Ⅰ安装VirtualBox虚拟机以及Ubuntu(linux)系统
1.先下载安装包
2.先安装VirtualBox虚拟机

安装完成

3.在虚拟机上安装Ubuntu系统




安装完成

Ⅱ在linux上安装JDK
1.下载并安装JDK

2.修改配置变量
(1)通过vim进入profile
![]()
(2)修改环境变量

3.检查是否安好

Ⅲ下载、安装、配置Hadoop环境、并启动Hadoop
1.下载Hadoop
![]()

2.安装Hadoop
(1)先把安装包放到/opt/文件下
![]()
(2)然后进行解压![]()
(3)解压后的文件
![]()


(4)进入配置文件夹
![]()


红框内的文件是要修改的配置文件
(5)修改配置
i)对hadoop-env.sh进行修改
![]()

ii)对core-site.xml进行修改
![]()

iii)对hdfs-site.xml进行修改
![]()

iv)对mapred-site.xml进行修改
![]()

v)对profile进行修改
![]()

(6)查看Hadoop是否配好
![]()

(7)对namenode进行format处理


(8)通过start-all.sh启动hadoop

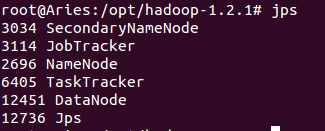
(9)通过jps命令查看hadoop是否启动成功
Ⅳ运行wordcount示例
要求:WordCount单词计算
计算文件中出现每个单词的频数
输入结果按照字母顺序进行排序
例如:
输入:
hello world bye world
hello hadoop bye hadoop
bye hadoop hello hadoop
输出:
bye 3
hello 3
hadoop 4
world 2
map、reduce的理论过程:


准备:wordcount.java文件
![]()
查看代码内容:

正式开始
(1)首先查看hadoop是否运行

(2) vim WordCount.java编译程序,这里我们使用上面准备好的代码
![]()

(3) 对WordCount.java进行编译,因为导入一些hadoop的架包,所以要通过classpath对命令行进行加入
javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/l ib/commons-cli-1.2.jar -d word_count_class/ WordCount.java
![]()
(4)进入word_count_class文件夹并观察内容
![]()
![]()
(5)把当前目录下所有class文件打包成wordcount.jar:jar -cvf wordcount.jar *.class

(6)再次查看当前文件,可以观测到多了一个wordcount.jar文件
![]()
(7)返回到word_count文件夹下,进入到input文件夹,写入file1和file2

编辑file1

编辑file2

(8)返回word_count文件夹
![]()
把file1和file2都放在input_wordcount 文件夹下:hadoop fs -put input/* input_wordcount/

建立之前如果没有input_wordcount文件夹需要先创建一个:hadoop fs -mkdir input_wordcount
![]()
创建后再提交:hadoop fs -put input/* input_wordcount/
![]()
(9)用hadoop fs -ls命令查看放到哪了,观察到文件放在/user/root/input_wordcount

(10)查看是否是file1文件
hadoop fs -cat input_wordcount/file1
(11)运行hadoop的命令:hadoop jar word_count_class/wordcount.jar WordCount input_wordcount output_wordcount

知识点:先map再reduce,简单来说,只有map达到100%之后才能进行reduce
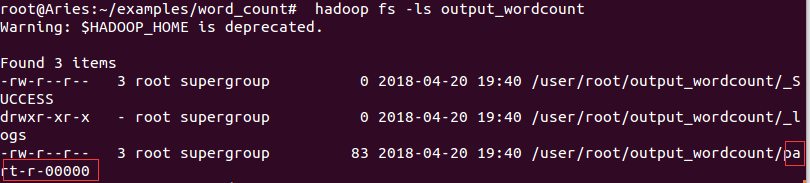
(12)查看结果:hadoop fs -ls output_wordcount,运行结果在红框路径内
(13)查到运行结果:hadoop fs -cat output_wordcount/part-r-00000,其结果是按照字典的顺序进行排序的

参考文献:
学习视频链接:https://www.imooc.com/learn/391
PS:其实这是分布式计算的作业,感谢孙老师的教导