这篇博客的内容是我这两天利用pandas读取excel和读写MySql时用到的一些函数功能。写下来,免得以后再去百度上东找西找。
先说连接上mysql的问题吧,因为我是从琢磨这个问题开始的。首先,我用的是MySql8.0, Django2.0.6和Python3.6.4。本来打算用Django内置的Myqsl驱动来读写数据库。所以找到了Django-pandas。但是找来找去发现这货只能把QuerySet转换成DataFrame,没办法转换回去。不符合我的需求,所以弃用。
竟然Django的内置MySql驱动用不了,只能自己找了。我看网上很多人用PyMySQL和mysqlclient,但是我发现另外一个驱动,是MySQL官方写的针对Python的驱动=>MySQL Connectors(连接过去是MySQL)的官方网址。嗯..看起来很叼的样子。想用这个,然后有继续找文档。发现网上有大神测试过这3个驱动的速度。分别如下
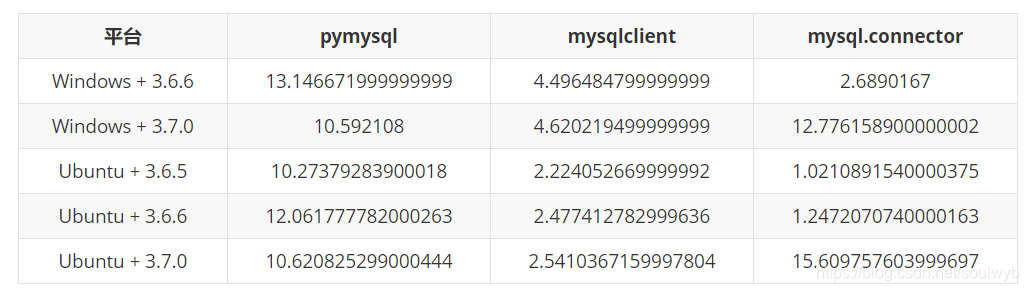
数据与分析来源:https://www.v2ex.com/t/497288
所以我就选择了MySQL Connectors(反正领导让我做一个自用项目 也没啥特别要求。我想咋玩都可以),具体如何安装看官方网址的文档就可以了。我这里就不记了,觉得麻烦就pip install mysql-connector-python好了。
驱动选择好了。那接下来如何连接呢。看pandas的文档是说建议使用ORM框架--SQLAlchemy作为MySql的engine。好吧,人家pandas都建议了那我们就用吧。SQLAlchemy的具体用法看官方文档就好了,反正有示例,一看就懂怎么玩(其实主要原因有两个,1是这篇博客主要是记录pandas的操作;2是我懒= =。改天我专门写一篇来详细介绍这货吧)==》SQLAlchemy1.3文档网址
解决了控制mysql的问题,那接下来说的就是pandas中我有用到的一些方法,分别列出来。以后有碰到其他的再追加写上(编写顺序不分先后,各自独立,只是写了如何用,具体详细参数我回头在各自写文章讲解。不然这篇博客写不完,下午还得干活呢):
操作前必备导入模块
import pandas as pd
from sqlalchemy import create_engine
import mysql.connector as mysql_
读取数据库数据:
engine = create_engine('mysql+mysqlconnector://root:password@database_IP:3306/db_name')
df = pd.read_sql('select * from table_name', engine)读取Excel(不管xls或者xlsx都无所谓):
返回DataFrame类型数据,header=1 的意思是标题选择第二行,这种针对表格内标题那边有1行以上的情况
excel = pd.read_excel("excel_path", header = 1)删除行(列也是用这个行数,只是参数是columns=['列名']
new_excel = csult.drop([row_index])写入数据库:
df是指DataFrame,if_exists=“append”表示表存在的话就追加写入,index是选择是否将index列一起写入数据库
df.to_sql(name='table_name', con=engine, if_exists='append', index=False)
获取DataFrame的行数和列数:
#获取行列数元祖
df.shape
#获取行数
df.shape[0]
#获取列数
df.shape[1]判断指定列(或全部列)是否(全部)含有NaN(空值):
#判断某列是否含有空值
df['col_name'].isnull().any()
#判断某列是否全部都是空值
df['col_name'].isnull().all()
#判断某几列是否全部都是空值
df[['col_name','col_name']].isnull().all()
#判断某几列是否全部都是空值
df[['col_name','col_name']].isnull().any()
#该函数返回一个空值判断的二维数组(但是空值不是'',而是NaN)
df[['col_name','col_name']].isnull()DataFrame插入列:
#这里要注意,插入之后原df是不变,pandas会返回一个新的df
#在第1列后面插入标题为‘X’,的数据‘abc’(该列每行的数据都是‘abc’)
#如果每列要不同的数据的话可以先新建Series对象然后‘abc’替换成Series对象
df.insert(1, 'X', 'abc')选择多列:
#返回一个新的df
df[['col_name','col_name']]替换指定列中的空值:
#指定某列的空值
df['col_name'].fillna('value')
#df中全部空值都替换掉
df.fillna('value')数据替换:
#s是指Series对象,意思就是需要指定某一列或某一行
s.replace('old_value','new_value')
#替换多种数值
s.replace(['old_value','old_value'],['new_value','new_value'])指定列的数据过滤:
#使用python的条件判断格式即可
df[df['col_name'] > 0.5]判断DataFrame是否为空:
#为空返回True,否则返回False
df.empty目前用到的就这些了,后面有用到其他的我在写上。