.request
import urllib.parse
url='https://www.baidu.com/'
heads={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400'
}
e=urllib.request.Request(url)
e.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3866.400 QQBrowser/10.8.4379.400')
print(e)