目录
1、准备工作
(1):准备好Python或者Anaconda的pandas库,安装:pip install pandas
(2):pandas依赖处理Excel的xlrd模块,安装命令:pip install xlrd
(3):打开代码编辑器jupyter、ipython、pycharm,根据自己习惯和需求选用。
2、准备好excel数据表格
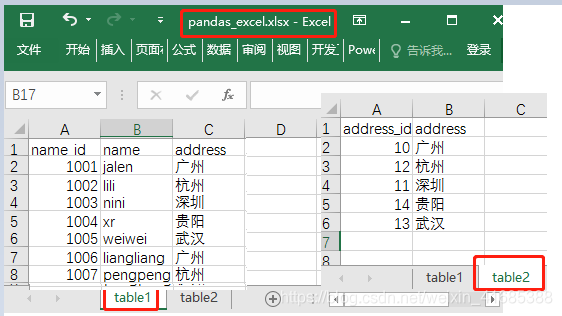
3、使用Pandas读取excel数据
df = pd.read_excel('路径',sheet_name='excel中的哪个表,表名/位置')
如果不使用sheet_name='***',默认读取第一张表
import pandas as pd
import xlrd
#读取sheet_name='table1'的数据
df=pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table1') #根据表的名称
#df = pd.read_excel("e:\pandas_excel.xlsx",sheet_name=0) #根据表的位置
print(df.head())#默认读取前5行的数据
print(df)#输出全部数据
>>结果
name_id name address
0 1001 jalen 广州
1 1002 lili 杭州
2 1003 nini 深圳
3 1004 xr 贵阳
4 1005 weiwei 武汉
name_id name address
0 1001 jalen 广州
1 1002 lili 杭州
2 1003 nini 深圳
3 1004 xr 贵阳
4 1005 weiwei 武汉
5 1006 liangliang 广州
6 1007 pengpeng 杭州
#读取sheet_name='table2'的数据
df1 = pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table2')#根据表的名称
#df1 = pd.read_excel("e:\pandas_excel.xlsx",sheet_name=1) #根据表的位置
print(df1.head(2))#读取前2行的数据
print(df1)#输出全部数据
>>结果
address_id address
0 10 广州
1 12 杭州
address_id address
0 10 广州
1 12 杭州
2 11 深圳
3 14 贵阳
4 13 武汉4、Pandas读取指定(限定)行的excel数据
import pandas as pd
import xlrd
df = pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table1')#根据表的名称
print(df.head(10))#只能限定行方向的高度,取前10行
print(df.ix[[0,2,3]].values) #返回指定的行的ndarray结果
print(df.ix[[0,2,3]]) #返回指定的行的DataFrame结果
print(df.index[0:5:2]) #返回指定的index结果
print(df.ix[df.index[0:5:2]].values) #根据index返回指定的行的ndarray结果
print(df.ix[df.index[0:5:2]]) #根据index返回指定的行的DataFrame结果5、Pandas读取指定(限定)列的excel数据
df = pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table1')#根据表的名称
print(df['name'].values) #只能获取单列值
print(df.ix[:,["name","address"]]) #返回指定的列的DataFrame结果
print(list(df.columns[0:3:1])) #返回columns结果
print(df.ix[:,list(df.columns[1:3:1])].values) #根据index返回指定的列的ndarray结果
print(df.ix[:,list(df.columns[1:3:1])]) #根据index返回指定的列的DataFrame结果6、Pandas读取同时指定行和列的excel数据
df = pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table1')#根据表的名称
d = df.ix[list(df.index[3:5:1]),list(df.columns[1:3:1])] #3,4行,1,2列,起始行列都为0
print(d)7、pandas处理Excel数据成为字典
df = pd.read_excel('e:\pandas_excel.xlsx',sheet_name='table1')#根据表的名称
d = []
for i in df.index[::]:
d_row = df.ix[i,list(df.columns[0:3:1])].to_dict()
d.append(d_row)
print(d)8、pandas数据写入Excel文件
当需要写入多个Sheet时,则需要在写入前创建好一个Excel文件,否则可以直接写入。
语法:
df.to_excel(excel_writer, sheet_name=’Sheet1’, na_rep=”, float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep=’inf’, verbose=True, freeze_panes=None)
部分参数解释:
excel_writer:文件名、文件具体、相对路径、文件对象等
sheet_name:写入时设定Sheetname,默认为’Sheet1’
sep:文件分割符号
na_rep:将NaN转换为特定值
columns:选择部分列写入
header:忽略列名
index:False则选择不写入索引写入单个Sheet表格
只能写入一个Sheet表格,多次写入则会清除excel文件中的内容
df.to_excel('e:\df.xlsx')
自定义Sheetname
df.to_excel('e:\df.xlsx',sheet_name='table1')
同一个Excel文件写入多个Sheet表格
写入多个Sheet时,则需要在写入前创建好一个Excel文件
写入多个表时,需要用到pd.ExcelWriter()打开一个Excel文件
work=pd.ExcelWriter(''e:\df.xlsx'')
df.to_excel(work,sheet_name='table1')
df1.to_excel(work,sheet_name='table2')
