介绍
学完爬虫之后,想着做点什么东西,于是,就想着最近房价也不知道咋样了,就做一个房地产的热力图把。由于个人精力和能力的原因,这个热力图比较不准确,需要修改的地方很多,但是我没有足够的时间和精力和兴趣去完成了,在这里就当做爬虫的毕业项目吧。以链家为例。
规划
先观察了链家网页的结构,发现重庆二手房数量有4万3000套左右,但是每次显示数据最多只能是一百页,三千条。所幸链家的页面比较简单,可以通过设置房屋位置、面积、价格等参数,过滤每次显示的数据,且每一个房屋都有自己特有的UID,不用担心数据重复的问题。通过网页拼接,可以实现对所有数据的爬取。
另外:链家没有设置反爬虫机制,谢天谢地。。
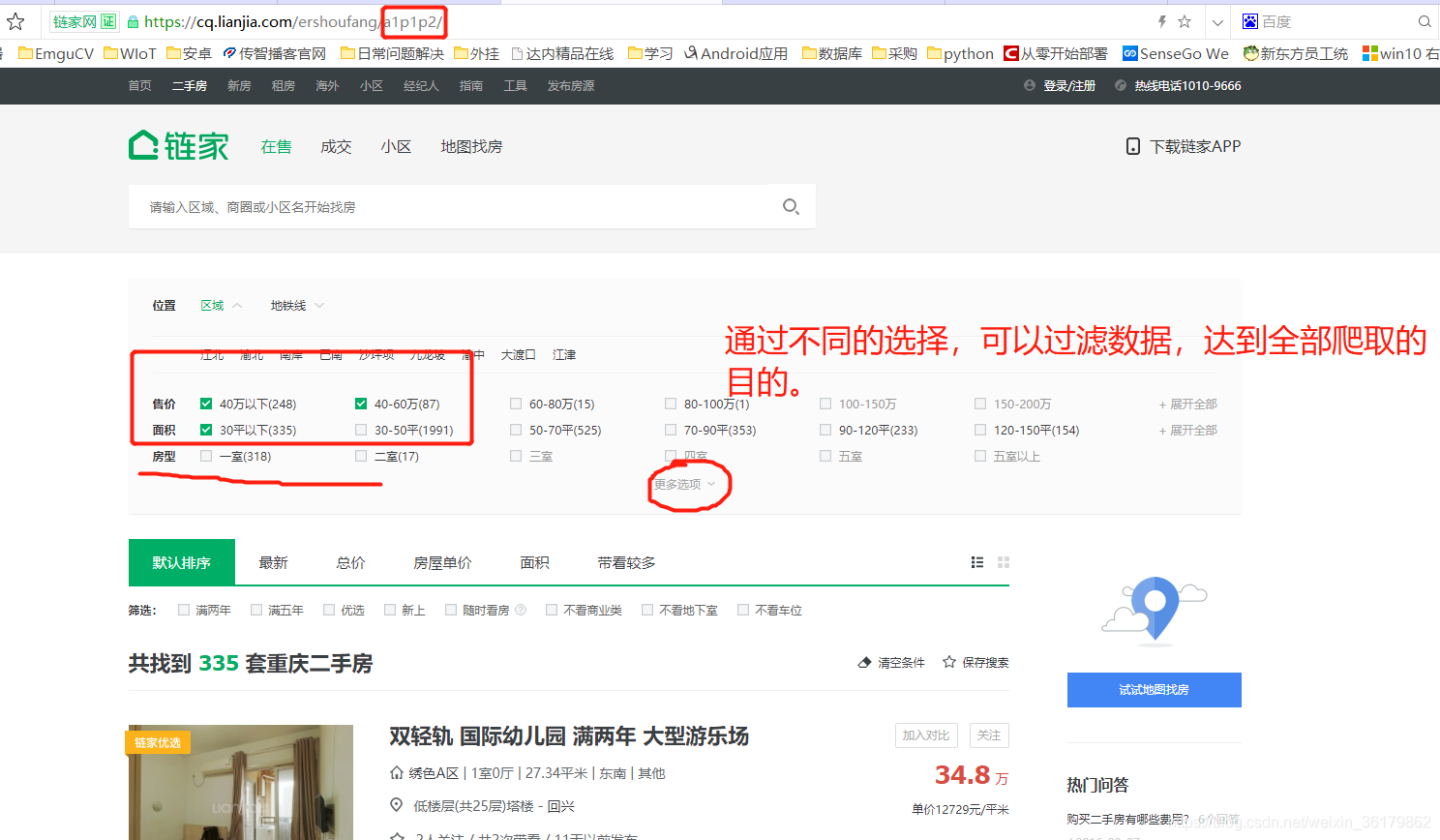
爬取页面:
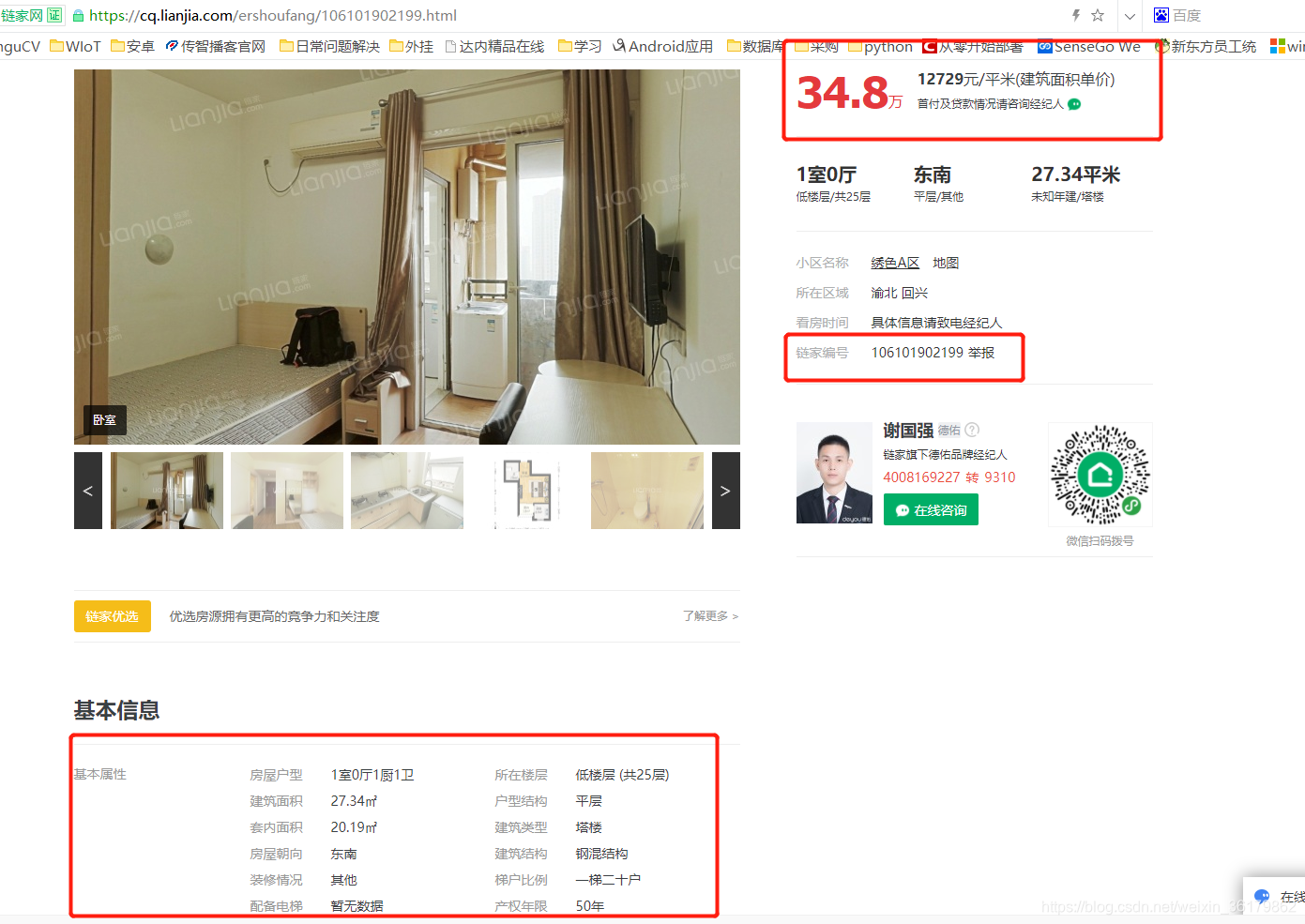
根据爬取的小区名字,再通过百度的坐标拾取,得到小区的物理位置。

最后通过百度热力地图的api生成热力图。
链家爬虫核心代码
生成爬虫
通过xpath捕捉页面元素, 然后拼接爬取url。
# -*- coding: utf-8 -*-
import scrapy
from lianjia.items import LianjiaItem
class ErshoufangSpider(scrapy.Spider):
name = 'ershoufang'
allowed_domains = ['cq.lianjia.com']
start_urls = []
# https://cq.lianjia.com/ershoufang/pg100/
baseurl = "https://cq.lianjia.com/ershoufang/"
L = ["https://cq.lianjia.com/ershoufang/"]
for i in range(1, 100):
L.append(baseurl + "pg" + str(i + 1))
for i in L:
for j in range(1, 10):
url1 = i + "a" + str(j)
for r in range(1, 8):
url2 = url1 + "p" + str(r)
start_urls.append(url2)
def parse(self, response):
w = response.xpath('//div[@class ="info clear"]/div[@class="title"]/a/@href').extract()
for i in w:
yield scrapy.Request(i, callback=self.parseHtml)
def parseHtml(self, response):
item = LianjiaItem()
# shuju=response.xpath()
w1 = response.xpath('//div[@class="content"]/ul/li/span/text()').extract()
w2 = response.xpath('//div[@class="content"]/ul/li/text()').extract()
for i in range(len(w1)):
if w1[i].strip() == "房屋户型":
item["tingshi"] = w2[i]
elif w1[i].strip() == "所在楼层":
item["louceng"] = w2[i]
elif w1[i].strip() == "建筑面积":
item["jianmian"] = w2[i]
elif w1[i].strip() == "套内面积":
item["mianji"] = w2[i]
elif w1[i].strip() == "房屋朝向":
item["chaoxiang"] = w2[i]
elif w1[i].strip() == "装修情况":
item["zhuangxiu"] = w2[i]
item["price"] = response.xpath('//span[@class="total"]/text()').extract()[0]
item["xiaoqu"] = response.xpath(
'//div[@class="content"]/div[@class="aroundInfo"]/div[@class="communityName"]/a/text()').extract()[0]
# 地址
dizhi = ""
for i in response.xpath('//span[@class="info"]/a/text()').extract():
dizhi += i
item["dizhi"] = dizhi
# 年限
item["nianxian"] = response.xpath('//div[@class="area"]/div[@class="subInfo"]/text()').extract()[0]
# 建面单价
item["jianmiandanjia"] = response.xpath('//span[@class="unitPriceValue"]/text()').extract()[0]
# 所在区域
item["weizhi"] = response.xpath('//div[@class="communityName"]/a[1]/text()').extract()[0]
# 房屋编号
item["mid"] = response.xpath('//div[@class="houseRecord"]/span[@class="info"]/text()').extract()[0]
# 链接
item["net"] = "https://cq.lianjia.com/ershoufang/" + item["mid"] + ".html"
L = [
"xiaoqu",
"louceng",
"tingshi",
"mianji",
"jianmian",
"chaoxiang",
"zhuangxiu",
"nianxian",
"price",
"jianmiandanjia",
"weizhi",
"mid",
"net",
"dizhi"]
for i in L:
if not item[i]:
item[i] = "NULL"
yield item
设置数据结构:
保存的数据结构如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 小区
xiaoqu = scrapy.Field()
# 楼层
louceng = scrapy.Field()
# 几室几厅
tingshi = scrapy.Field()
# 面积
mianji = scrapy.Field()
# 建筑面积
jianmian = scrapy.Field()
# 朝向
chaoxiang = scrapy.Field()
# 装修
zhuangxiu = scrapy.Field()
# 年限
nianxian = scrapy.Field()
# 总价
price = scrapy.Field()
# 建面单价
jianmiandanjia = scrapy.Field()
# 所在区域
weizhi = scrapy.Field()
# 房屋编号
mid = scrapy.Field()
# 链接
net = scrapy.Field()
#小区大致位置
dizhi=scrapy.Field()
设置管道中间件
# -*- coding: utf-8 -*-
from lianjia.settings import mysql
import csv
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class LianjiaPipeline(object):
def process_item(self, item, spider):
return item
# 存入数据库
class LianjiaPipeline_MYSQL(object):
def process_item(self, item, spider):
data = [("xiaoqu", item["xiaoqu"]), ("louceng", item["louceng"]), ("tingshi", item["tingshi"]),
("mianji", item["mianji"]),
("jianmian", item["jianmian"]), ("chaoxiang", item["chaoxiang"]), ("zhuangxiu", item["zhuangxiu"]),
("nianxian", item["nianxian"]),
("price", item["price"]),
("jianmiandanjia", item["jianmiandanjia"]), ("weizhi", item["weizhi"]), ("mid", item["mid"]),
("net", item["net"]), ("dizhi", item["dizhi"])]
mysql.addDate(data)
print("over")
# csv格式保存
class LianjiaPipeline_CSV(object):
def process_item(self, item, spider):
with open("shuju.csv", "a", encoding="utf-8") as f:
write = csv.writer(f)
data = [item["xiaoqu"], item["louceng"], item["tingshi"], item["mianji"], item["jianmian"],
item["chaoxiang"], item["zhuangxiu"], item["nianxian"], item["price"],
item["jianmiandanjia"], item["weizhi"], item["mid"],
item["net"], item["dizhi"]]
write.writerow(data)
爬虫框架设置
# -*- coding: utf-8 -*-
from Cspider import Cmysql
# Scrapy settings for lianjia project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lianjia'
LOG_LEVEL = "WARNING"
SPIDER_MODULES = ['lianjia.spiders']
NEWSPIDER_MODULE = 'lianjia.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'lianjia (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent": 'Mozilla/5.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'lianjia.middlewares.LianjiaSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.LianjiaDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 设置管道中间件
ITEM_PIPELINES = {
# 'lianjia.pipelines.LianjiaPipeline': 300,
'lianjia.pipelines.LianjiaPipeline_MYSQL': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#创建数据库,这个类是我自己总结数据库操作方式写的,读者可以自己写数据库操作方式
mysql = Cmysql("lianjia", (
("name", "ershoufang2"), ("xiaoqu", "varstr"), ("louceng", "varstr"), ("tingshi", "varstr"), ("mianji", "varstr"),
("jianmian", "varstr"), ("chaoxiang", "varstr"), ("zhuangxiu", "varstr"), ("nianxian", "varstr"),
("price", "varstr"),
("jianmiandanjia", "varstr"), ("weizhi", "varstr"), ("mid", "varstr"),("net", "varstr"),("dizhi", "varstr")))
坐标拾取爬虫
from selenium import webdriver
import time
from Cspider import Cetree,Cmongodb
# opt=webdriver.ChromeOptions()
# opt.set_headless()
driver=webdriver.Chrome()
driver.get("http://api.map.baidu.com/lbsapi/getpoint/index.html")
with open("zuobiao.txt","r",encoding="utf-8") as f:
# 自己写的一个mongodb操作类,
d=Cmongodb("zuobiao","ershoufang")
i=1
while True:
x=f.readline()
if x:
driver.find_element_by_id("localvalue").clear()
driver.find_element_by_id("localvalue").send_keys("重庆 "+x)
driver.find_element_by_id("localsearch").click()
time.sleep(1)
et=Cetree(driver.page_source)
dizhi=et.work('//ul/li[@id="no0"]/div[@id="no_0"]/p/text()')
print(str(i),dizhi)
w1={"小区":x}
for j in dizhi:
r=j.split(":")
w1[r[0]]=r[1]
i+=1
d.addDate(w1)
else:
driver.quit()
break
统计各小区的二手房数量
L=[]
D={}
with open("小区.txt","r",encoding="utf-8") as f:
with open("zuobiao.txt","r",encoding="utf-8") as d:
while True:
x=d.readline()
if x:
D[str(x)]=0
else:
break
while True:
x=f.readline()
if x:
for i in D:
if i==str(x):
D[i]+=1
break
else:
break
with open("ww.txt","w") as f:
for i in D:
f.write(i+":"+str(D[i])+"\n")
生成需要的坐标结构:
m1={}
m2={}
with open("user2.txt","r",encoding="utf-8") as r:
while True:
x=r.readline()
if x:
try:
m1[x.split(":")[0]]=x.split(":")[1]
except :
print("x:",x)
else:
break
with open("relituzuobiao.txt","a") as re:
with open("ww.txt","r",encoding="GBK") as f:
while True:
x=f.readline()
if x:
try:
m2[x.split(":")[0]]=x.split(":")[1]
except:
print("y:",x)
else:
break
for i in m1:
try:
re.write('{"lng":%s,"lat":%s,"count":%s},'%(m1[i][:-1].split(",")[0],m1[i][:-1].split(",")[1],m2[i][:-1]))
except Exception as e:
print(e)
最后使用百度地图api生成
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak=你的ak"></script>
<script type="text/javascript" src="http://api.map.baidu.com/library/Heatmap/2.0/src/Heatmap_min.js"></script>
<title>热力图功能示例</title>
<style type="text/css">
ul,li{list-style: none;margin:0;padding:0;float:left;}
html{height:100%}
body{height:100%;margin:0px;padding:0px;font-family:"微软雅黑";}
#container{height:500px;width:100%;}
#r-result{width:100%;}
</style>
</head>
<body>
<div id="container"></div>
<div id="r-result">
<input type="button" onclick="openHeatmap();" value="显示热力图"/><input type="button" onclick="closeHeatmap();" value="关闭热力图"/>
</div>
</body>
</html>
<script type="text/javascript">
var map = new BMap.Map("container"); // 创建地图实例
var point = new BMap.Point(116.418261, 39.921984);
map.centerAndZoom(point, 15); // 初始化地图,设置中心点坐标和地图级别
map.enableScrollWheelZoom(); // 允许滚轮缩放
// 写入数据
var points =[
{"lng":106.608082,"lat":29.72371,"count":16},
{"lng":106.590536,"lat":29.544851,"count":11},
{"lng":106.566819,"lat":29.491325,"count":19},
{"lng":106.536746,"lat":29.58987,"count":10},
.....
];
if(!isSupportCanvas()){
alert('热力图目前只支持有canvas支持的浏览器,您所使用的浏览器不能使用热力图功能~')
}
//详细的参数,可以查看heatmap.js的文档 https://github.com/pa7/heatmap.js/blob/master/README.md
//参数说明如下:
/* visible 热力图是否显示,默认为true
* opacity 热力的透明度,1-100
* radius 势力图的每个点的半径大小
* gradient {JSON} 热力图的渐变区间 . gradient如下所示
* {
.2:'rgb(0, 255, 255)',
.5:'rgb(0, 110, 255)',
.8:'rgb(100, 0, 255)'
}
其中 key 表示插值的位置, 0~1.
value 为颜色值.
*/
heatmapOverlay = new BMapLib.HeatmapOverlay({"radius":20});
map.addOverlay(heatmapOverlay);
heatmapOverlay.setDataSet({data:points,max:100});
//是否显示热力图
function openHeatmap(){
heatmapOverlay.show();
}
function closeHeatmap(){
heatmapOverlay.hide();
}
closeHeatmap();
function setGradient(){
/*格式如下所示:
{
0:'rgb(102, 255, 0)',
.5:'rgb(255, 170, 0)',
1:'rgb(255, 0, 0)'
}*/
var gradient = {};
var colors = document.querySelectorAll("input[type='color']");
colors = [].slice.call(colors,0);
colors.forEach(function(ele){
gradient[ele.getAttribute("data-key")] = ele.value;
});
heatmapOverlay.setOptions({"gradient":gradient});
}
//判断浏览区是否支持canvas
function isSupportCanvas(){
var elem = document.createElement('canvas');
return !!(elem.getContext && elem.getContext('2d'));
}
</script>
总结
这样生成的效果其实不好的,特别是房价的热力分布。最主要的原因在于没有办法按照面积生成热力图,只能按照点生成。
就这么多吧。