写在前面:
本系列笔记主要记录本人在阅读过程中的收获,尽量详细到实现层次,水平有限,欢迎留言指出问题~
这篇文章被认为是深度学习应用于目标检测的开山之作,自然是要好好读一下的,由于文章是前些日子读的,所以仅凭记忆把印象深刻的地方记录一下,许多地方是自己理解,有错误请指出。
1. 算法的流程
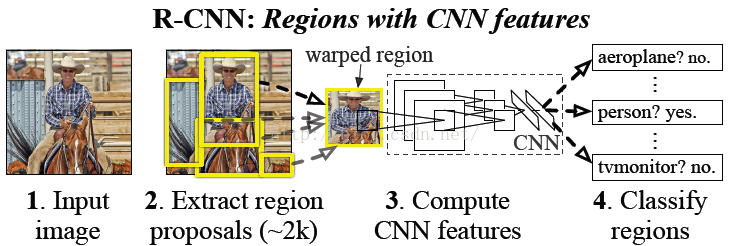
这篇文章干了一件什么事情呢,就是用selective search生成一堆建议区域,然后把这些建议区域根据一定的准则做成分类训练集,微调预训练的CNN,C然后用CNN提取的特征和对应的类别训练SVM二分类器,最后经过非极大值抑制过滤后得到的结果对应的region proposal就作为检测边框。预测的时候,要对每一个region proposal执行一次CNN+SVM。
我理解的是,CNN(或者说CNN+SVM)在RCNN中仍然只是一个分类模型,对selective search生成的region proposals进行分类,经过后处理,留下的被判定为目标的region proposal就作为最后的检测结果。
2. 训练细节
2.1 生成候选区域
作者使用selective search算法生成大约2k个就建议区域,这是一个传统算法,组合多种策略和人工特征可以直接给出合乎条件的目标区域。这里的问题是,生成的边框尺寸大小不一,背景多目标少,很多只能框住目标的一部分,这些对后面的训练策略有影响。
2.2 微调预训练的CNN
作者先在公开数据集上预训练了一个CNN的分类模型,然后在当前任务上微调。具体的,上一步生成一堆建议区域有很多只框住了目标的一部分,作者把IoU>0.5的认定为正样本,其余的为负样本,于是形成了一个分类的训练集,以此来微调模型。
这里面还有个细节,上一步生成的一堆建议区域,并不能直接送入CNN,因为当时的CNN分类模型都是若干卷积层+全连接层这样的结构,因为全连接层的缘故,模型的输入必须是某个固定的尺寸,因此哪些大小不一的region proposals必须先warp到fixed size。具体warp方法不展开讲了。
2.3 训练SVM分类器
同样需要形成一个训练集(X,Y),这次标准不一样,将IoU=1的认定为正样本(y=1),IoU<0.3的认定为负样本(y=0)。具体的,IoU是region proposal与ground truth的交并比,而训练集的X则是该region proposal经过CNN encode得到的特征向量。
2.4 过滤
使用非极大值抑制去除重复检测
3. 重要问题
为什么不直接用CNN模型进行分类,而要使用SVM呢?
为什么训练CNN和SVM时候,正负例判定标准IoU阈值设置不同呢?
答:这两个问题是相关的,我认为本质上是因为这是一个多阶段的模型,很多地方需要trade off,第一步生成的建议区域是正例少负例多,构建训练集的时候就容易不平衡,因此需要放宽正例的条件,但是要想定位准确,就需要正例更精准,这就是矛盾所在,因此有了不同的IoU阈值和引入SVM。具体的,由于算法最后给出的检测结果就是经过筛选的region proposal,那么肯定希望它跟ground truth更吻合,也就是IoU接近于1,那么自然的要把哪些容易产生干扰的样本剔除掉为好。但训练CNN需要大量样本,在当前任务下,负例多正例少,一次调高IoU阈值为0.5,增加正例数量,防止过拟合;而训练SVM需要样本数量少,因为IoU阈值设置严格,以提高定位准确率。
4. 缺陷
4.1 对每一个region proposal都要过一遍CNN,重复计算严重拖累的模型的效率
直观的想,解决这个问题就是要共享计算,也就是要先对图片进行一次整体卷积,然后在feature map上选取region proposal,但是这时的region proposal的尺寸又是大小不一的了,不满足全连接层的输入要求。。针对这个问题,提出了SPP-Net和Fast-RCNN,后面陆续展开讲。
4.2 通过selective search生成region proposals。
这部分是不能通过学习优化的,然后通过对这些分类代替回归定位,感觉潜力有限。是否回归生成region proposals更优,还不太确定,等读到后面的论文再说。
4.3 多阶段的模型,尤其是加入不能学习的算法,造成一种脱节感,限制了深度学习模型的威力。