Euclidean Distance
Manhattan Distance
Hamming Distance
Normalization
1.Euclidean Distance 欧几里得距离
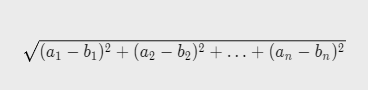
def euclidean_distance(pt1,pt2):
distance=0
for i in range(len(pt1)):
distance+=(pt1[i]-pt2[i])**2
distance=distance**0.5
return distance2.Manhattan Distance 曼哈顿距离
类似于行走城市街区时的导航方式 曼哈顿距离始终大于或等于欧几里德距离
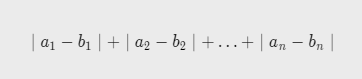
def manhattan_distance(pt1,pt2):
distance=0
for i in range(len(pt1)):
distance+=abs(pt1[i]-pt2[i])
return distance3.Hamming Distance 汉明距离
汉明距离是距离公式的另一个略微不同的变化。汉明距离不仅仅关注每个维度的差异,而只关心维度是否完全相等。找到两点之间的汉明距离时,为每个具有不同值的维度添加一个。
汉明距离用于拼写检查算法。例如,单词“there”和拼写“thete”之间的汉明距离是1。每个字母都是一个维度,每个维度除了一个之外具有相同的值。
def hamming_distance(pt1,pt2):
distance=0
for i in range(len(pt1)):
if pt1[i]!=pt2[i]:
distance+=1
return distancescipy 使用三种距离公式
from scipy.spatial import distance
print(distance.euclidean([1,2],[4,0]))
print(distance.cityblock([1,2],[4,0]))
print(distance.hamming([5, 4, 9], [1, 7, 9]))Normalization 规范化
规范化数据是机器学习的重要组成部分。您可能拥有一个具有许多强大功能的惊人数据集,但如果您忘记进行规范化,其中一个功能可能完全支配其他功能。这就像你丢掉了几乎所有的信息!规范化解决了这个问题。在本文中,您学习了以下标准化技术:
最小 - 最大规范化
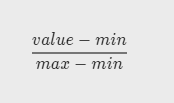
缺点:不能很好地处理异常值

Z-Score标准化
这里,μ是特征的平均值,σ是特征的标准偏差。
如果一个值恰好等于特征的所有值的平均值,它将被标准化为0.如果它低于平均值,它将是负数,如果它高于平均值,它将是正数数。

结果
注意两个要素的点现在大致相同 -
几乎所有点在x轴和y轴上都在-2和2之间。
唯一可能的缺点是功能不完全相同。
通过min-max归一化,我们保证将我们的两个特征重塑为0到1.使用z-score归一化,x轴现在的范围从大约-1.5到1.5,而y轴有一个范围从大约-2到2.这肯定比以前更好; 先前具有0到40范围的x轴不再支配y轴。
