文章目录
产生背景
每个Spark应用程序从读取数据开始,到保存数据结束
- 加载和保存数据是不容易的
比如大数据场景解析关系型数据库需要用工具如sqoop将数据转到hbase等。 - 解析原始数据也不容易 :text/json/parquet
- 数据直接的转换也麻烦
- 数据集存储在各个存储系统中无法统一拉取和推送
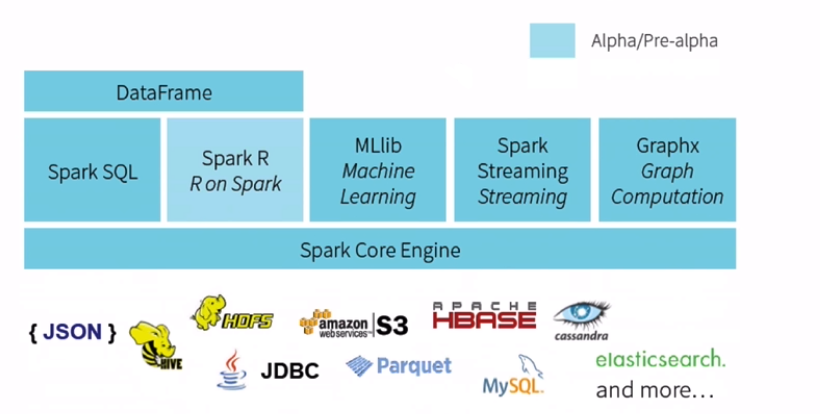
用户的需要:
方便快速从不同的数据源(json、parquet、rdbms),经过混合处理(json join parquet),再将处理结果以特定的格式(json、parquet)写回到指定的系统(HDFS、S3)上去
Spark SQL 1.2 ==> 外部数据源API
概念
External Data Source API
- 一种集成各种外部数据的扩展方法
- 可以使用各种格式和存储系统读写DataFrame
- Data Source API可以自动裁剪列和推送过滤器到源(谓词下推):parquet/JDBO
- Data Source API在Spark 1.2提出
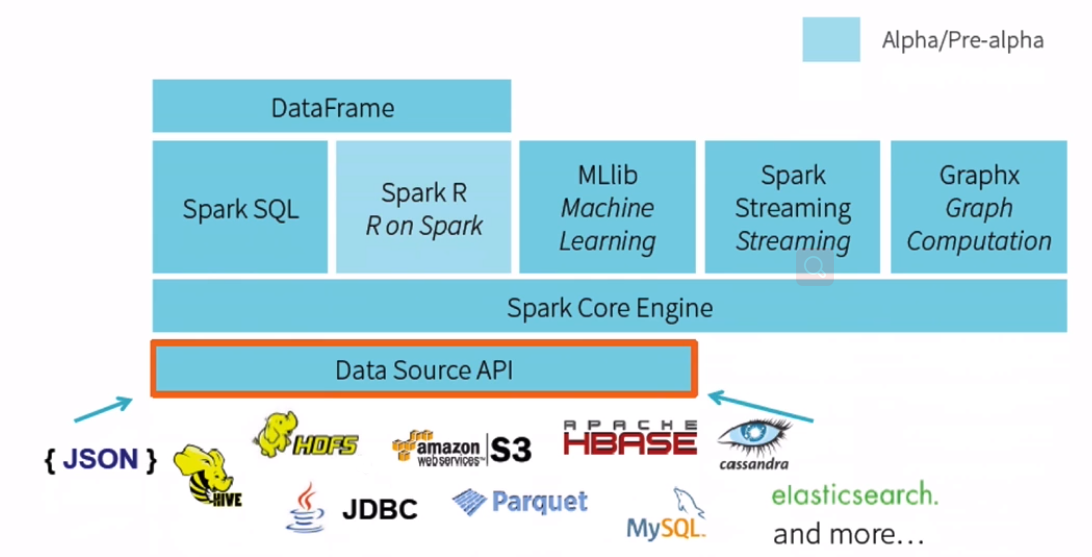
目标
- 对于开发人员只需要构建针对外部数据源的库
开发人员:是否需要把代码合并到spark中????
比如weibo数据只需要通过–jars传入就行。 - 对于使用人员通过DataFrames很容易加载和保持数据源
用户
读:spark.read.format(format)
format
build-in:内置的 json parquet jdbc csv(2.0+后属于内置)
packages: 外部的比如微博的数据 并不是spark内置 https://spark-packages.org/
写:people.write.format(“parquet”).save(“path”)
操作Parquet文件数据
parquet是无法直接查看的;所以这里就不提供数据了
- spark.read.format(“parquet”).load(path)
- df.write.format(“parquet”).save(path)
package com.kun.ExternalDataSource
import org.apache.spark.sql.SparkSession
/**
* Parquet文件操作
*/
object ParquetApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkSessionApp")
.master("local[2]").getOrCreate()
/**
* spark.read.format("parquet").load 这是标准写法
*/
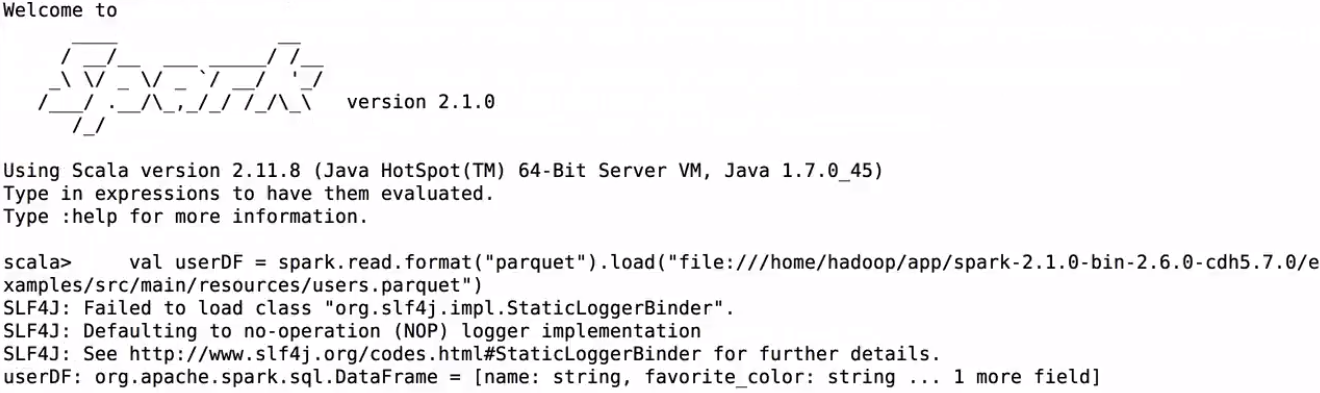
val userDF = spark.read.format("parquet").load("file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet")
userDF.printSchema()
userDF.show()
userDF.select("name","favorite_color").show
userDF.select("name","favorite_color").write.format("json").save("file:///home/hadoop/tmp/jsonout")
spark.read.load("file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet").show
//会报错,因为sparksql默认处理的format就是parquet
spark.read.load("file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json").show
spark.read.format("parquet").option("path","file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet").load().show
spark.stop()
}
}
启动spark-shell来测试;速度快

加载parquet数据
数据类型

查看所有列

只保存前两列



spark默认处理parquet数据
spark.read.load(“file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json”).show
会报错:
RuntimeException: file:/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json is not a Parquet file
//源码中:
val DEFAULT_DATA_SOURCE_NAME = SQLConfigBuilder("spark.sql.sources.default")
.doc("The default data source to use in input/output.")
.stringConf
.createWithDefault("parquet")
利用spark中的sql来处理parquet
#注意USING的用法
CREATE TEMPORARY VIEW parquetTable
USING org.apache.spark.sql.parquet
OPTIONS (
path "/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet"
)
SELECT * FROM parquetTable
读取parquet很多种写法

操作Hive表数据
- spark.table(tableName)
- df.write.saveAsTable(tableName)
测试数据:
dept表
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
emp表
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.00
前置条件:启动spark-shell
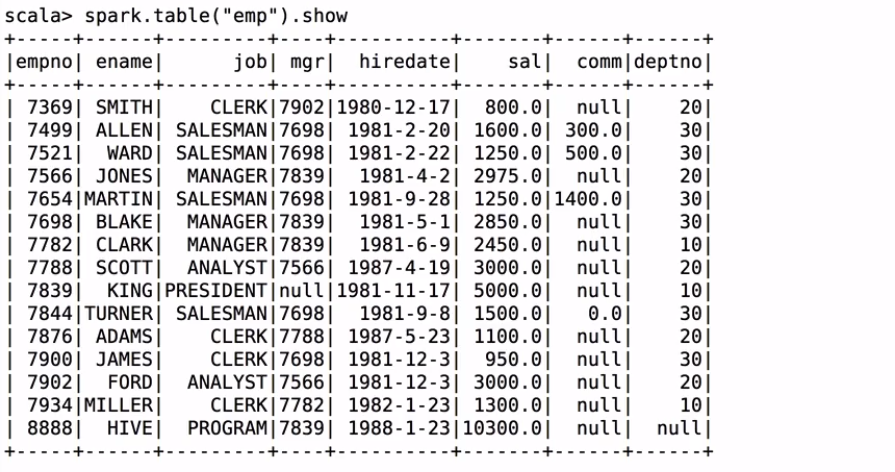
查看hive表:

遍历emp
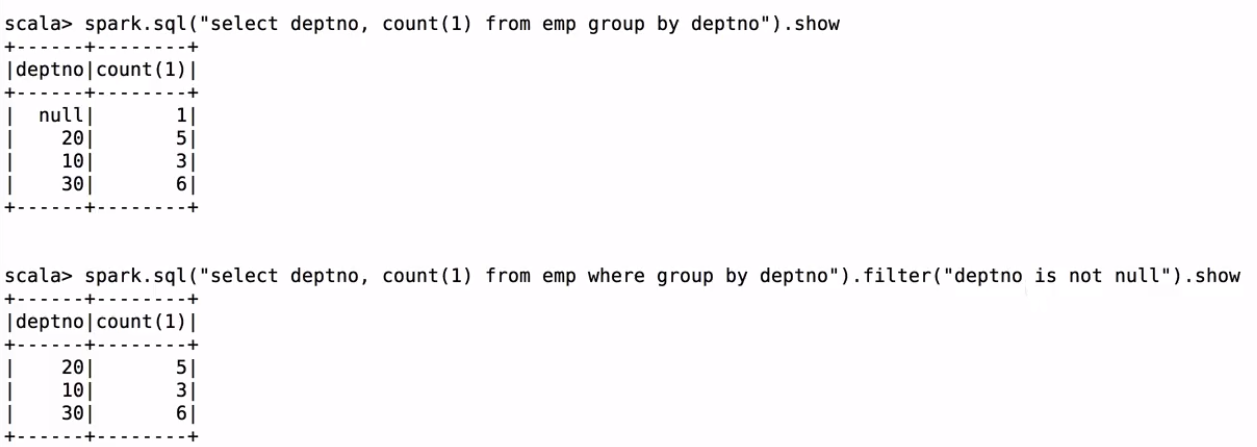
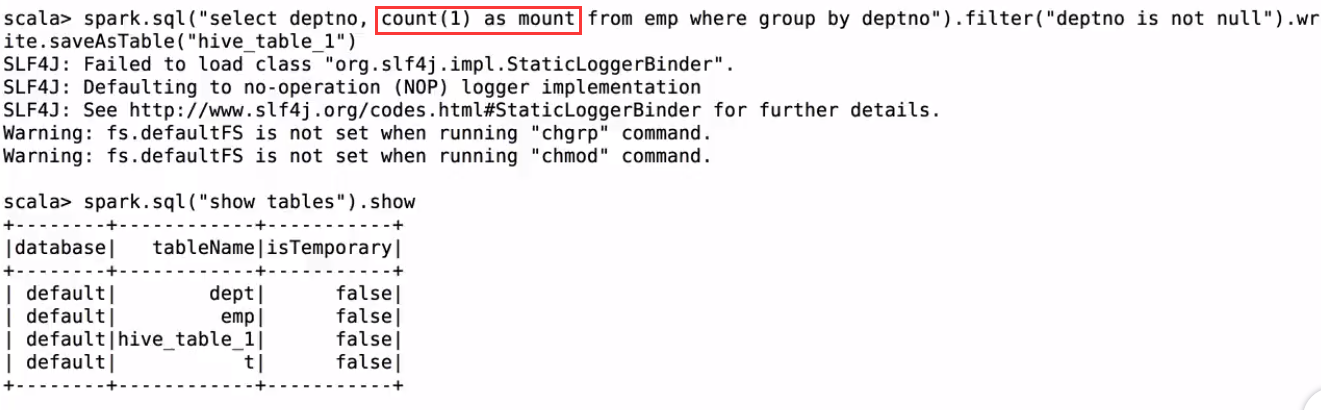
spark.sql("select deptno, count(1) as mount from emp where group by deptno").filter("deptno is not null").write.saveAsTable("hive_table_1")
//会报错:
org.apache.spark.sql.AnalysisException: Attribute name "count(1)" contains invalid character(s) among " ,;{}()\n\t=". Please use alias to rename it.;
将数据写入hive

注意:
spark.sqlContext.setConf(“spark.sql.shuffle.partitions”,“10”)配置的是分区的数量
在生产环境中一定要注意设置spark.sql.shuffle.partitions,默认是200

操作MySQL表数据

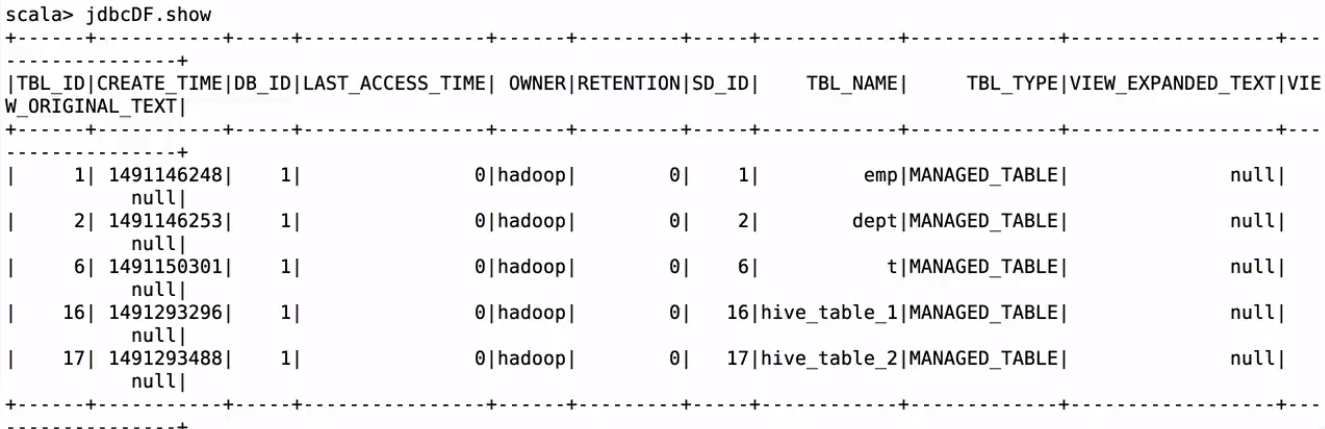
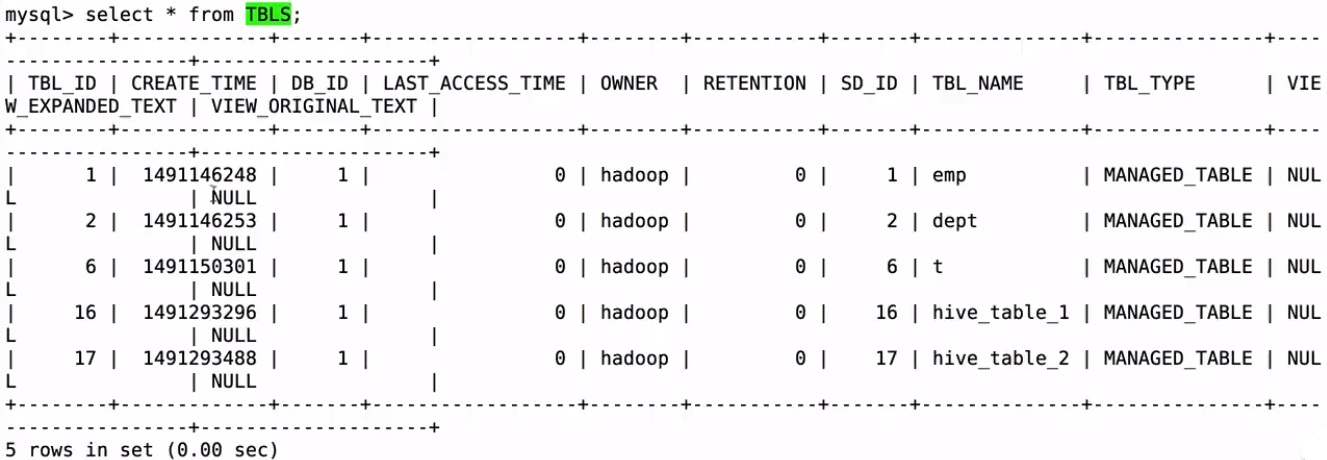
操作MySQL的数据方法一:
spark.read.format(“jdbc”).option(“url”, “jdbc:mysql://localhost:3306/hive”).option(“dbtable”, “hive.TBLS”).option(“user”, “root”).option(“password”, “root”).option(“driver”, “com.mysql.jdbc.Driver”).load()
不加option(“driver”, “com.mysql.jdbc.Driver”)会有错误:java.sql.SQLException: No suitable driver
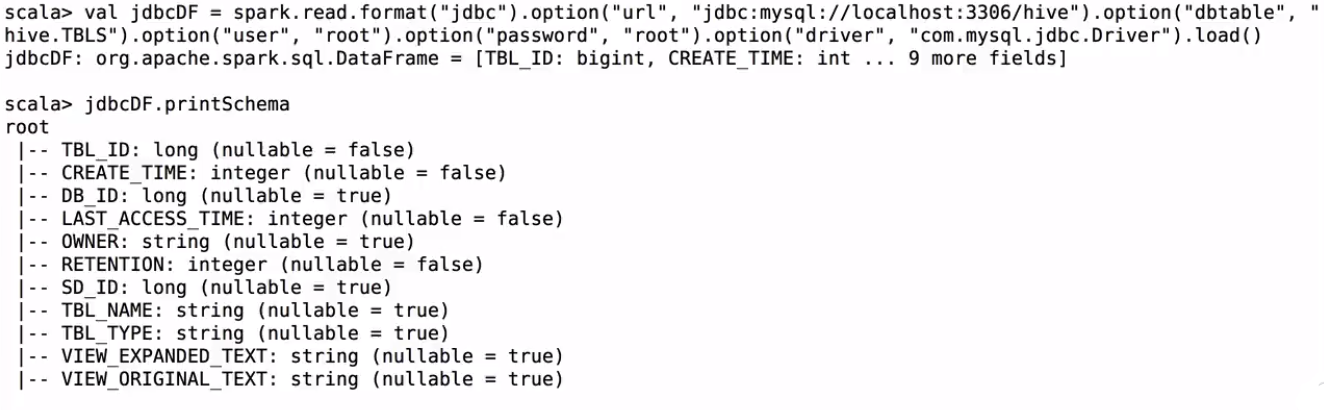
可以看到结构和mysql里的是一样的
指定列输出:

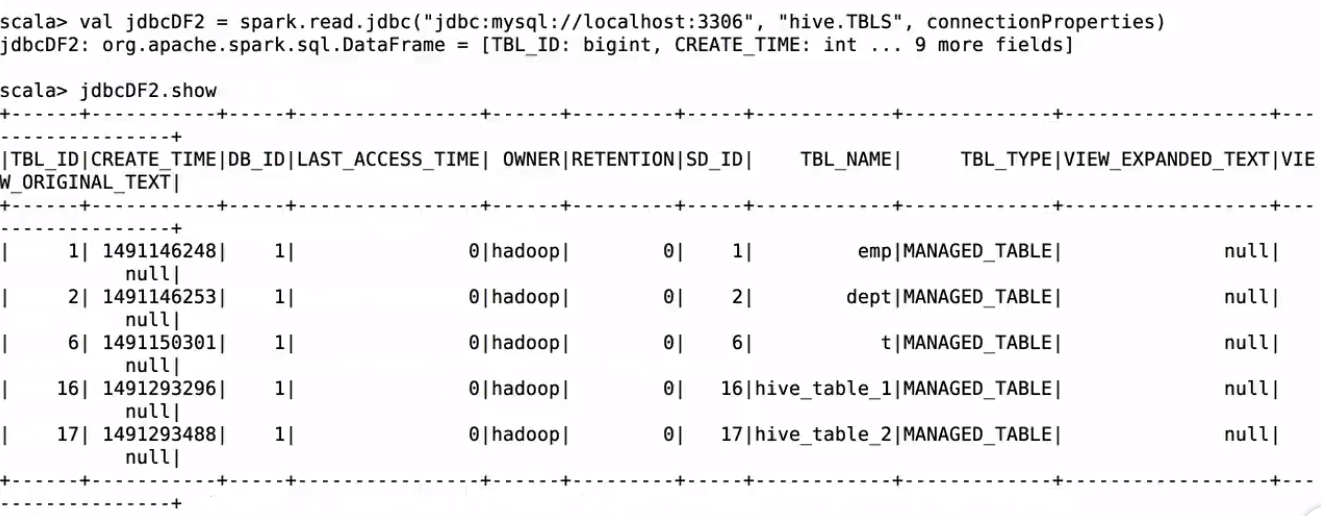
操作MySQL的数据方法二:
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")
connectionProperties.put("driver", "com.mysql.jdbc.Driver")
val jdbcDF2 = spark.read.jdbc("jdbc:mysql://localhost:3306", "hive.TBLS", connectionProperties)
在spark-shell里测试

写入MySQL
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save()
jdbcDF2.write
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
操作MySQL的数据方法三:
进入spark sql操作
CREATE TEMPORARY VIEW jdbcTable
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://localhost:3306",
dbtable "hive.TBLS",
user 'root',
password 'root',
driver 'com.mysql.jdbc.Driver'
)

show tables

select * from jdbctable;

Hive和MySQL综合使用
关联MySQL和Hive表数据关联操作
外部数据源综合案例
在MySQL里创建:
create database spark;
use spark;
CREATE TABLE DEPT(
DEPTNO int(2) PRIMARY KEY,
DNAME VARCHAR(14) ,
LOC VARCHAR(13) ) ;
INSERT INTO DEPT VALUES(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES(20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES(40,'OPERATIONS','BOSTON');
进行下列两表的jion

package com.kun.ExternalDataSource
import org.apache.spark.sql.SparkSession
/**
* 使用外部数据源综合查询Hive和MySQL的表数据
*/
object HiveMySQLApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("HiveMySQLApp")
.master("local[2]").getOrCreate()
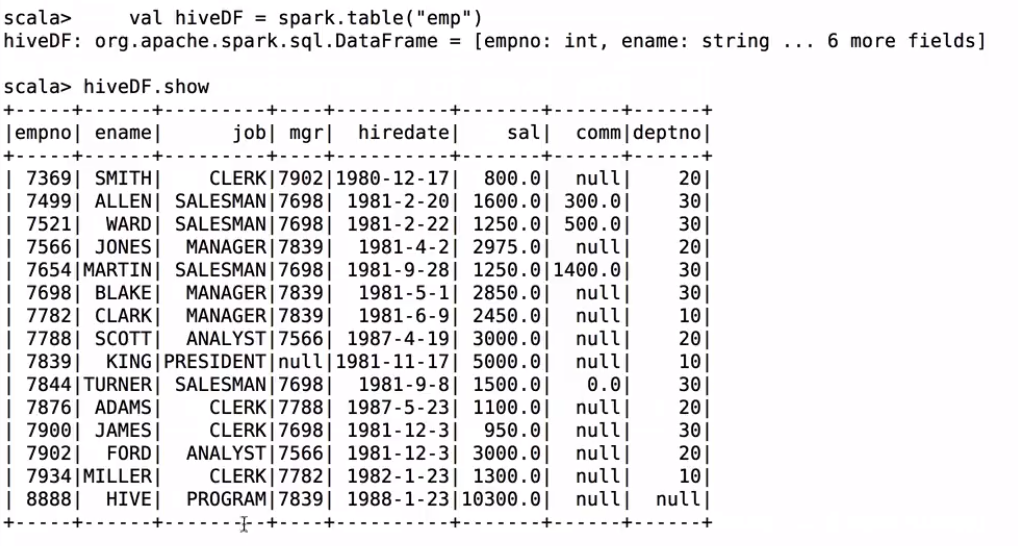
// 加载Hive表数据
val hiveDF = spark.table("emp")
// 加载MySQL表数据
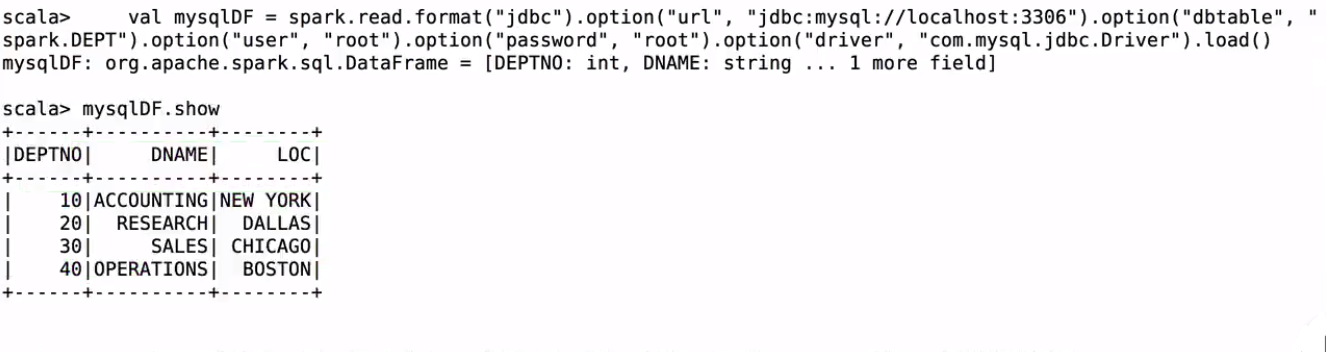
val mysqlDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306").option("dbtable", "spark.DEPT").option("user", "root").option("password", "root").option("driver", "com.mysql.jdbc.Driver").load()
// JOIN
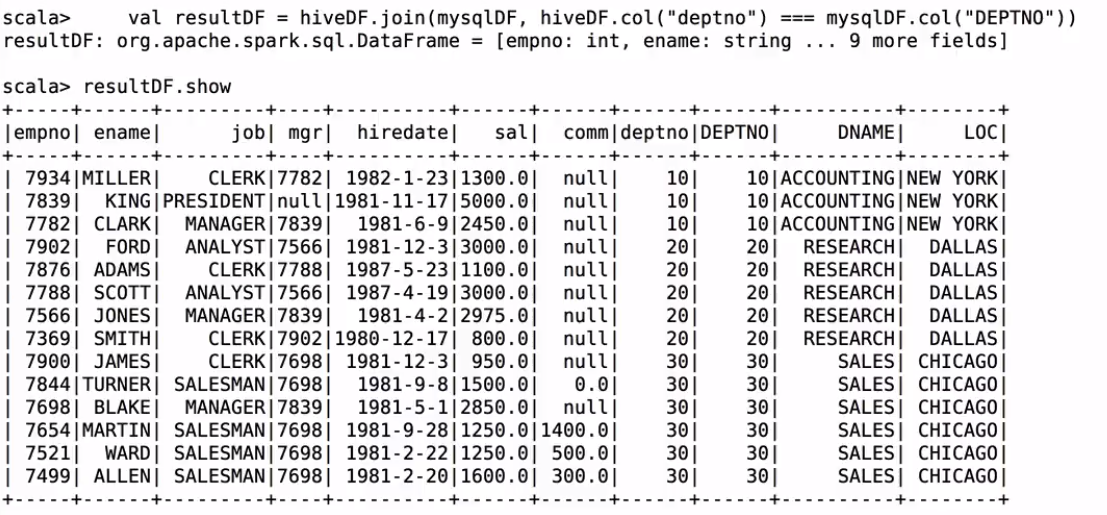
val resultDF = hiveDF.join(mysqlDF, hiveDF.col("deptno") === mysqlDF.col("DEPTNO"))
resultDF.show
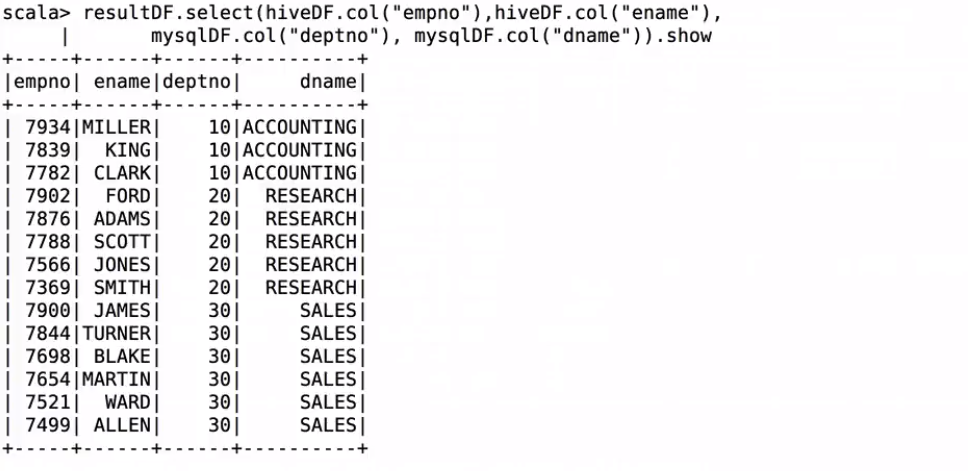
resultDF.select(hiveDF.col("empno"),hiveDF.col("ename"),
mysqlDF.col("deptno"), mysqlDF.col("dname")).show
spark.stop()
}
}
spark-shell里测试
同理json;parquet;csv等都是可以进行同样操作的。