给定三个输入图像:人穿着布A,独立布A和独立布B,条件类比GAN(CAGAN)生成穿着布B的人类图像。参见下图。
在我的实验中,CAGAN能够交换不同类别的衣服,例如长/短袖T恤(原始纸张中未显示)。换句话说,CAGAN不仅改变了衣服的颜色,而且还必须产生从长袖到短袖领域的人体部位。
预习:

CAGAN概述。

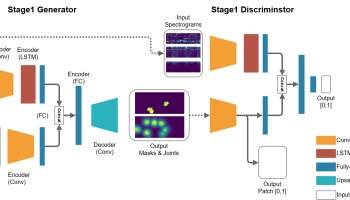
发电机G和鉴别器D的架构

结果比较:cycleGAN(左)和CAGAN(右)。
数据集:
图像是从zalora.com.tw抓取的。我们收集了大约2000个人/物对作为训练数据。
(*由于版权问题,此帖子中的某些图片会被插图替换或裁剪。)
组态
- 优化者:亚当
- 学习率:2e-4
- 批量大小:16(CAGAN)或8(CAGAN + StackGAN-v2)
- 数据增强:随机裁剪和翻转
GitHub回购。
可以在此处找到CAGAN的keras实现。
关于实施的说明:
- 在CAGAN论文中,关于实现细节的描述写道:“此外,我们总是使用任何中间层的最后6个通道(在G和D中)来存储输入的下采样副本
”。我不完全理解这意味着什么,所以我所做的就是来连接
和
每一个中间层。然而,当连接
I. CycleGAN是我们的第一次尝试
为什么选择CycleGAN?这是图像到图像生成的首选解决方案(个人)。已经在GitHub上实现了keras。
它有用吗?是的,但缺乏多样性和现实。
循环实现的CycleGAN是从这里借来的。
结果: 给定单独的物品图像作为输入,上图显示了在训练~10k次迭代后生成的人体图像。CycleGAN无法生成人脸,身体形状远非真实。底行还有模式折叠(类似的人体姿势)。
给定单独的物品图像作为输入,上图显示了在训练~10k次迭代后生成的人体图像。CycleGAN无法生成人脸,身体形状远非真实。底行还有模式折叠(类似的人体姿势)。
II。重新实现CAGAN
为何选择CAGAN?想要生成具有不同姿势的逼真人体图像。充分利用输入人类图像。
它有用吗?是。
概述:
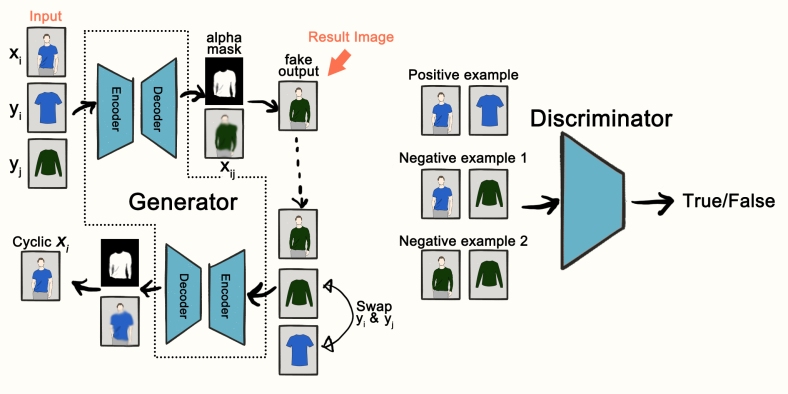
给出三个输入图像:

建筑:
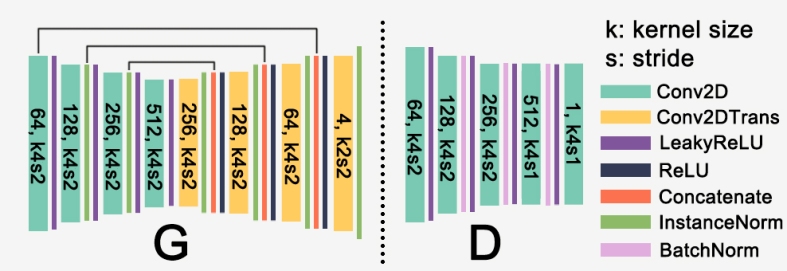
发电机G和鉴别器D的结构。
生成器是典型的UNET,它将早期层功能连接到后面的层。发生器的输出是包含四通道张量的![\ left [\ alpha,\ hat {x} {ij} ^ R,\ hat {x} {ij} ^ G,\ hat {x} _ {ij} ^ B \ right]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B%5Calpha+%2C+%5Chat%7Bx%7D%7Bij%7D%5ER%2C+%5Chat%7Bx%7D%7Bij%7D%5EG%2C+%5Chat%7Bx%7D_%7Bij%7D%5EB+%5Cright+%5D+&bg=ffffff&fg=555555&s=0)
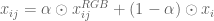
鉴别器由几层Conv2D组成,输出为8x8x1 sigmoid输出(输入大小128x96x3),即所谓的PatchGAN方法。
训练损失功能:
在CAGAN培训中,有3个应用损失:第一,对抗性损失
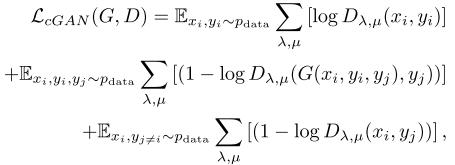 其中
其中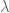


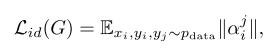 其中||
其中|| 
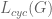
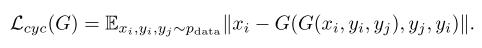
采摘樱桃的结果:
所以有什么问题?
当训练超过3000次更新时,生成的图像中存在重复的伪影,有时人脸会变形,如下所示:
这些伪影也可以在原始CAGAN论文的图6(c)和(d)中找到。
我认为这是由小编码器输出大小(输入大小的1 / 16x)引起的,因此在超分辨率相关任务中使用的架构和方法可能会有所帮助,这将导致下一节。
III。CAGAN + StackGAN-v2
为什么将CAGAN与StackGan-v2结合使用?想要生成高质量的纹理/图形,并稳定培训。
它有用吗?有点,它更经常地产生成功的结果。而且它的训练更稳定。
训练期间使用的任何技巧?
1.将高斯噪声添加到鉴别器输入。
2. 在鉴别器输入上使用混合技术。
3.将Conv2D内核大小更改为(4,3)。
4.为生成器损失添加标识丢失。见下面的[实验注释] 2。
5.尺寸64×48循环输出合并为
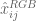
6.连接![[x_i,y_j]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+y_j%5D&bg=ffffff&fg=555555&s=0)
![[x_i,y_i]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+y_i%5D&bg=ffffff&fg=555555&s=0)
架构:上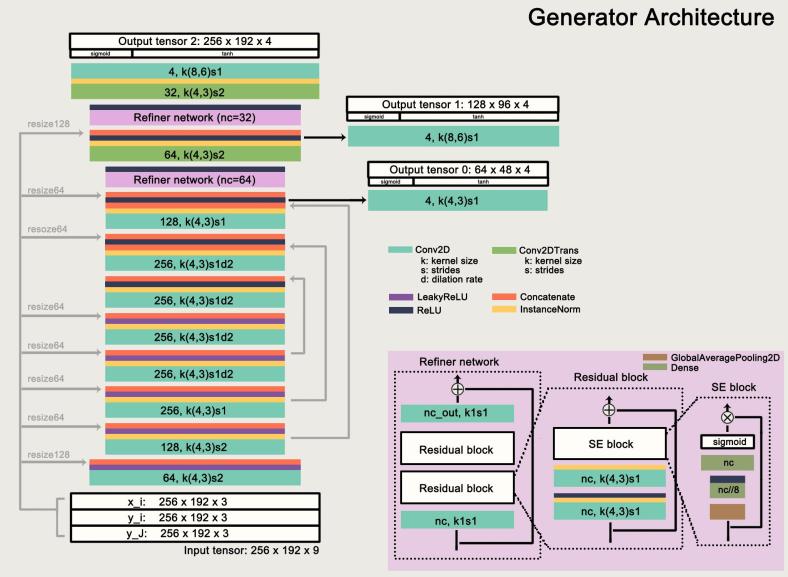 图详细显示了模型架构。该模型将三个图像作为输入,并在其末端生成三个不同大小的人类图像(带有alpha蒙版)。我们对CAGAN架构进行了一些修改:首先,受到本文处理图像完成的启发,我们用扩展的Conc2D层替换了部分stride 2 Conv2D层,使得特征映射分辨率减半。这可以防止输出图像丢失细节。其次,在解码器(-ish)部分中引入了精炼网络。精炼网络由两堆残余块组成,它学习添加细节以及提高输出图像的真实感。此外,我们应用挤压和激励模块 在剩余的块之上(希望学会)增加对信息功能的敏感性。
图详细显示了模型架构。该模型将三个图像作为输入,并在其末端生成三个不同大小的人类图像(带有alpha蒙版)。我们对CAGAN架构进行了一些修改:首先,受到本文处理图像完成的启发,我们用扩展的Conc2D层替换了部分stride 2 Conv2D层,使得特征映射分辨率减半。这可以防止输出图像丢失细节。其次,在解码器(-ish)部分中引入了精炼网络。精炼网络由两堆残余块组成,它学习添加细节以及提高输出图像的真实感。此外,我们应用挤压和激励模块 在剩余的块之上(希望学会)增加对信息功能的敏感性。
我们模型的另一个主干是StackGAN-v2(StackGAN ++)。StackGan-v2由树状结构中的多个生成器和鉴别器组成。在我们的模型中,我们使用不同比例的三级发生器:256 x 192,128 x 96和64 x 48,而最深的发生器生成最终输出图像。StackGAN架构有助于稳定训练并改善输出颜色的真实感(例如,肤色)。
请注意,我们的前馈输入图像
(鉴别器具有与CAGAN相同的结构。故意保持简单。)
训练损失函数:
除了在CAGAN中使用的损失函数之外,我们还引入了两个损失函数:身份丢失


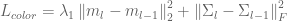
![x_ {ident} = G([x_i,y_i,y_i]),](https://s0.wp.com/latex.php?latex=x_%7Bident%7D%3DG%28%5Bx_i%2C+y_i%2C+y_i%5D%29%2C&bg=ffffff&fg=555555&s=0)
其中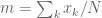
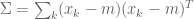
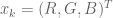
身份损失鼓励模型专注于
采摘樱桃的结果:
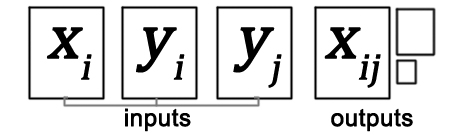
输入图像显示为前三个图像。跟随右侧相应生成的人体图像。(输入图像被插图替换)
内部类
长袖到短袖


上图显示了每个阶段输出图像的细化:上图显示了肤色的细化,下图显示了图形颜色的细化。
图像


我们的模型能够生成比原始CAGAN更清晰的目标文章图形。
其他

我们可以从结果图像中看出,没有生成重复的伪像。(虽然没有显示,但在我们的模型中,人脸上的文物也减少了。)
好的,现在怎么样?
总的来说,我对结果很满意,因为我们的模型只训练了大约2000个图像对(<1 / 7x的CAGAN)。但它在提高模型复杂度,换句话说,更长的训练时间的权衡中产生了更高质量的图像。更重要的是,生成的图像仍然远非完美。例如,我们的模型无法了解穿布的变形(单独布料)。大多数交换结果看起来就像是通过一些改进将目标衣服复制粘贴到人体图像上。因此,图形的位置通常是偏离位置的。我们尝试了空间变换器层(使用薄平面样条变换),但遗憾的是未能获得良好的结果。无论如何,我们可以想到很多叛逃:生硬的边缘,低成功率,不知道颈线等。
此外,我们没有进行任何定量评估。我们只通过观察其视觉质量来判断性能。在这里,我想引用Generative Adversarial Networks:An Overview(作为我缺乏GAN知识的借口):“如何衡量由生成模型合成的样本的优良性?我们应该使用可能性估计吗?使用一种方法训练的GAN能否与另一种方法进行比较(模型比较)?这些是开放式问题,不仅与GAN有关,而且与概率模型有关。
我从实施CAGAN中学到了什么:
- 理解某些架构背后的概念比架构本身更重要。
- 在调整超参数(如内核大小和损失函数的加权因子)上花费太多时间是不明智的,因为它总是导致微不足道的改进。
- 直觉从未在神经网络上工作过。我认为会改善结果的是99%的失败。
- 为每个图层指定一个正确的名称,以便我可以按Ctrl + F在model.summary()中搜索它们。
- 进行单元测试,检查迭代后是否更新了权重。
2017年11月25日更新:来自UMD(拉里戴维斯实验室)的
一篇名为“VITON:基于图像的虚拟试穿网络 ” 的新论文 在布料交换方面给出了令人印象深刻的结果,基本上让这个帖子毫无价值LOL。我相信本文中的TPS变换部分可以被空间变换器网络所取代。
2018年2月18日更新:
基于服装区域的基于生成对抗网络的虚拟尝试:基于CAGAN的ICLR研讨会论文,其中引入了人类解析网络来分割服装区域。即,alpha掩码不再由生成器生成,而是由预先训练的网络生成。
更新
时间:2018年11月20日:SwapNet:单一视图中的服装转移图像:一篇ECCV2018论文,其中作者提出了一个框架,“将服装转移到具有任意身体姿势,形状和衣服的人的图像上”。网络利用姿势和布料分割作为先验信息。它还使用变形(如在VITON中)来改善生成的衣服的纹理细节。
[实验注释]
1.替换Con2DTranspose与最近邻上采样没有给出更好的结果图像,因为循环
2.添加身份丢失减少了棋盘格工件,并使网络从模式崩溃中稳定下来。身份损失是L1损失,定义为:
![idt = G([x_i,y_i,y_i])](https://s0.wp.com/latex.php?latex=idt%3DG%28%5Bx_i%2C+y_i%2C+y_i%5D%29&bg=ffffff&fg=555555&s=0)
3。 感知损失(我的实验中的MobileNet)也没有帮助。也许是因为循环损失对结果图像没有太大影响。循环损耗加权因子在循环GAN(tjwei的keras实现)中
4. StackGAN-v2架构可能有所帮助。仍在实验中(调整超参数)。到目前为止只与原来的CAGAN得到了类似的结果。完成。
5.在L a b色彩空间中对图像进行训练的模型在白色物品上表现不佳。
6.使用最小平方损失时没有收敛。
7.将输入[ 
8.使用扩张卷积可以改善纹理(例如,T恤上的图形)质量。
9。 添加辅助本地上下文鉴别器(受本文启发)没有找到一个好的方法将其插入CAGANs。
10.在发生器中使用更多膨胀的Conv2D和更少的stride2 Conv2D层(9的相同纸张)。
11.在StackGAN-v2架构中使用循环丢失是一个类似于XGAN中语义一致性丢失的概念(最近发表的来自Google脑的论文):它们都使用中间层的特征距离作为损失以鼓励内容一致性。
12.如果WGAN-GP能带来更好的结果,我一直想知道。通过略读之后本文是提供有关超分辨率任务GAN和WGAN(-GP)之间的比较,我决定推迟实验WGAN。
广告
广告
举报此广告
举报此广告
有关
在“keras”中
在“未分类”中

在Floybhub上使用Mask-RCNN和SSD进行车辆检测:Udacity自动驾驶汽车纳米度
在“floydhub”中
分类:keras
邮政导航
←用Swish,ReLU和SELU进行实验(在neptune.ml上)
2个想法“ 布与深学习交换:实施Keras有条件类比GAN ”
-
Xintong Han 说:
嗨,我是Xintong Han。在使用VITON纸张时,我尝试过空间变压器网络(至少两周)。即使将基础事实TPS参数作为监督的一部分,STN也很难收敛,这使得很难超越形状上下文匹配。如果你在这个场景中让STN工作取得任何进展,我很高兴听到这个。
喜欢
-
少安路 说:
嗨,Xintong。我在CAGAN上尝试了STN,但也没有找到成功的结果。
关于以监督方式训练STN,你的意思是给出两个二元掩模作为输入:布掩码M和蒙面目标服装C(类似于VITON论文中引用的WarpNet),STN不能很好地学习TPS参数?
-