目录
二、第一种是通过tf.device()函数来指定训练时所要使用的GPU
一、Linux查看Nvidia显卡信息及使用情况
Nvidia自带一个命令行工具可以查看显存的使用情况:nvidia-smi
zhangkf@Ubuntu2:~$ lspci | grep -i nvidia
03:00.0 VGA compatible controller: NVIDIA Corporation Device 1b00 (rev a1)
03:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
zhangkf@Ubuntu2:~$ nvidia-smi
Tue Dec 11 20:45:00 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.72 Driver Version: 410.72 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 TITAN X (Pascal) Off | 00000000:03:00.0 Off | N/A |
| 19% 31C P0 50W / 250W | 0MiB / 12196MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
表头释义:
Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:能耗表示;
us-Id:涉及GPU总线的相关信息;
Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的GPU利用率;
Compute M:计算模式; 下边的Processes显示每块GPU上每个进程所使用的显存情况。
命令行参数-n后边跟的是执行命令的周期,以s为单位。
ok,多说一句,显卡也分为两部分,即显卡跟计算单元,类似与内存跟CPU。
================================================================================================
在用tensorflow训练深度学习模型的时候,假设我们在训练之前没有指定GPU来进行训练,则默认的是选用第0块GPU来训练我们的模型,而且其它几块GPU的也会显示被占用。有些时候,我们更希望可以通过自己指定一块或者几块GPU来训练我们的模型,而不是用这种默认的方法。接下来将简单介绍两种简单的方法。
二、第一种是通过tf.device()函数来指定训练时所要使用的GPU
假设我们要用我们的第2块GPU来训练模型,此时可以通过下面的代码来指定:
tf.device('/gpu:2')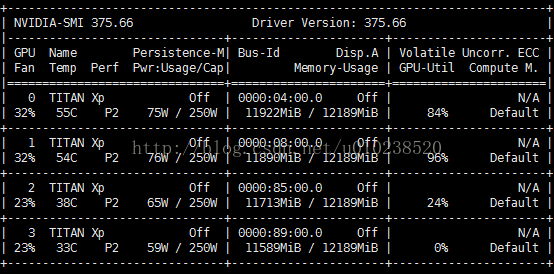
三、通过CUDA_VISIBLE_DEVICES来指定
import os
os.environ['CUDA_VISIBLE_DEVICES']='2'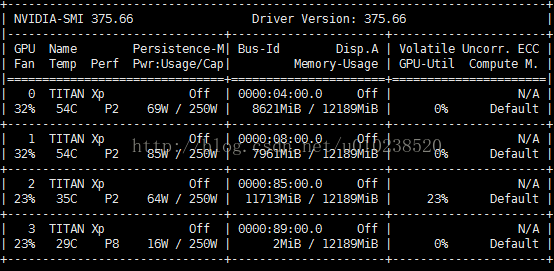
我们可以看到,在训练模型的时候,使用了第2块GPU,并且其它几块GPU也没有被占,这种就相当于在我们运行程序的时候,将除第2块以外的GPU全部屏蔽了,只有第2块GPU对当前运行的程序是可见的。同样,如果要指定2,3块GPU来训练,则上面的代码可以改成:
os.environ['CUDA_VISIBLE_DEVICES']='2,3'类似的如果还有更多的GPU要指定,都可以仿照上面的代码进行添加。
这种方法还可以在运行python程序的前面指定,比如:
CUDA_VISIBLE_DEVICES=2 python train.py实现的功能就和上面的代码一样。
四、tensorflow的显卡使用方式
1、直接使用
with tf.Session() as sess:这种方式会把当前机器上所有的显卡的剩余显存基本都占用,注意是机器上所有显卡的剩余显存。因此程序可能只需要一块显卡,但是程序就是这么霸道,我不用其他的显卡,或者我用不了那么多显卡,但是我就是要占用。
2、分配比例使用
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction=0.6
with tf.Session(config=config) as sess:其中这种方式跟上面直接使用方式的差异就是,我不占用所有的显存了,例如这样写,我就占有每块显卡的60%。
3. 动态申请使用
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:这种方式是动态申请显存的,只会申请内存,不会释放内存。而且如果别人的程序把剩余显卡全部占了,就会报错。
以上三种方式,应根据场景来选择。
第一种因为是全部占用内存,因此只要模型的大小不超过显存的大小,就不会产生显存碎片,影响计算性能。可以说合适部署应用的配置。
第二种和第三种适合多人使用一台服务器的情况,但第二种存在浪费显存的情况,第三种在一定程序上避免了显存的浪费,但极容易出现程序由于申请不到内存导致崩溃的情况。
4 指定GPU
在有多块GPU的服务器上运行tensorflow的时候,如果使用python编程,则可指定GPU,代码如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"