南京代怀孕多少█ 微信号█:138-0226-9370██████代孕包成功电询顾问,代孕包男孩,供卵代孕,三代试管婴儿选性别,供卵试管婴儿,十年老品牌代孕公司,
re模块是操作正则表达式的模块

一,匹配单个字符
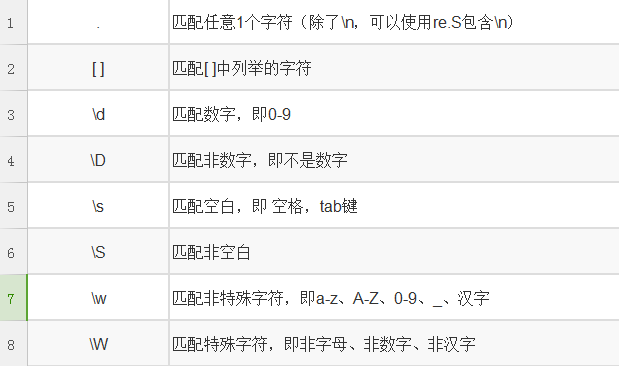
注意:
1, ' . '可以匹配除了 \n 的唯一字符,若想要匹配\n,可在正则表达式后加上re.S .
2, \w还可以匹配多种语言,所以需要慎用。
3, \s 可以匹配到 \n
4, []中匹配10个数字可用[0-9],26个字母可用[a-z]
5, []中匹配除了指定字符以外都匹配:[^abcde]
二,匹配多个字符

注意:此处可以体现出正则表达式的贪婪特性,在同等条件下,会自动使*、+、?、{1,5}匹配多的字符,取消贪婪特性可使用*?、 +?、 ??、 {}?
三,匹配开头和结尾、除了指定字符都匹配
1,匹配开头和结尾
在表达式中若有^代表匹配内容的首字符应该与正则表达式中的首字符匹配,否则无输出。
在表达式中若有$代表匹配内容的末字符应该与正则表达式中的末字符匹配,否则无输出。

2,除了指定字符都匹配
[^指定字符]: 表示除了指定字符都匹配
# [^>]*> 表示 只要不是 字符> 就可以匹配多个,直到遇到>
# | 在此处表示 并
re.sub(r'<[^>]*>|\s| ','',strs) # 表示将strs中在匹配到的字符替换成无,并输出替换后的strs
四,匹配分组
1,字符‘|’ 在此处表示 或 ,由括号()来限定或的范围
2,()中的字符作为分组,group(num)中的num指定取出哪个分组
3,\num 在正则表达式中引用分组num匹配到的字符
4,(?P<name>)分组起别名 (?P=name)引用别名为name分组匹配到的字符串

五,re模块的高级用法
1.search
与match的区别为:不从开头开始匹配,在文中寻找匹配项,只查找一次

2.findall
与search基本相同,但可以查找多次

3.sub 将匹配到的数据进行替换
1)使用字符串进行替换

2)使用函数进行替换

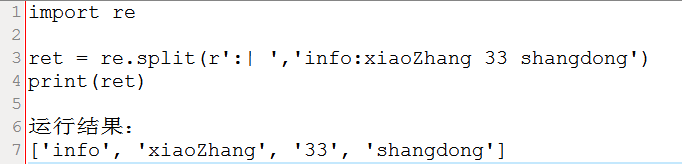
4.split
根据匹配进行切割字符串,并返回一个列表
# | 表示 并
六,贪婪与非贪婪
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。

正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串,在我们上面的例子里面,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。

解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,这样“?”前面的正则表达式不能匹配“?”后面正则表达式的数据
七,r的作用
Python中字符串前面加上 r 表示原生字符串,数据里面的反斜杠不需要进行转义,针对的只是反斜杠
Python里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
建议: 如果使用使用正则表达式匹配数据可以都加上r,要注意r针对的只是反斜杠起作用,不需要对其进行转义
match_obj = re.match(r"<([a-zA-Z1-6]+)>.*</\1>", "<html>hh</html>")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")- r 表示原生字符串,数据里面的反斜杠不需要进行转义,针对的只是反斜杠