在用tensorflow训练深度学习模型的时候,假设我们在训练之前没有指定GPU来进行训练,则默认的是选用第0块GPU来训练我们的模型,而且其它几块GPU的也会显示被占用。有些时候,我们更希望可以通过自己指定一块或者几块GPU来训练我们的模型,而不是用这种默认的方法。接下来将简单介绍两种简单的方法。
我们现有的GPU个数如下所示:

1.第一种是通过tf.device()函数来指定训练时所要使用的GPU.
假设我们要用我们的第2块GPU来训练模型,此时可以通过下面的代码来指定:
tf.device('/gpu:2')
实验效果如下:
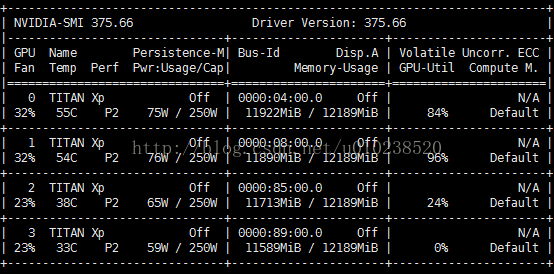
我们可以看到,虽然指定了第2块GPU来训练,但是其它几个GPU也还是被占用,只是模型训练的时候,是在第2块GPU上进行。
2.通过CUDA_VISIBLE_DEVICES来指定.
同样使用第2块GPU来训练模型,我们可以在我们的python代码中加入:
-
import os
-
os.environ[
'CUDA_VISIBLE_DEVICES']=
'2'
实验效果如下:
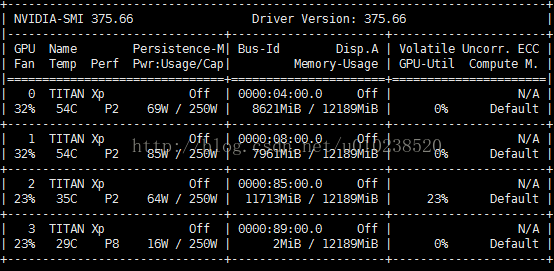
我们可以看到,在训练模型的时候,使用了第2块GPU,并且其它几块GPU也没有被占,这种就相当于在我们运行程序的时候,将除第2块以外的GPU全部屏蔽了,只有第2块GPU对当前运行的程序是可见的。同样,如果要指定2,3块GPU来训练,则上面的代码可以改成:
os.environ['CUDA_VISIBLE_DEVICES']='2,3'
类似的如果还有更多的GPU要指定,都可以仿照上面的代码进行添加。
这种方法还可以在运行python程序的前面指定,比如:
CUDA_VISIBLE_DEVICES=2 python train.py实现的功能就和上面的代码一样。
参考链接: