相关博客:
Thread 类中有这样一个构造函数:
Thread
public Thread(ThreadGroup group, Runnable target, String name, long stackSize)分配新的
Thread对象,以便将target作为其运行对象,将指定的name作为其名称,作为group所引用的线程组的一员,并具有指定的 堆栈大小。除了允许指定线程堆栈大小以外,这种构造方法与
Thread(ThreadGroup,Runnable,String)完全一样。堆栈大小是虚拟机要为该线程堆栈分配的地址空间的近似字节数。stackSize 参数(如果有)的作用具有高度的平台依赖性。在某些平台上,指定一个较高的 stackSize 参数值可能使线程在抛出
StackOverflowError之前达到较大的递归深度。同样,指定一个较低的值将允许较多的线程并发地存在,且不会抛出OutOfMemoryError(或其他内部错误)。stackSize 参数的值与最大递归深度和并发程度之间的关系细节与平台有关。在某些平台上,stackSize 参数的值无论如何不会起任何作用。作为建议,可以让虚拟机自由处理 stackSize 参数。如果指定值对于平台来说过低,则虚拟机可能使用某些特定于平台的最小值;如果指定值过高,则虚拟机可能使用某些特定于平台的最大值。 同样,虚拟机还会视情况自由地舍入指定值(或完全忽略它)。
将 stackSize 参数值指定为零将使这种构造方法与 Thread(ThreadGroup, Runnable, String) 构造方法具有完全相同的作用。
由于这种构造方法的行为具有平台依赖性,因此在使用它时要非常小心。执行特定计算所必需的线程堆栈大小可能会因 JRE 实现的不同而不同。鉴于这种不同,仔细调整堆栈大小参数可能是必需的,而且可能要在支持应用程序运行的 JRE 实现上反复调整。
实现注意事项:鼓励 Java 平台实现者文档化其 stackSize parameter 的实现行为。
参数:
group- 线程组。
target- 其run方法被调用的对象。
name- 新线程的名称。
stackSize- 新线程的预期堆栈大小,为零时表示忽略该参数。抛出:
SecurityException- 如果当前线程无法在指定的线程组中创建线程。从以下版本开始:
1.4
有一个 stackSize 参数 ,结合 JDK 的描述,stackSize 与平台是有一定关系的,在某些平台上,stackSize 参数的值无论如何不会起任何作用。
结合注释:
/*
* The requested stack size for this thread, or 0 if the creator did
* not specify a stack size. It is up to the VM to do whatever it
* likes with this number; some VMs will ignore it.
*/
private long stackSize;如果未指定该参数,默认是 0,JVM 会忽略该参数,猜想应该会交由其他 native 方法控制。
JVM 在执行 Java 程序的时候会把对应的物理内存划分成不同的内存区域,每一个区域都存放着不同的数据,也有不同的创建与销毁时机,有些分区会在 JVM 启动的时候就创建,有些则是在运行时才创建,比如虚拟机栈,根据虚拟机规范,JVM 的内存结构如下:

程序计数器
无论任何语言,其实最终都是需要由操作系统通过控制总线向 CPU 发送机器指令,Java 也不例外,程序计数器在 JVM 中所起的作用就是用于存放当前线程接下来将要执行的字节码指令、分支、循环、跳转、异常处理等信息。在任何时候,一个处理器只执行其中一个线程中的指令,为了能够在 CPU 时间片轮转切换上下文之后顺利回到正确的执行位置,每条线程都需要具有一个独立的程序计数器,各个线程之间互相不影响,因此 JVM 将此块内存区域设计成了线程私有的。
Java 虚拟机栈
其与线程紧密关联,与程序计数器内存相类似,Java 虚拟机栈也是线程私有的,它的生命周期与线程相同,是在 JVM 运行时所创建的,在线程中,方法在执行的时候都会创建一个名为栈帧(stack frame)的数据结构,主要用于存放局部变量表、操作栈、动态链接、方法出口等信息,方法的调用对应着栈帧在虚拟机栈中的压栈和弹栈过程。

每一个线程在创建的时候,JVM 都会为其创建对应的虚拟机栈,虚拟机栈的大小可以通过 -xss 来配置,方法的调用是栈帧被压入和弹出的过程。同等的虚拟机栈如果局部变量表等占用内存越小则可被压人的栈帧就会越多,反之则可被压人的栈帧就会越少,一般将栈帧内存的大小称为宽度,而栈帧的数量则称为虚拟机栈的深度。
本地方法栈
Java 中提供了调用本地方法的接口(Java Native Interface),也就是 C/C++ 程序,在线程的执行过程中,经常会碰到调用 JNI 方法的情况,比如网络通信、文件操作的底层,甚至是 String 的 intern 等都是 JNI 方法,JVM 为本地方法所划分的内存区域便是本地方法栈,这块内存区域其自由度非常高,完全靠不同的 JVM 厂商来实现,Java 虚拟机规范并未给出强制的规定,同样它也是线程私有的内存区域。
堆内存
堆内存是 JVM 中最大的一块内存区域,被所有的线程所共享,Java 在运行期间创建的所有对象几乎都存放在该内存区域,该内存区域也是垃圾回收器重点照顾的区域,因此有些时候堆内存被称为“GC 堆”。
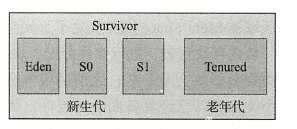
堆内存一般会被细分为新生代和老年代,更细致的划分为 Eden 区、From Survivo 区和 To Survivor 区。
方法区
方法区也是被多个线程所共享的内存区域,他主要用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器(JIT )编译后的代码等数据,虽然在 Java 虚拟机规范中,将堆内存划分为堆内存的一个逻辑分区,但是它还是经常被称为“非堆”,有时候也被称为“持久代”,主要是站在垃圾回收器的角度进行划分,但是这种叫法比较欠妥,在 HotSpot JVM 中,方法区还会被细划分为持久代和代码缓存区,代码缓存区主要用于存储编译后的本地代码(和硬件相关)以及 JIT(Just In Time)编译器生成的代码,当然不同的 JVM 会有不同的实现。
Java 8 元空间
上述内容大致介绍了 JVM 的内存划分,在 JDK 1.8 版本以前的内存大概都是这样划分的,但是自 JDK 1.8 版本起,JVM 的内存区域发生了一些改变,实际上是持久代内存被彻底删除,取而代之的是元空间,下图是使用分别使用不同版本的jstat命令对比
JVM 的 GC 内存分布。
JDK 1.7 版本的 jstat:

JDK 1.8 版本的 jstat:

通过对比会发现在 JDK 1.7 版本中存在持久代内存区域,而在 JDK 1.8 版本中,该内存区域被 Meta Space 取而代之了,元空间同样是堆内存的一部分,JVM 为每个类加载器分配一块内存块列表,进行线性分配,块的大小取决于类加载器的类型,sun/反射/代理对应的类加载器块会小一些,之前的版本会单独卸载回收某个类,而现在则是 GC 过程中发现某个类加载器已经具备回收的条件,则会将整个类加载器相关的元空间全部回收,这样就可以减少内存碎片,节省 GC 扫描和压缩的时间。
package com.example.threaddesign;
/**
* @author Dongguabai
* @date 2018/12/2 20:58
*/
//class 的一些信息也是放在方法区
public class ThreadTest {
//存放在方法区
private static int i = 0;
//引用地址会放到方法区,具体数据会放到堆
private byte[] bytes = new byte[1024];
//JVM 会创建 main 线程
public void main(String[] args) {
//会为 main 线程开辟一个虚拟机栈
//告诉 CPU下一步要执行什么,需要程序计数器
// m 直接放到局部变量表
int m = 1;
//局部变量表中会有 arr 的地址,数据还是放到堆中
int[] arr = new int[1024];
}
}
演示这样一段代码,一个很简单的无限递归操作,会进行无数个栈操作:
package com.example.threaddesign;
/**
* @author Dongguabai
* @date 2018/12/2 20:58
*/
public class ThreadTest {
private static int COUNT = 0;
public static void main(String[] args) {
try {
add(0);
} catch (Error error) {
error.printStackTrace();
System.out.println(COUNT);
}
}
private static void add(int i) {
COUNT++;
add(i + 1);
}
}
很明显会出现异常,运行结果:
Exception in thread "main" java.lang.StackOverflowError
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
at com.example.threaddesign.ThreadTest.add(ThreadTest.java:14)
...
23542这是一个 Error 级别的异常,栈溢出,即栈操作了 23542 次。
再回过头来看 long stackSize 参数:
除了允许指定线程堆栈大小以外,这种构造方法与
Thread(ThreadGroup,Runnable,String)完全一样。堆栈大小是虚拟机要为该线程堆栈分配的地址空间的近似字节数。stackSize 参数(如果有)的作用具有高度的平台依赖性。在某些平台上,指定一个较高的 stackSize 参数值可能使线程在抛出
StackOverflowError之前达到较大的递归深度。同样,指定一个较低的值将允许较多的线程并发地存在,且不会抛出OutOfMemoryError(或其他内部错误)。stackSize 参数的值与最大递归深度和并发程度之间的关系细节与平台有关。在某些平台上,stackSize 参数的值无论如何不会起任何作用。作为建议,可以让虚拟机自由处理 stackSize 参数。如果指定值对于平台来说过低,则虚拟机可能使用某些特定于平台的最小值;如果指定值过高,则虚拟机可能使用某些特定于平台的最大值。 同样,虚拟机还会视情况自由地舍入指定值(或完全忽略它)。
将 stackSize 参数值指定为零将使这种构造方法与 Thread(ThreadGroup, Runnable, String) 构造方法具有完全相同的作用。
由于这种构造方法的行为具有平台依赖性,因此在使用它时要非常小心。执行特定计算所必需的线程堆栈大小可能会因 JRE 实现的不同而不同。鉴于这种不同,仔细调整堆栈大小参数可能是必需的,而且可能要在支持应用程序运行的 JRE 实现上反复调整。
结合这段描述,我们可以根据指定 stackSize 的大小来控制“最大递归深度”,但是由于现在这段测试代码是在 main() 方法中执行的,而 main 线程是 JVM 创建的,我们无法指定 stackSize 的大小,接下来再这样测试:
package com.example.threaddesign;
/**
* @author Dongguabai
* @date 2018/12/2 20:58
*/
public class ThreadTest {
private static int COUNT_1 = 0;
public static void main(String[] args) {
new Thread(null,()->{
try {
add_1(0);
} catch (Error error) {
error.printStackTrace();
System.out.println(Thread.currentThread().getName()+"--->"+COUNT_1);
}
},"Thread-1",1<<24).start();
}
private static void add_1(int i) {
COUNT_1++;
add_1(i + 1);
}
}
输出结果:
java.lang.StackOverflowError
at com.example.threaddesign.ThreadTest.add_1(ThreadTest.java:25)
at com.example.threaddesign.ThreadTest.add_1(ThreadTest.java:25)
...
Thread-1--->1019821再更改 stackSize 的大小为 1<<12,运行结果:
java.lang.StackOverflowError
at com.example.threaddesign.ThreadTest.add_1(ThreadTest.java:25)
at com.example.threaddesign.ThreadTest.add_1(ThreadTest.java:25)
...
Thread-1--->36810可以很明显的看出区别。
但是要注意的是 JVM 创建的栈的大小事没变的,也就是说如果一个线程在虚拟机栈中占用的栈空间过大,那么相应的可以并发的线程的数量就少了。那么带着这个猜想再测试一下:
虚拟机栈内存是线程私有的,也就是说每一个线程都会占有指定的内存大小,我们粗略地认为一个 Java 进程的内存大小为:堆内存 + 线程数量 * 栈内存。
不管是 32 位操作系统还是 64 位操作系统,一个进程的最大内存是有限制的,比如 32 位的 Windows 操作系统所允许的最大进程内存为 2 GB,因此根据上面的公式很容易得出,线程数量与栈内存的大小是反比关系,那么线程数量与堆内存的大小关系呢?当然也是反比关系,只不过堆内存是基数,而栈内存是系数而已。