注:笔者环境 hdp2.5 + linux + spark1.6.3
一. Spark SQL简介
- Spark SQL是一个用来处理结构化数据的Spark组件。
可被视为一个分布式的SQL查询引擎,并且提供了一个叫做DataFrame的可编程抽象数据模型。
Spark SQL可以直接处理RDD,也可以处理Parquet文件或者JSON文件,甚至可以处理外部数据库(关系型数据库一样支持)中的数据以及Hive中存在的表
二、DataFrame简介
- DataFrame是Spark SQL提供的最核心的编程抽象
- DataFrame是一个分布式的Row对象的数据集合
- DataFrame实现了RDD的绝大多数功能
DataFrame的创建方式
- 结构化数据文件创建DataFrame
- 外部数据库创建DataFrame
- RDD创建DataFrame
- Hive中的表创建DataFrame
三、通过Hive 中的表创建DataFrame,并简单测试DataFrame常用的方法
- 通过Hive中的表创建DataFrame,可以声明一个HiveContext对象
使用HiveContext对象查询Hive中的表并转成DataFrame,也可以直接使用sqlContext
- 通过spark-sql查看hive中的表数据情况
- 进入spark-sql
[root@dn02 bin]# spark-sql
> show tables;
tbl_org false
test11 false
> select * from test;
1 hehe 中国
2 haha 克罗地亚
3 heihei 美国
Time taken: 0.605 seconds, Fetched 3 row(s)进入spark-shell
在 spark-shell 启动的过程中会初始化 SQLContext 对象为 sqlContext,此时初始化的 sqlContext 对象既支持 SQL 语法解析器,也支持 HiveQL 语法解析器。也就是使用这个 sqlContext 可以执行 SQL 语句和 HQL 语句。DataFrame可以用saveAsTable方法,将数据保存成持久化的表。
读取持久化表时,只需要用表名作为参数,调用SQLContext.table方法即可得到对应DataFrame。
所以对于已经存在的hive表只需要调用如下方法便可得到其对应的dataFrame通过Hive创建DataFrame方式一:
scala> val test1 = sqlContext.table("default.test")
test1: org.apache.spark.sql.DataFrame = [id: string, name: string, address: string]注:可通过test1调用queryExecution查看生成test1的执行过程
- 通过Hive创建DataFrame方式二:
scala> val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc);
scala> val test = hiveContext.sql("select * from test")
18/08/06 17:40:27 INFO ParseDriver: Parsing command: select * from test
18/08/06 17:40:27 INFO ParseDriver: Parse Completed
test: org.apache.spark.sql.DataFrame = [id: string, name: string, address: string]DataFrame查看数据常用的方法
样例如下:
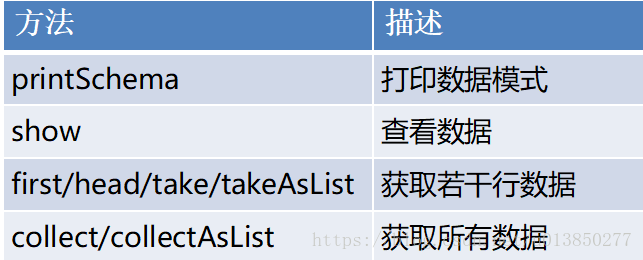
scala> test.printSchema
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- address: string (nullable = true)
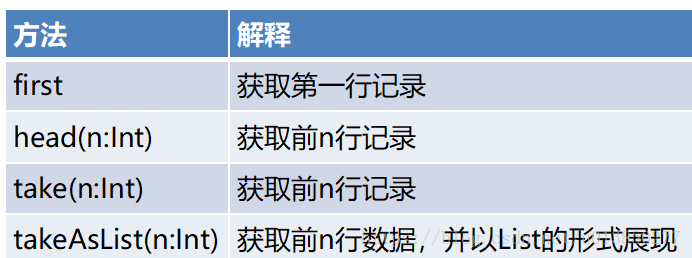
scala> test.first
res14: org.apache.spark.sql.Row = [1,hehe,中国]
scala> test.show(2)
+---+----+-------+
| id|name|address|
+---+----+-------+
| 1|hehe| 中国|
| 2|haha| 克罗地亚|
+---+----+-------+
only showing top 2 rows
show():默认显示前20行
show(numRows:Int) : 显示numRows行
scala> test.take(11)
res16: Array[org.apache.spark.sql.Row] = Array([1,hehe,中国], [2,haha,克罗地亚], [3,heihei,美国])
scala> test.collect
res17: Array[org.apache.spark.sql.Row] = Array([1,hehe,中国], [2,haha,克罗地亚], [3,heihei,美国])
scala> test.collectAsList
res18: java.util.List[org.apache.spark.sql.Row] = [[1,hehe,中国], [2,haha,克罗地亚], [3,heihei,美国]]- DataFrame查询数据的方法
样例:
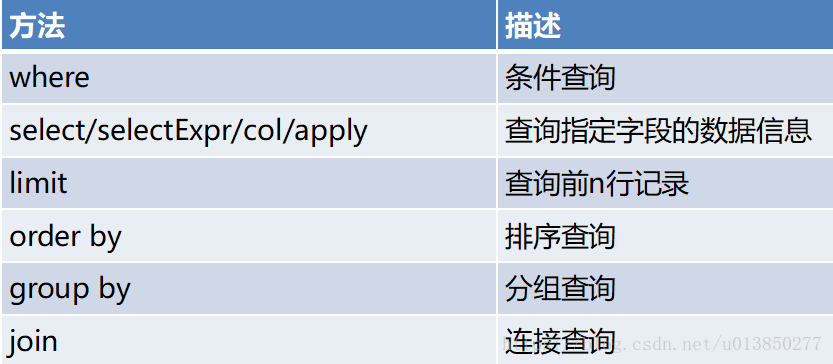
1、scala> val useWhere = test.where("name='hehe' and id='1'").show;
18/08/06 17:58:47 INFO MemoryStore: Block broadcast_9 stored as values in memory (estimated size 732.0 KB, free 1531.1 KB)
18/08/06 17:58:47 INFO MemoryStore: Block broadcast_9_piece0 stored as bytes in memory (estimated size 51.4 KB, free 1582.5 KB)
18/08/06 17:58:47 INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on localhost:50334 (size: 51.4 KB, free: 511.0 MB)
18/08/06 17:58:47 INFO SparkContext: Created broadcast 9 from show at <console>:31
18/08/06 17:58:47 INFO PerfLogger: <PERFLOG method=OrcGetSplits from=org.apache.hadoop.hive.ql.io.orc.ReaderImpl>
18/08/06 17:58:47 INFO OrcInputFormat: FooterCacheHitRatio: 0/0
18/08/06 17:58:47 INFO PerfLogger: </PERFLOG method=OrcGetSplits start=1533549527986 end=1533549527991 duration=5 from=org.apache.hadoop.hive.ql.io.orc.ReaderImpl>
18/08/06 17:58:47 INFO SparkContext: Starting job: show at <console>:31
18/08/06 17:58:47 INFO DAGScheduler: Got job 6 (show at <console>:31) with 1 output partitions
18/08/06 17:58:47 INFO DAGScheduler: Final stage: ResultStage 6 (show at <console>:31)
18/08/06 17:58:47 INFO DAGScheduler: Parents of final stage: List()
18/08/06 17:58:47 INFO DAGScheduler: Missing parents: List()
18/08/06 17:58:47 INFO DAGScheduler: Submitting ResultStage 6 (MapPartitionsRDD[23] at show at <console>:31), which has no missing parents
18/08/06 17:58:47 INFO MemoryStore: Block broadcast_10 stored as values in memory (estimated size 10.5 KB, free 1593.0 KB)
18/08/06 17:58:48 INFO MemoryStore: Block broadcast_10_piece0 stored as bytes in memory (estimated size 5.5 KB, free 1598.5 KB)
18/08/06 17:58:48 INFO BlockManagerInfo: Added broadcast_10_piece0 in memory on localhost:50334 (size: 5.5 KB, free: 511.0 MB)
18/08/06 17:58:48 INFO SparkContext: Created broadcast 10 from broadcast at DAGScheduler.scala:1008
18/08/06 17:58:48 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 6 (MapPartitionsRDD[23] at show at <console>:31)
18/08/06 17:58:48 INFO TaskSchedulerImpl: Adding task set 6.0 with 1 tasks
18/08/06 17:58:48 INFO TaskSetManager: Starting task 0.0 in stage 6.0 (TID 6, localhost, partition 0,ANY, 2185 bytes)
18/08/06 17:58:48 INFO Executor: Running task 0.0 in stage 6.0 (TID 6)
18/08/06 17:58:48 INFO HadoopRDD: Input split: hdfs://nn01.bmsoft.com.cn:8020/apps/hive/warehouse/test/000000_0:0+464
18/08/06 17:58:48 INFO OrcRawRecordMerger: min key = null, max key = null
18/08/06 17:58:48 INFO ReaderImpl: Reading ORC rows from hdfs://nn01.bmsoft.com.cn:8020/apps/hive/warehouse/test/000000_0 with {include: [true, true, true, true], offset: 0, length: 9223372036854775807}
18/08/06 17:58:48 INFO GeneratePredicate: Code generated in 11.044052 ms
18/08/06 17:58:48 INFO Executor: Finished task 0.0 in stage 6.0 (TID 6). 2646 bytes result sent to driver
18/08/06 17:58:48 INFO TaskSetManager: Finished task 0.0 in stage 6.0 (TID 6) in 28 ms on localhost (1/1)
18/08/06 17:58:48 INFO TaskSchedulerImpl: Removed TaskSet 6.0, whose tasks have all completed, from pool
18/08/06 17:58:48 INFO DAGScheduler: ResultStage 6 (show at <console>:31) finished in 0.027 s
18/08/06 17:58:48 INFO DAGScheduler: Job 6 finished: show at <console>:31, took 0.038651 s
+---+----+-------+
| id|name|address|
+---+----+-------+
| 1|hehe| 中国|
+---+----+-------+
useWhere: Unit = ()
scala> 注:where方法的返回结果仍然为DataFrame类型,filter与where的使用方法一样
2、select方法根据传入的string类型字段名,获取指定字段的值,以DataFrame类型返回
scala> val selectTest = test.select("id","name")
selectTest: org.apache.spark.sql.DataFrame = [id: string, name: string]
scala> selectTest.show
18/08/06 18:04:39 INFO MemoryStore: Block broadcast_11 stored as values in memory (estimated size 732.0 KB, free 2.3 MB)
18/08/06 18:04:39 INFO MemoryStore: Block broadcast_11_piece0 stored as bytes in memory (estimated size 51.4 KB, free 2.3 MB)
18/08/06 18:04:39 INFO BlockManagerInfo: Added broadcast_11_piece0 in memory on localhost:50334 (size: 51.4 KB, free: 511.0 MB)
18/08/06 18:04:39 INFO SparkContext: Created broadcast 11 from show at <console>:34
18/08/06 18:04:39 INFO PerfLogger: <PERFLOG method=OrcGetSplits from=org.apache.hadoop.hive.ql.io.orc.ReaderImpl>
18/08/06 18:04:39 INFO OrcInputFormat: FooterCacheHitRatio: 0/0
18/08/06 18:04:39 INFO PerfLogger: </PERFLOG method=OrcGetSplits start=1533549879820 end=1533549879825 duration=5 from=org.apache.hadoop.hive.ql.io.orc.ReaderImpl>
18/08/06 18:04:39 INFO SparkContext: Starting job: show at <console>:34
18/08/06 18:04:39 INFO DAGScheduler: Got job 7 (show at <console>:34) with 1 output partitions
18/08/06 18:04:39 INFO DAGScheduler: Final stage: ResultStage 7 (show at <console>:34)
18/08/06 18:04:39 INFO DAGScheduler: Parents of final stage: List()
18/08/06 18:04:39 INFO DAGScheduler: Missing parents: List()
18/08/06 18:04:39 INFO DAGScheduler: Submitting ResultStage 7 (MapPartitionsRDD[27] at show at <console>:34), which has no missing parents
18/08/06 18:04:39 INFO MemoryStore: Block broadcast_12 stored as values in memory (estimated size 6.0 KB, free 2.3 MB)
18/08/06 18:04:39 INFO MemoryStore: Block broadcast_12_piece0 stored as bytes in memory (estimated size 3.4 KB, free 2.3 MB)
18/08/06 18:04:39 INFO BlockManagerInfo: Added broadcast_12_piece0 in memory on localhost:50334 (size: 3.4 KB, free: 511.0 MB)
18/08/06 18:04:39 INFO SparkContext: Created broadcast 12 from broadcast at DAGScheduler.scala:1008
18/08/06 18:04:39 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 7 (MapPartitionsRDD[27] at show at <console>:34)
18/08/06 18:04:39 INFO TaskSchedulerImpl: Adding task set 7.0 with 1 tasks
18/08/06 18:04:39 INFO TaskSetManager: Starting task 0.0 in stage 7.0 (TID 7, localhost, partition 0,ANY, 2185 bytes)
18/08/06 18:04:39 INFO Executor: Running task 0.0 in stage 7.0 (TID 7)
18/08/06 18:04:39 INFO HadoopRDD: Input split: hdfs://nn01.bmsoft.com.cn:8020/apps/hive/warehouse/test/000000_0:0+464
18/08/06 18:04:39 INFO OrcRawRecordMerger: min key = null, max key = null
18/08/06 18:04:39 INFO ReaderImpl: Reading ORC rows from hdfs://nn01.bmsoft.com.cn:8020/apps/hive/warehouse/test/000000_0 with {include: [true, true, true, false], offset: 0, length: 9223372036854775807}
18/08/06 18:04:39 INFO Executor: Finished task 0.0 in stage 7.0 (TID 7). 2509 bytes result sent to driver
18/08/06 18:04:39 INFO TaskSetManager: Finished task 0.0 in stage 7.0 (TID 7) in 12 ms on localhost (1/1)
18/08/06 18:04:39 INFO DAGScheduler: ResultStage 7 (show at <console>:34) finished in 0.012 s
18/08/06 18:04:39 INFO TaskSchedulerImpl: Removed TaskSet 7.0, whose tasks have all completed, from pool
18/08/06 18:04:39 INFO DAGScheduler: Job 7 finished: show at <console>:34, took 0.017551 s
+---+------+
| id| name|
+---+------+
| 1| hehe|
| 2| haha|
| 3|heihei|
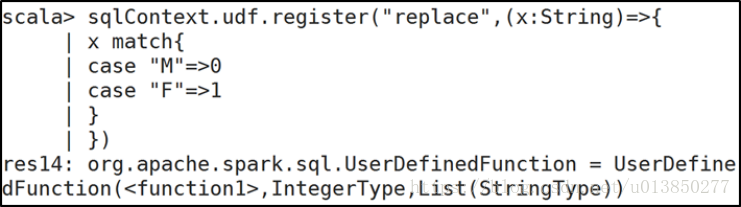
+---+------+- 3、selectExpr:对指定字段进行特殊处理
可以对指定字段调用UDF函数或者指定别名
selectExpr传入string类型的参数,返回DataFrame对象。
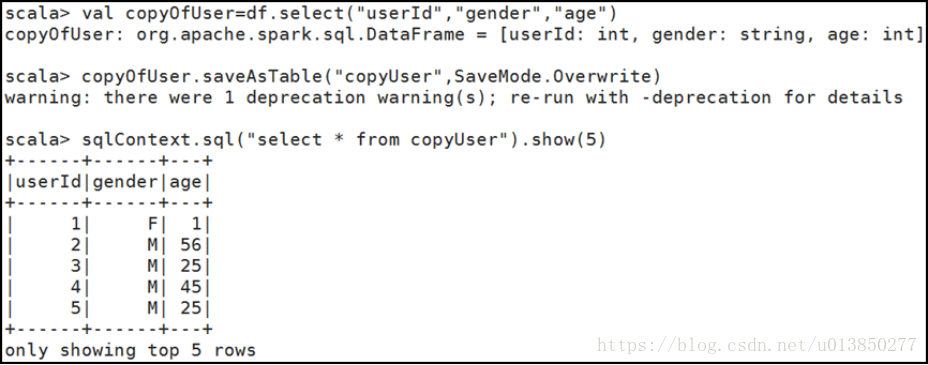
4、使用saveAsTable将DataFrame对象copyOfUser保存在表名为copyUser的表中。
mode函数可以接收的参数有Overwrite、Append、Ignore和ErrorIfExists。
Overwrite代表覆盖目录下之前存在的数据
Append代表给指导目录下追加数据
Ignore代表如果目录下已经有文件,那就什么都不执行
ErrorIfExists代表如果保存目录下存在文件小结:笔者觉得运用sqlContext.sql(“sql语句”)的方式会更加方便,这个sql语句可以包括where 、join、order by 、group by 等。

三、同样spark sql 支持将其他结构化数据转化成df
- 1、加载结构化数据
scala> val path = "/tmp/people.json" // hdfs目录
path: String = /tmp/people.json
scala> val peopleDS = sqlContext.read.json(path)
scala> peopleDS1.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+- 附文件内容:
[root@dn02 ~]# hdfs dfs -cat /tmp/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}