Spark SQL
一、准备工作
创建maven工程,添加pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.template.spark</groupId>
<artifactId>spark2mhh</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.14.2</hadoop.version>
<hive.version>1.1.0-cdh5.14.2</hive.version>
<hbase.version>1.2.0-cdh5.14.2</hbase.version>
<scala.version>2.11.12</scala.version>
<spark.version>2.4.4</spark.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!-- spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${
scala.version}</version>
</dependency>
<!-- spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--java打包插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--scala打包插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
</executions>
</plugin>
<!--将依赖打入jar包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
linux下
(1)将hive110/conf目录下的hive-site.xml文件创建软连接到spark/conf目录下
软连接的作用:在hive下修改xml文件时,spark下也会生效,保证两个服务下配置相同
ln -s /opt/software/hadoop/hive110/conf/hive-site.xml /opt/software/hadoop/spark244/conf/hive-site.xml
(2)将hive/lib目录下的mysql-connector-java-5.1.32.jar 拷贝到spark/jars
cp mysql-connector-java-5.1.32.jar /opt/software/hadoop/spark244/jars/
IDEA下
1.将hive-site.xml文件拷贝到resources资源文件夹下,将元数据地址补全,修改密码为远程登陆mysql的密码(如果本地密码和远程密码相同,无需操作这一步)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://192.168.247.130:9000/opt/software/hadoop/hive110/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.247.130:3306/hive110?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>javakb10</value>
</property>
</configuration>
2.添加log4j.properties日志文件到resources
log4j.rootLogger=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
二、Spark连接Hive
测试代码
package sql
import org.apache.spark.sql.{
DataFrame, SparkSession}
object spark2hive {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark: SparkSession = SparkSession.builder()
.master("local[4]") // 设置master
.appName(this.getClass.getName) // 设置appname
.enableHiveSupport() //开启Hive支持
.getOrCreate()
// 读取Hive中数据表
val df: DataFrame = spark.sql("select * from student")
df.show()
}
}
结果
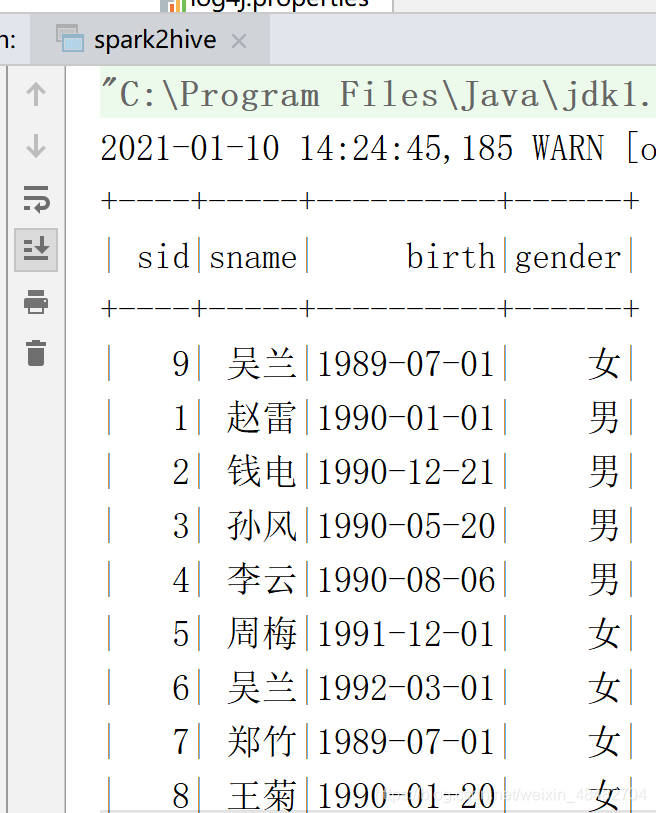
扫描二维码关注公众号,回复:
12993870 查看本文章

三、Spark连接MySQL
测试代码
package sql
import java.util.Properties
import org.apache.spark.sql.{
DataFrame, SparkSession}
object spark2mysql {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getName)
.master("local[4]")
.getOrCreate()
//设置要访问的mysql的url,表名
val url = "jdbc:mysql://192.168.247.130:3306/mysqltest"
val tablename ="student"
val props = new Properties()
//设置要访问的mysql的用户名,密码,Driver
props.setProperty("user","root")
props.setProperty("password","javakb10")
props.setProperty("driver","com.mysql.jdbc.Driver")
//通过spark.read.jdbc方法读取mysql中的数据
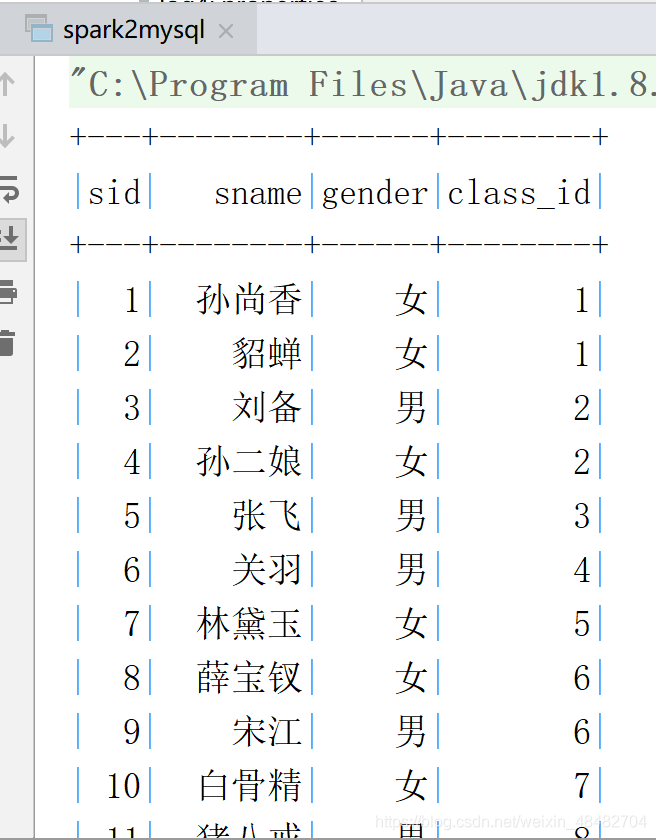
val df: DataFrame = spark.read.jdbc(url,tablename,props)
df.show()
//通过append追加方式,更新原表
df.write.mode("append").jdbc(url, tablename, props)
//创建临时表score2,并使用spark.sql查询临时表中的数据
df.createOrReplaceTempView("score1")
spark.sql("select * from score1").show()
}
}
结果
四、Spark连接HBase
添加依赖,必须在最后面加,否则会引起jar包冲突
<!-- spark-hbase -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${
hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${
hbase.version}</version>
</dependency>
pom具体内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.template.spark</groupId>
<artifactId>spark2mhh</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.14.2</hadoop.version>
<hive.version>1.1.0-cdh5.14.2</hive.version>
<hbase.version>1.2.0-cdh5.14.2</hbase.version>
<scala.version>2.11.12</scala.version>
<spark.version>2.4.4</spark.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!-- spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${
scala.version}</version>
</dependency>
<!-- spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<!-- spark-graphx -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${
hadoop.version}</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<!-- kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
<!-- spark-hbase -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${
hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${
hbase.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--java打包插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--scala打包插件-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
</executions>
</plugin>
<!--将依赖打入jar包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
测试代码
1.读HBase
package sql
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.spark.sql.SparkSession
import org.apache.hadoop.hbase.util.Bytes
object sparkReadHBase {
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","single")
conf.set("hbase.zookeeper.property.clientPort","2181")
conf.set(TableInputFormat.INPUT_TABLE,"HStudent")
val spark = SparkSession.builder().appName("Spark2HBase")
.master("local[4]")
.getOrCreate()
val sc= spark.sparkContext
val rdd1= sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
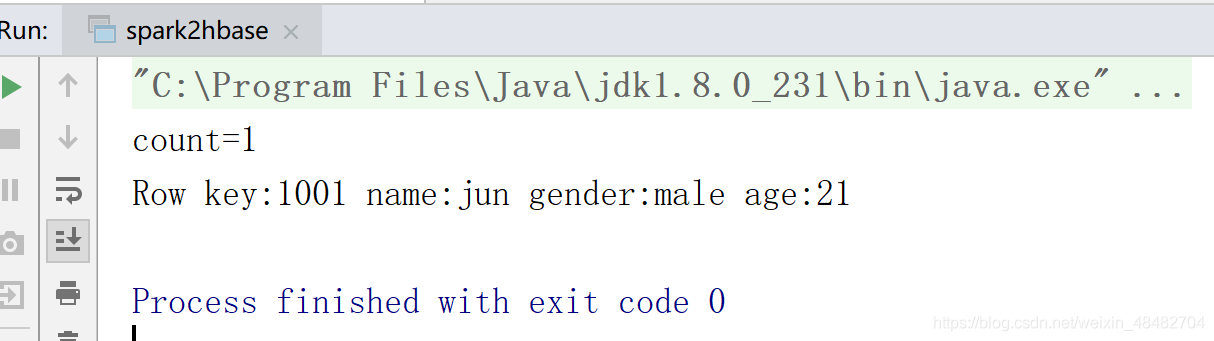
println("count="+rdd1.count())
import spark.implicits._
//遍历输出
rdd1.foreach({
case (_,result) =>
//通过result.getRow来获取行键
val key = Bytes.toString(result.getRow)
//通过result.getValue("列簇","列名")来获取值
//需要使用getBytes将字符流转化为字节流
val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes))
val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes))
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes))
println("Row key:"+key+" name:"+name+" gender:"+gender+" age:"+age)
})
sc.stop()
}
}
结果
2.写入HBase
package sql
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object sparkWriteHBase {
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","single")
conf.set("hbase.zookeeper.property.clientPort","2181")
val jobConf = new mapred.JobConf(conf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE,"HStudent")
val spark = SparkSession.builder().appName("Spark2HBase")
.master("local[4]")
.getOrCreate()
val sc= spark.sparkContext
//往HBase中插入两条数据
val dataRDD: RDD[String] = sc.makeRDD(Array("1002,22,男,凯","1003,34,女,情"))
val rdd: RDD[(ImmutableBytesWritable, Put)] = dataRDD.map(_.split(",")).map({
arr => {
// 一个Put对象就是一行记录,在构造方法中指定主键
// 所有插入的数据必须用org.apache.hadoop.hbase.util.Bytes.toBytes方法转换
//Put.add方法接收三个参数:列族,列名,数据
val put = new Put(Bytes.toBytes(arr(0)))
put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(arr(1)))
put.add(Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes(arr(2)))
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(arr(3)))
//必须有这两个返回值,put为要传入的数据
//转化成RDD[(ImmutableBytesWritable,Put)]类型才能调用saveAsHadoopDataset
(new ImmutableBytesWritable, put)
}
})
rdd.saveAsHadoopDataset(jobConf)
sc.stop()
}
}
再次执行sparkReadHBase后,运行结果如下
