Spark SQL是用于结构化数据处理的Spark模块,可以通过sql、dataset、dataframe与spark sql进行交互。更多理论性知识请移步官网http://spark.apache.org/docs/2.3.1/sql-programming-guide.html
在spark 2.0以前,多使用SqlContext进行开发,2.0以后,推荐使用SparkSession,本文将以SqlContext写一个简单的例子,在后面的博文中,会写spark session相关的博文,并会详细说明二者之间的差别。
接着上一篇的工程,继续开发学习。
1.准备
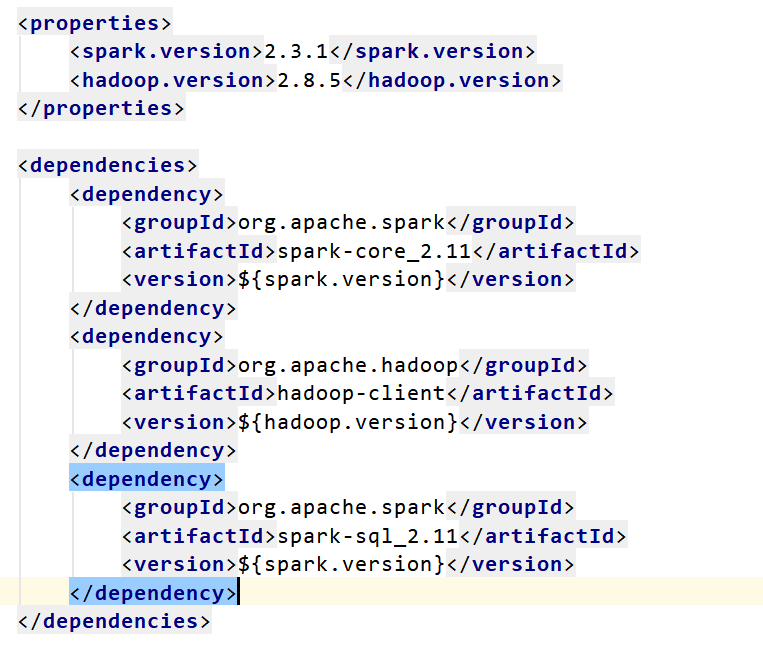
1.1添加maven依赖
在pom文件中添加如下依赖:
1.2准备数据
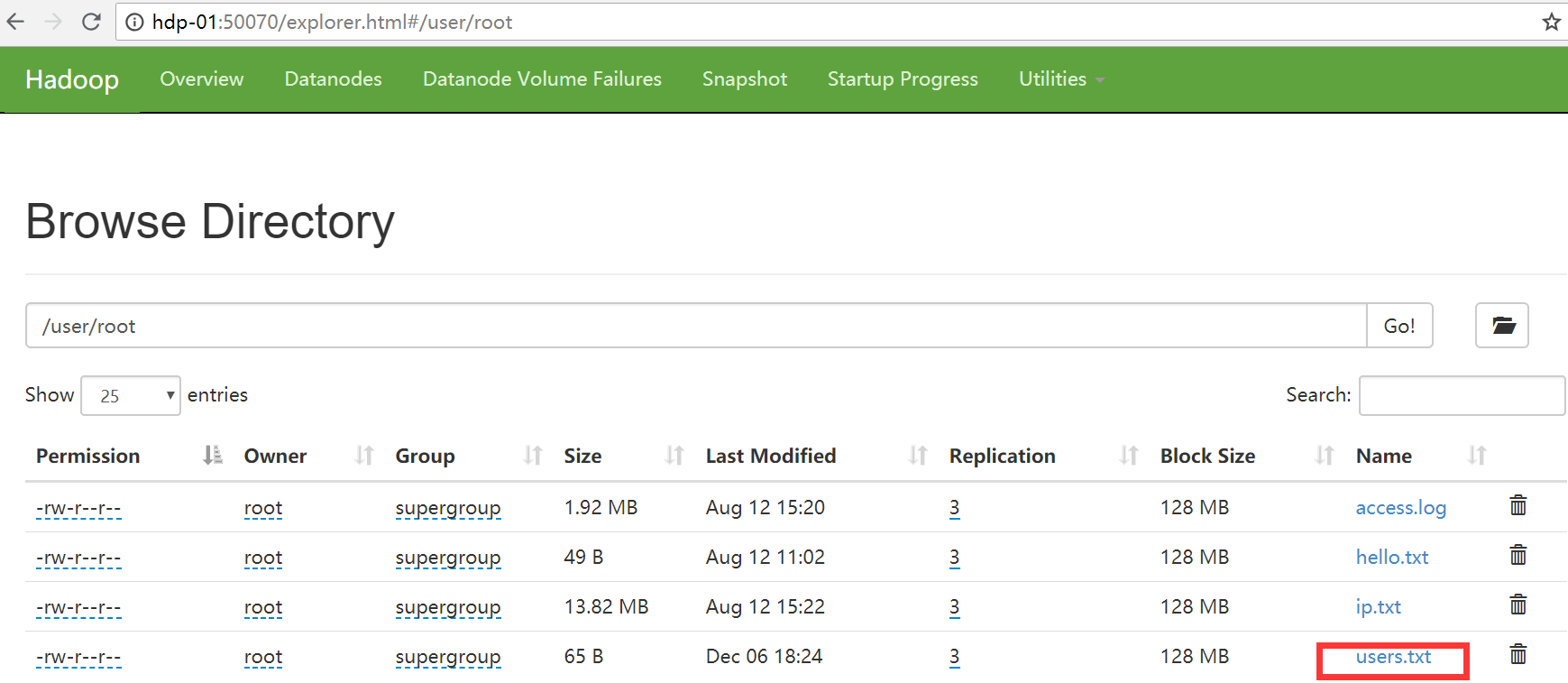
新建一个txt文件,加入以下数据

如果有hdfs集群,可以将数据push到hdfs集群
2.编码
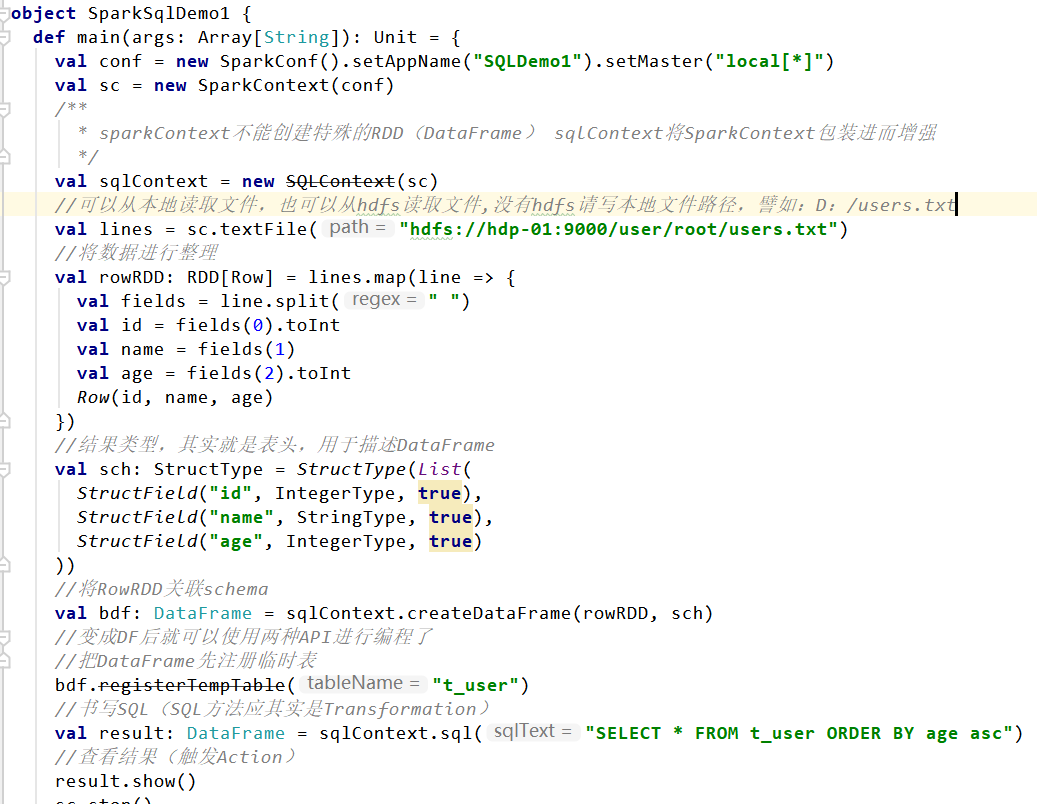
新建scala object SparkSqlDemo1,加入如下代码:
运行结果:

完整代码已上传至github https://github.com/wuyueming985/sparkdemos
感谢阅读!