今天使用到了GPU来加速计算,那种感觉简直就是一飞冲天了,临近毕业季,大家都在做实验,服务器早已是不堪重负了,我们屋的服务器一堆人再用,卡到爆炸,训练一个模型粗略计算一下迭代100次就需要3、4天的时间,得不偿失,正好隔壁有一台闲置的GPU深度学习服务器,决定上手搞一搞。
深度学习我也是初步接触,果断选择最简单的keras来入门,网上关于Tensorflow和Theano的GPU加速的相关配置有很多,但是是否适用于Keras还有待考量,今天就简单试验一下。
首先我们查看一下服务器GPU的配置
nivdia-smi
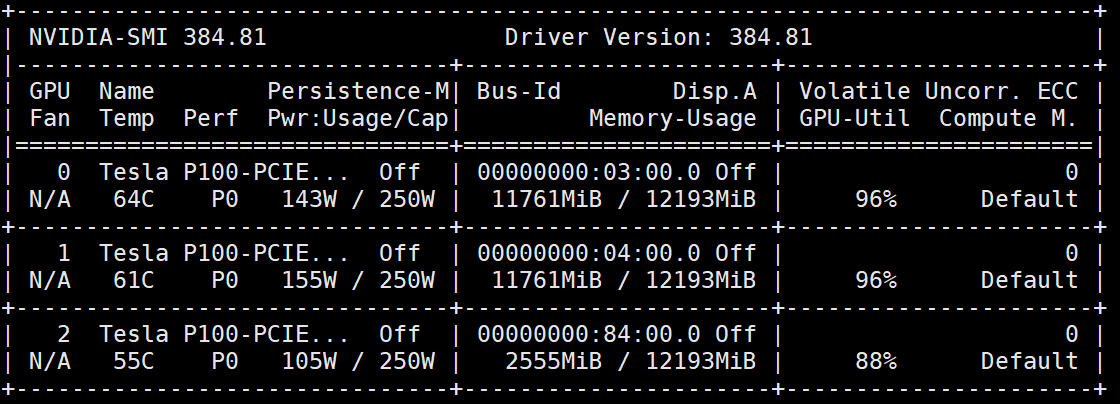
可以看到,我们由块显卡,实验中为了避免不同使用者的资源竞争,我们需要指定适用哪块GPU来实验。
我使用的是Python,在代码开始部分加入:
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
就可以使用0号显卡了,如果想使用多块显卡就可以使用:
os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2"
当然如果想更精细地分配GPU的使用量还可以这么写:
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 占用GPU50%的显存
session = tf.Session(config=config)
我是深度学习小白,欢迎交流!