版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/kiss_xiaojie/article/details/78228507
ZhiHuCrawler(基于 webmagic 的知乎爬取)
简介
GitHub 地址
出于兴趣想要分析一下知乎,所以爬取了一些知乎的数据。爬取的数据主要有三种:
- 某种话题(如互联网、软件工程)下的问题
- 知乎大V(如张佳玮、李开复等)
- 大V回答
模块
主要分两个模块:
话题问题爬取(ZhiHuTopicspackage)
该模块主要爬取某话题下的
Question,比如爬取软件工程下的问题。爬取的结果如下:
url: https://www.zhihu.com/question/66519221
标题: 腾讯开发微信花了多少钱?真的技术难度这么大吗?难点在哪里?
关注者: 2955
浏览人数: 1288594
【注】:这里由于我不需要
问题回答,故没有爬取用户回答。其实,在此基础上修改一下很容易得到用户回答内容。该模块下爬取内容的输出为
txt文件。该模块的使用案例,请参考
Crawler类中main()方法。
大v爬取(VAnalysispackage)【未添加注释。。。】
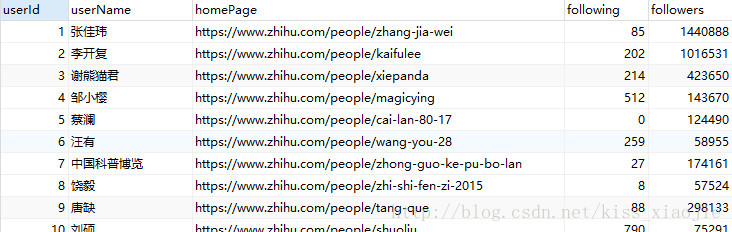
该模块爬取的数据可分为两类:
知乎大
v【案例】:VUserCrawler类中main()
大
V回答 【案例】:VAnswerCrawler类中main()
该模块爬取的结果输出到
MySQL数据库。其中,使用了Hibernate方便、优化了输出。

相关
如果需要修改,请先了解
WebMagic。WebMagic 是一个开源的Java垂直爬虫框架。为防止知乎锁
IP,爬取速度不是很快。我在爬top100大v的回答(8w+数据) 时大约使用了 2天 17小时。
关于
IntelliJ IDEA 2017.1
Build #IU-171.3780.107, built on March 22, 2017
Licensed to kissx
JRE: 1.8.0_112-release-736-b13 amd64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Windows 10 10.0