首先确保ssh已安装,如果没有安装执行yum install ssh
然后执行ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa生成秘钥
这里用的hadoop2.8.5,下载.tar.gz文件上传到虚拟机上,如何将主机文件上传到VritualBox已经有了充分的说明,自行查看,上传到指定目录之后执行tar -xvf xxxx.tar.gz进行解压。
解压完hadoop要配置环境变量,vi /etc/profile
添加
HADOOP_HOME=/root/hadoop
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin
export HADOOP_HOME
export PATH
这里PATH里面有$JAVA_HOME/bin如果上面配置java的环境变量的时候写了可以把之前写的PATH注释掉。
然后执行 source /etc/profile使环境变量生效。
接下来配置hadoop的一些文件:
第一个解压后的hadoop目录下的/etc/hadoop/core-site.xml
看一下是否有这个<configuration></configuration>,如果没有自己写上去,然后在这个<configuration></configuration>中加入
<property>
<name>fs.defaultFS</name>
<value>hdfs://s204:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>第二个文件是解压后的hadoop目录下/etc/hadoop/hdfs-site.xml
同样在<configuration></configuration>中加入
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s204:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>第三个文件是解压后的hadoop目录下的/etc/hadoop/mapred-site.xml
接下来的几个xml里都要写在<configuration></configuration>中
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>s204:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>s204:19888</value>
</property>第四个文件是在解压后的hadoop目录下的/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>s204:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>s204:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>s204:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>s204:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>s204:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6078</value>
</property>接下来修改文件也是在解压后的hadoop目录下的/etc/hadoop/yarn-env.sh
找到被注释掉的生命 export JAVA_HOME=/usr/local/java/jdk1.8.0_191(确保这个地址是jdk的安装路径)去掉注释
然后找到JAVA_HEAP_MAX=-Xmx1000m改成JAVA_HEAP_MAX=-Xmx1024m(这个的作用暂时未查明,不过使用没问题)。
最后一个文件是在解压后的hadoop目录下的/etc/hadoop/slaves
这个文件里面只写s204就可以。
接下来配置网络,vi /etc/sysconfig/network-scripts/ifcfg-enp0s3(这个名字可能是不同的),你可以通过命令ip add查看

这样就确定是哪个了,然后编辑修改这个文件对照内容如下:
TYPE="Ethernet"
#BOOTPROTO="dhcp"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="b9fe1e5c-be20-47f1-a2d3-e12f5ddb6aa1"
DEVICE="ens33"
ONBOOT="yes"
IPADDR0=192.168.9.10
PREFIX0=24
GATEWAY0=192.168.9.5
DNS1=114.114.114.114重启网络systemctl restart network或者/etc/rc.d/init.d/network restart
现在可以启动hadoop了,首先进入解压后的hadoop目录下执行./bin/hdfs namenode -format
在输出中看到Exiting with status 0表示成功
然后执行./sbin/start-all.sh
看输出没有error等报错信息就是成功了,或者通过执行命令./bin/hdfs dfsadmin -report查看。
打通主机与虚拟机网络去访问http://s204:8088
首先在virtualBox中选中虚拟机然后右键--》设置出现如下图
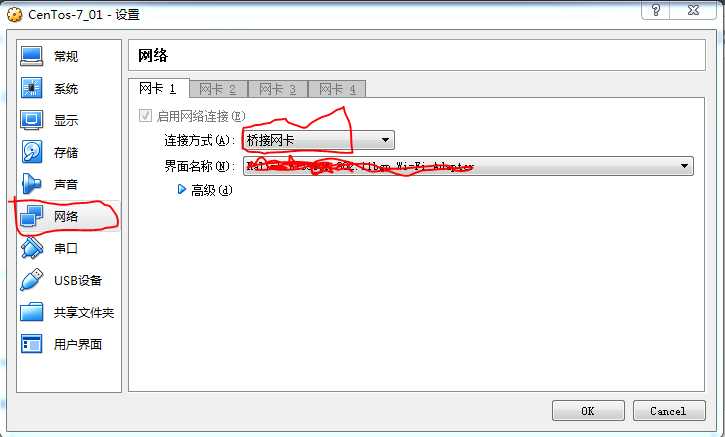
选择“桥接网卡”界面名称中选中你的网络,我这里是使用无线网络,然后点“OK”,之后要进入虚拟机centos下设置网络获取方式为自动获取
nmcli connection modify enp0s3 \connection.autoconnect yes \ipv4.method auto --设置自动获取ip
nmcli connection up enp0s3 ----启用设置
这里enp0s3每个虚拟机可能不一样,可以使用ip add

或者nmcli connection show

最后systemctl stop firewalld.service --关闭防火墙
或者systemctl disable firewalld.service --禁止开机启动防火墙
===========================================================================================
下面是一些在启动hadoop时出现的问题及解决办法。
在执行./sbin/start-all.sh的时候出现异常could not resolve hostname s204:name or service not known
使用./bin/hdfs dfsadmin -report查看是否有节点的时候报错java.net.UnknownHostException:s204(这个在上面出现过,也可以换成别的)
这时候要查看/etc下面的hosts文件,添加上对应的ip与主机名即:192.168.10.11 s204
重新执行./sbin/start-all.sh。
在执行./sbin/start-all.sh的时候出现异常error:JAVA_HOME is not set and could not be found
这时候需要修改Hadoop目录下/etc/hadoop下的hadoop-env.sh,将这个文件中的声明export JAVA_HOME=/usr/local/java/jdk1.8.0_191显示的声明一下。