转:https://www.cnblogs.com/Determined22/p/6915730.html
本文简单整理了以下内容:
(一)马尔可夫随机场(Markov random field,无向图模型)简单回顾
(二)条件随机场(Conditional random field,CRF)
这篇写的非常浅,基于 [1] 和 [5] 梳理。感觉 [1] 的讲解很适合完全不知道什么是CRF的人来入门。如果有需要深入理解CRF的需求的话,还是应该仔细读一下几个英文的tutorial,比如 [4] 。
(一)马尔可夫随机场简单回顾
概率图模型(Probabilistic graphical model,PGM)是由图表示的概率分布。概率无向图模型(Probabilistic undirected graphical model)又称马尔可夫随机场(Markov random field),表示一个联合概率分布,其标准定义为:
设有联合概率分布 P(V) 由无向图 G=(V, E) 表示,图 G 中的节点表示随机变量,边表示随机变量间的依赖关系。如果联合概率分布 P(V) 满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型或马尔可夫随机场。
设有一组随机变量 Y ,其联合分布为 P(Y) 由无向图 G=(V, E) 表示。图 G 的一个节点 v∈Vv∈V 表示一个随机变量 YvYv ,一条边 e∈Ee∈E 就表示两个随机变量间的依赖关系。
1. 成对马尔可夫性(pairwise Markov property)
设无向图 G 中的任意两个没有边连接的节点 u 、v ,其他所有节点为 O ,成对马尔可夫性指:给定 YOYO 的条件下,YuYu 和 YvYv 条件独立

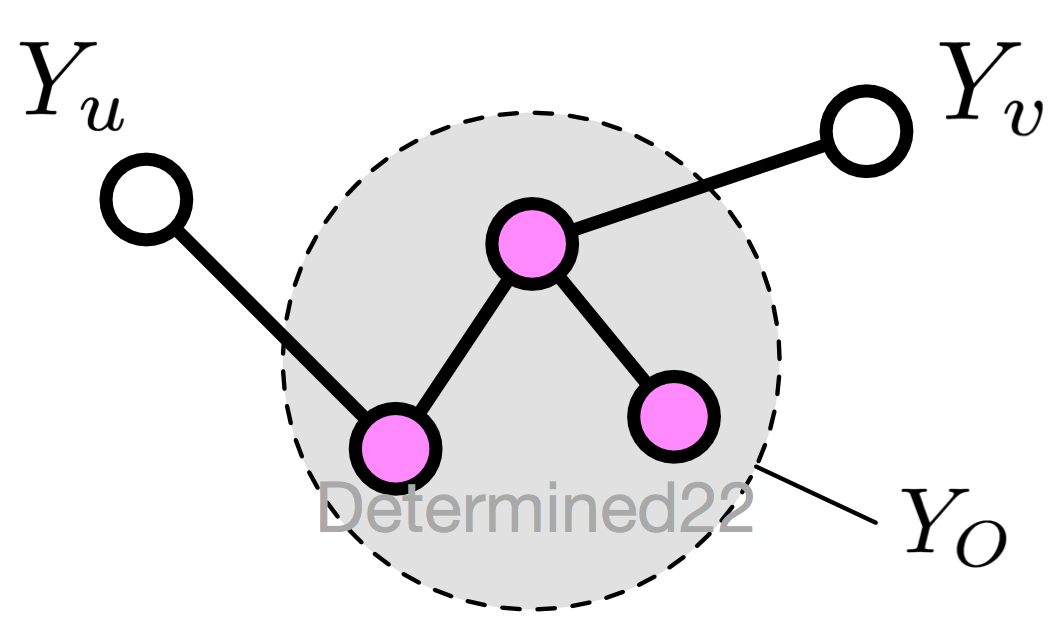
P(Yu,Yv|YO)=P(Yu|YO)P(Yv|YO)P(Yu,Yv|YO)=P(Yu|YO)P(Yv|YO)
2. 局部马尔可夫性(local)
设无向图 G 的任一节点 v ,W 是与 v 有边相连的所有节点,O 是 v 、W 外的其他所有节点,局部马尔可夫性指:给定 YWYW 的条件下,YvYv 和 YOYO 条件独立
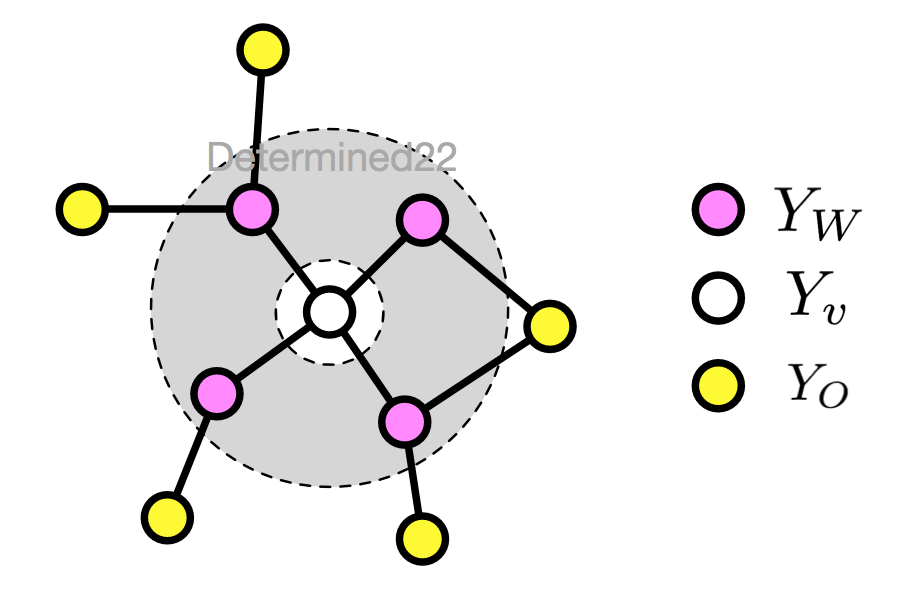
P(Yv,YO|YW)=P(Yv|YW)P(YO|YW)P(Yv,YO|YW)=P(Yv|YW)P(YO|YW)
当 P(YO|YW)>0P(YO|YW)>0 时,等价于
P(Yv|YW)=P(Yv|YW,YO)P(Yv|YW)=P(Yv|YW,YO)
如果把等式两边的条件里的 YWYW 遮住,P(Yv)=P(Yv|YO)P(Yv)=P(Yv|YO) 这个式子表示 YvYv 和 YOYO 独立,进而可以理解这个等式为给定条件 YWYW 下的独立。
3. 全局马尔可夫性(global)
设节点集合 A 、B 是在无向图 G 中被节点集合 C 分开的任意节点集合,全局马尔可夫性指:给定 YCYC 的条件下,YAYA 和 YBYB 条件独立
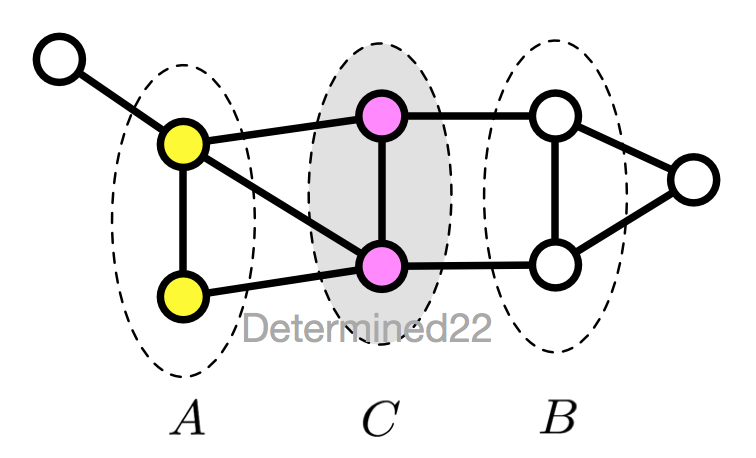
P(YA,YB|YC)=P(YA|YC)P(YB|YC)P(YA,YB|YC)=P(YA|YC)P(YB|YC)
这几个定义是等价的。
4. 概率无向图模型
无向图模型的优点在于其没有隐马尔可夫模型那样严格的独立性假设,同时克服了最大熵马尔可夫模型等判别式模型的标记偏置问题。
(1)有向图的联合概率分布
考虑一个有向图 Gd=(Vd,Ed)Gd=(Vd,Ed) ,随机变量间的联合概率分布可以利用条件概率来表示为
P(vd1,...,vdn)=∏i=1nP(vdi|vdπi)P(v1d,...,vnd)=∏i=1nP(vid|vπid)
其中 vdπivπid 表示节点 vdivid 的父节点的集合。
(2)无向图的因子分解(Factorization)
不同于有向图模型,无向图模型的无向性很难确保每个节点在给定它的邻节点的条件下的条件概率和以图中其他节点为条件的条件概率一致。由于这个原因,无向图模型的联合概率并不是用条件概率参数化表示的,而是定义为由一组条件独立的局部函数的乘积形式。因子分解就是说将无向图所描述的联合概率分布表达为若干个子联合概率的乘积,从而便于模型的学习和计算。
实现这个分解要求的方法就是使得每个局部函数所作用的那部分节点可以在 G 中形成一个最大团(maximal clique)。这就确保了没有一个局部函数是作用在任何一对没有边直接连接的节点上的;反过来说,如果两个节点同时出现在一个团中,则在这两个节点所在的团上定义一个局部函数来建立这样的依赖。
无向图模型最大的特点就是易于因子分解,标准定义为:
将无向图模型的联合概率分布表示为其最大团(maximal clique,可能不唯一)上的随机变量的函数的乘积形式。
给定无向图 G ,其最大团为 C ,那么联合概率分布 P(Y) 可以写作图中所有最大团 C 上的势函数(potential function) ψC(YC)ψC(YC) 的乘积形式:
P(Y)=1Z∏CψC(YC)P(Y)=1Z∏CψC(YC)
Z=∑Y∏CψC(YC)Z=∑Y∏CψC(YC)
其中 Z 称为规范化因子,对 Y 的所有可能取值求和,从而保证了 P(Y) 是一个概率分布。要求势函数严格正,通常定义为指数函数
ψC(YC)=exp(−E[YC])ψC(YC)=exp(−E[YC])
上面的因子分解过程就是 Hammersley-Clifford 定理。
(二)条件随机场
条件随机场(Conditional random field,CRF)是条件概率分布模型 P(Y|X) ,表示的是给定一组输入随机变量 X 的条件下另一组输出随机变量 Y 的马尔可夫随机场,也就是说 CRF 的特点是假设输出随机变量构成马尔可夫随机场。
条件随机场可被看作是最大熵马尔可夫模型在标注问题上的推广。
这里介绍的是用于序列标注问题的线性链条件随机场(linear chain conditional CRF),是由输入序列来预测输出序列的判别式模型。
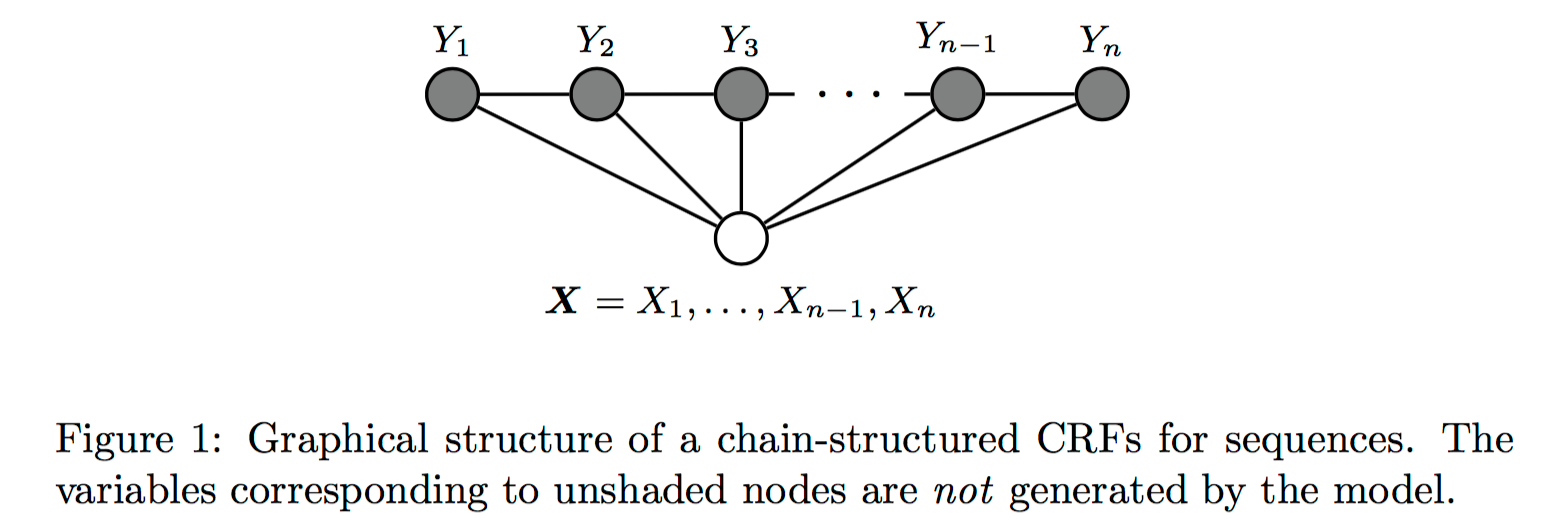
图片来源:[3]
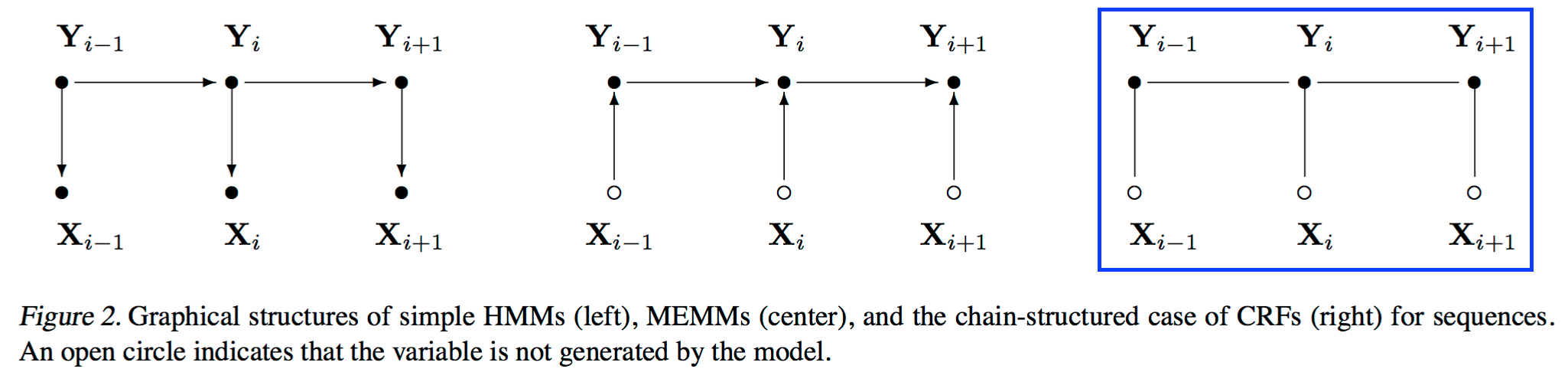
图片来源:[2]
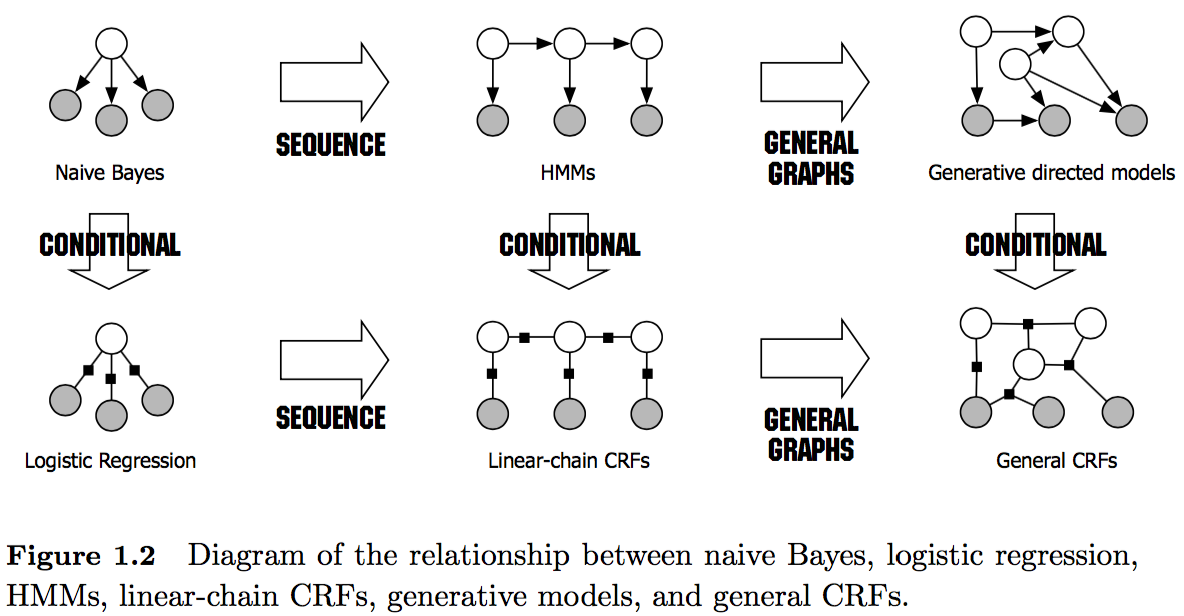
图片来源:[4]
从问题描述上看,对于序列标注问题,X 是需要标注的观测序列,Y 是标记序列(状态序列)。在学习过程时,通过 MLE 或带正则的 MLE 来训练出模型参数;在测试过程,对于给定的观测序列,模型需要求出条件概率最大的输出序列。
如果随机变量 Y 构成一个由无向图 G=(V, E) 表示的马尔可夫随机场,对任意节点 v∈Vv∈V 都成立,即
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w∼v)P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w∼v)
对任意节点 vv 都成立,则称 P(Y|X) 是条件随机场。式中 w≠vw≠v 表示 w 是除 v 以外的所有节点,w∼vw∼v 表示 w 是与 v 相连接的所有节点。不妨把等式两遍的相同的条件 X 都遮住,那么式子可以用下图示意:
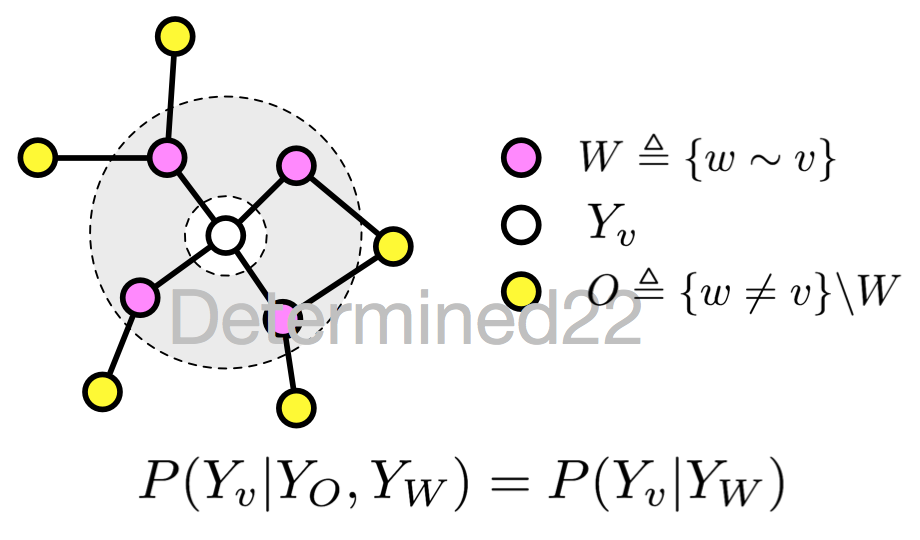
很明显,这就是马尔可夫随机场的定义。
线性链条件随机场
在定义中并没有要求 X 和 Y 具有相同的结构,而在现实中,一般假设 X 和 Y 有相同的图结构。对于线性链条件随机场来说,图 G 的每条边都存在于状态序列 Y 的相邻两个节点,最大团 C 是相邻两个节点的集合,X 和 Y 有相同的图结构意味着每个 XiXi 都与 YiYi 一一对应。
V={1,2,...,n},E={(i,i+1)},i=1,2,...,n−1V={1,2,...,n},E={(i,i+1)},i=1,2,...,n−1
设两组随机变量 X=(X1,...,Xn),Y=(Y1,...,Yn)X=(X1,...,Xn),Y=(Y1,...,Yn) ,那么线性链条件随机场的定义为
P(Yi|X,Y1,...,Yi−1,Yi+1,...,Yn)=P(Yi|X,Yi−1,Yi+1),i=1,...,nP(Yi|X,Y1,...,Yi−1,Yi+1,...,Yn)=P(Yi|X,Yi−1,Yi+1),i=1,...,n
其中当 i 取 1 或 n 时只考虑单边。
一、线性链条件随机场的数学表达式
1. 线性链条件随机场的参数化形式:特征函数及例子
此前我们知道,马尔可夫随机场可以利用最大团的函数来做因子分解。给定一个线性链条件随机场 P(Y|X) ,当观测序列为 x=x1x2⋯x=x1x2⋯ 时,状态序列为 y=y1y2⋯y=y1y2⋯ 的概率可写为(实际上应该写为 P(Y=y|x;θ)P(Y=y|x;θ) ,参数被省略了)
P(Y=y|x)=1Z(x)exp(∑kλk∑itk(yi−1,yi,x,i)+∑lμl∑isl(yi,x,i))P(Y=y|x)=1Z(x)exp(∑kλk∑itk(yi−1,yi,x,i)+∑lμl∑isl(yi,x,i))
Z(x)=∑yexp(∑kλk∑itk(yi−1,yi,x,i)+∑lμl∑isl(yi,x,i))Z(x)=∑yexp(∑kλk∑itk(yi−1,yi,x,i)+∑lμl∑isl(yi,x,i))
Z(x)Z(x) 作为规范化因子,是对 y 的所有可能取值求和。
序列标注 vs 分类
是不是和Softmax回归挺像的?它们都属于对数线性模型(log linear model),线性链CRF用来解决序列标注问题,Softmax回归、最大熵模型都是用来解决分类问题。但需要注意,这两类问题存在非常大的区别:
(1)如果把序列标注问题看作分类问题,也就是为每一个待标注的位置都当作一个样本然后进行分类,那么将会有很大的信息损失,因为一个序列的不同位置之间存在联系:比如说有一系列连续拍摄的照片,现在想在照片上打上表示照片里的活动内容的标记,当然可以将每张照片单独做分类,但是会损失信息,例如当有一张照片上是一张嘴,应该分类到“吃饭”还是分类到“唱K”呢?如果这张照片的上一张照片内容是吃饭或者做饭,那么这张照片表示“吃饭”的可能性就大一些,如果上一张照片的内容是跳舞,那这张照片就更有可能在讲唱K的事情。(这个例子来自 [5] 的开头。)
(2)不同的序列有不同的长度,不便于表示成同一维度的向量。
(3)状态序列的解集随着序列长度指数级增长,穷举法是不可行的。
特征函数
对于线性链CRF,特征函数是个非常重要的概念:
转移特征 tk(yi−1,yi,x,i)tk(yi−1,yi,x,i) 是定义在边上的特征函数(transition),依赖于当前位置 i 和前一位置 i-1 ;对应的权值为 λkλk 。
状态特征 sl(yi,x,i)sl(yi,x,i) 是定义在节点上的特征函数(state),依赖于当前位置 i ;对应的权值为 μlμl 。
一般来说,特征函数的取值为 1 或 0 ,当满足规定好的特征条件时取值为 1 ,否则为 0 。
以词性标注为例
下面给出一些特征函数的例子,参考自 [5] 。词性标注(Part-of-Speech Tagging,POS)任务是指 the goal is to label a sentence (a sequence of words or tokens) with tags like ADJECTIVE, NOUN, PREPOSITION, VERB, ADVERB, ARTICLE. 在对英文序列进行词性标注时可以使用以下特征:
(1)s1(yi,x,i)=1s1(yi,x,i)=1 ,如果 yi=ADVERByi=ADVERB 且 xixi 以“-ly”结尾;否则为 0 。如果该特征函数有一个较大的正权重,就表明倾向于将 “-ly” 结尾的单词标注为副词。
(2)s2(yi,x,i)=1s2(yi,x,i)=1,如果 i=1i=1 、yi=VERByi=VERB 且 x 以“?”结尾;否则为 0 。如果该特征函数有一个较大的正权重,就表明倾向于将问句的首词标注为动词,例如“Is this a sentence beginning with a verb?”
(3)t3(yi−1,yi,x,i)=1t3(yi−1,yi,x,i)=1,如果 yi−1=ADJECTIVEyi−1=ADJECTIVE 且 yi=NOUNyi=NOUN;否则为 0 。 如果该特征函数有一个较大的正权重,就表明倾向于认为形容词后面跟着名词。
(4)t4(yi−1,yi,x,i)=1t4(yi−1,yi,x,i)=1,如果 yi−1=PREPOSITIONyi−1=PREPOSITION 且 yi=PREPOSITIONyi=PREPOSITION;否则为 0 。 如果该特征函数有一个较大的负权重,就表明倾向于认为介词不会连用。
CRF vs HMM
[5] 中还比较了 HMM 和 CRF在序列标注的异同,作者认为CRF更加强大,理由如下:
(1)可以为每个 HMM 都建立一个等价的 CRF(记号中的 s、l 就是本文的 x、y ):

图片来源:[5]
(2)CRF 的特征可以囊括更加广泛的信息:HMM 基于“上一状态to当前状态”的转移概率以及“当前状态to当前观测”的释放概率,使得当前位置的词(观测)只可以利用当前的状态(词性)、当前位置的状态又只能利用上一位置的状态。但 CRF 的特征函数中,输入包含 (yi−1,yi,x,i)(yi−1,yi,x,i) ,对于当前位置 i 来说可以利用完整的 x 信息。
(3)CRF 的参数的取值没有限制,而 HMM 的参数(转移概率矩阵、释放概率矩阵、初始概率向量)都需要满足一些限制。
2. 线性链条件随机场的简化形式
需要注意的是,以 ∑kλk∑itk(yi−1,yi,x,i)∑kλk∑itk(yi−1,yi,x,i) 这项为例,可以看出外面那个求和号是套着里面的求和号的,这种双重求和就表明了对于同一个特征(k),在各个位置(i)上都有定义。
基于此,很直觉的想法就是把同一个特征在各个位置 i 求和,形成一个全局的特征函数,也就是说让里面那一层求和号消失。在此之前,为了把加号的两项合并成一项,首先将各个特征函数 t(设其共有 K1K1 个)、s(设共 K2K2 个)都换成统一的记号 f :
t1=f1,t2=f2,⋯,tK1=fK1,s1=fK1+1,s2=fK1+2,⋯,sK2=fK1+K2t1=f1,t2=f2,⋯,tK1=fK1,s1=fK1+1,s2=fK1+2,⋯,sK2=fK1+K2
相应的权重同理:
λ1=w1,λ2=w2,⋯,λK1=wK1,μ1=wK1+1,μ2=wK1+2,⋯,μK2=wK1+K2λ1=w1,λ2=w2,⋯,λK1=wK1,μ1=wK1+1,μ2=wK1+2,⋯,μK2=wK1+K2
那么就可以记为
fk(yi−1,yi,x,i)={tk(yi−1,yi,x,i),sl(yi,x,i),k=1,2,...,K1k=K1+l;l=1,2,...,K2fk(yi−1,yi,x,i)={tk(yi−1,yi,x,i),k=1,2,...,K1sl(yi,x,i),k=K1+l;l=1,2,...,K2
wk={λk,μl,k=1,2,...,K1k=K1+l;l=1,2,...,K2wk={λk,k=1,2,...,K1μl,k=K1+l;l=1,2,...,K2
然后就可以把特征在各个位置 i 求和,即
fk(y,x)=∑i=1nfk(yi−1,yi,x,i),k=1,2,...,Kfk(y,x)=∑i=1nfk(yi−1,yi,x,i),k=1,2,...,K
其中 K=K1+K2K=K1+K2 。进而可以得到简化表示形式
P(Y=y|x)=1Z(x)exp∑k=1Kwkfk(y,x)P(Y=y|x)=1Z(x)exp∑k=1Kwkfk(y,x)
Z(x)=∑yexp∑k=1Kwkfk(y,x)Z(x)=∑yexp∑k=1Kwkfk(y,x)
如果进一步,记 w=(w1,w2,...,wK)⊤w=(w1,w2,...,wK)⊤ ,F(y,x)=(f1(y,x),...,fK(y,x))⊤F(y,x)=(f1(y,x),...,fK(y,x))⊤ ,那么可得内积形式:
Pw(Y=y|x)=1Zw(x)exp(w⊤F(y,x))Pw(Y=y|x)=1Zw(x)exp(w⊤F(y,x))
Zw(x)=∑yexp(w⊤F(y,x))Zw(x)=∑yexp(w⊤F(y,x))
3. 线性链条件随机场的矩阵形式
这种形式依托于线性链条件随机场对应的图模型仅在两个相邻节点之间存在边。在状态序列的两侧添加两个新的状态 y0=starty0=start 、yn+1=stopyn+1=stop 。
这里,引入一个新的量 Mi(yi−1,yi|x)Mi(yi−1,yi|x) :
Mi(yi−1,yi|x)=exp∑k=1Kwkfk(yi−1,yi,x,i),i=1,2,...,n+1Mi(yi−1,yi|x)=exp∑k=1Kwkfk(yi−1,yi,x,i),i=1,2,...,n+1
首先,这个量融合了参数和特征,是一个描述模型的比较简洁的量;其次,不难发现,这个量相比于原来的非规范化概率 P(Y=y|x)∝exp∑k=1Kwkfk(y,x)P(Y=y|x)∝exp∑k=1Kwkfk(y,x) ,少了对位置的内层求和,换句话说这个量是针对于某个位置 i (及其前一个位置 i-1 )的。那么,假设状态序列的状态存在 m 个可能的取值,对于任一位置 i = 1,2,...,n+1 ,定义一个 m 阶方阵:
Mi(x)=[exp∑k=1Kfk(yi−1,yi,x,i)]m×m=[Mi(yi−1,yi|x)]m×mMi(x)=[exp∑k=1Kfk(yi−1,yi,x,i)]m×m=[Mi(yi−1,yi|x)]m×m
因为有等式 ∏i[exp∑k=1Kwkfk(yi−1,yi,x,i)]=exp(∑k=1Kwk∑ifk(yi−1,yi,x,i))∏i[exp∑k=1Kwkfk(yi−1,yi,x,i)]=exp(∑k=1Kwk∑ifk(yi−1,yi,x,i)) 成立,所以线性链条件随机场可以表述为如下的矩阵形式:
Pw(Y=y|x)=1Zw(x)∏i=1n+1Mi(yi−1,yi|x)Pw(Y=y|x)=1Zw(x)∏i=1n+1Mi(yi−1,yi|x)
Zw(x)=(M1(x)M2(x)⋯Mn+1(x))(start,stop)Zw(x)=(M1(x)M2(x)⋯Mn+1(x))(start,stop)
其中规范化因子 Zw(x)Zw(x) 是这 n+1 个矩阵的乘积矩阵的索引为 (start,stop)(start,stop) 的元素。 Zw(x)Zw(x) 它就等于以 start 为起点、以 stop 为终点的所有状态路径的非规范化概率 ∏n+1i=1Mi(yi−1,yi|x)∏i=1n+1Mi(yi−1,yi|x) 之和(证明略)。
上面的描述或多或少有些抽象,[1] 中给出了一个具体的例子:给定一个线性链条件随机场,n = 3 ,状态的可能取值为 5 和 7 。设 y0=start=5y0=start=5 、yn+1=stop=5yn+1=stop=5 ,且 M 矩阵在 i = 1,2,...,n+1 的值已知,求状态序列以 start 为起点、以stop为终点的所有状态路径的非规范化及规范化概率。
M1(x)=(a010a010),M2(x)=(b11b21b12b22)M1(x)=(a01a0100),M2(x)=(b11b12b21b22)
M3(x)=(c11c21c12c22),M4(x)=(1100)M3(x)=(c11c12c21c22),M4(x)=(1010)
所有可能的状态路径,共8条(没有刻意区分 Y 和 y 这两种记号):
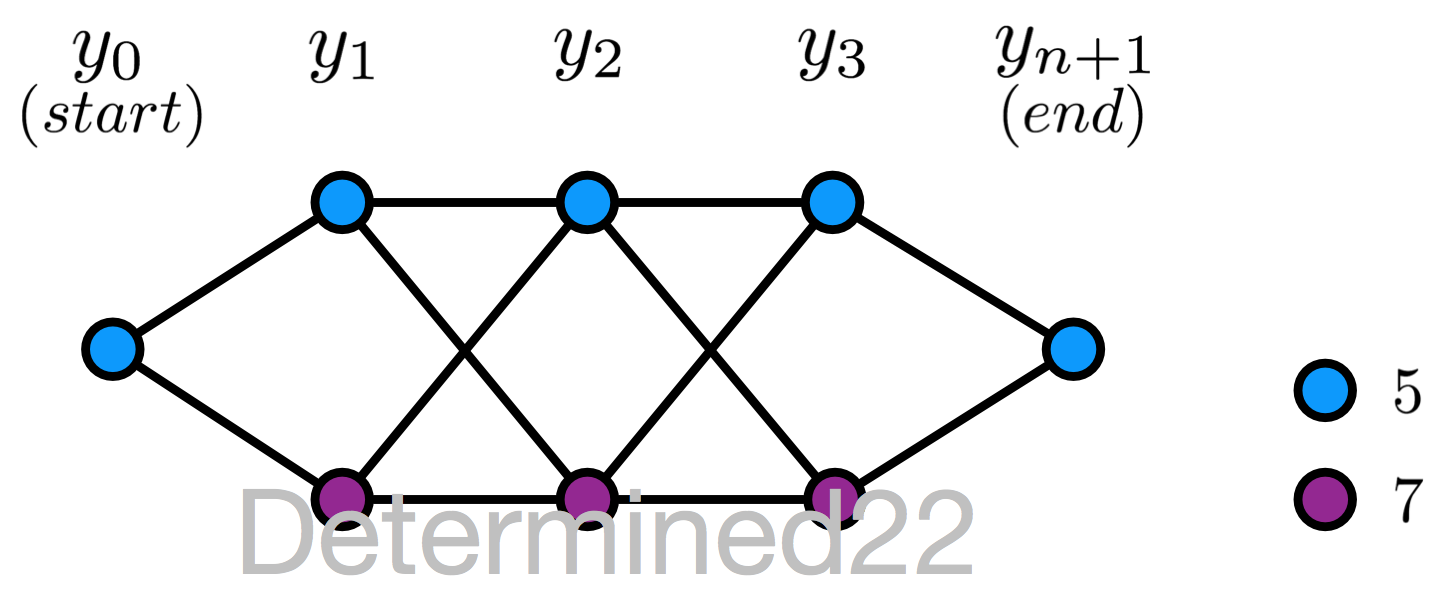
先看一下 M 矩阵的含义。以 M3(x)M3(x) 为例:行索引就是当前位置(此处为3)的上一位置(此处为2)的状态可能取值,列索引就是当前位置的状态可能取值。

每个 M 矩阵的行/列索引都是一致的,对应于状态的可能取值。因此,M 矩阵的每个元素值就有点Markov chain里的“转移概率”的意思:以 M3(x)M3(x) 的 c12c12 为例,它的行索引是5,列索引是7,可以“看作”是上一位置(2)的状态是5且当前位置(3)的状态是7的“非规范化转移概率”。
那么根据公式 Pw(Y=y|x)∝∏i=1n+1Mi(yi−1,yi|x)Pw(Y=y|x)∝∏i=1n+1Mi(yi−1,yi|x) ,可知状态序列 y0y1⋯y4y0y1⋯y4 为 (5, 5, 5, 7, 5) 的非规范化概率为 a01×b11×c12×1a01×b11×c12×1 ,其中 a01a01 是位置0的状态为5且位置1的状态为7的“转移概率”,其他三项亦可以看作“转移概率”。同理,可求得其他七条路径的非规范化概率。
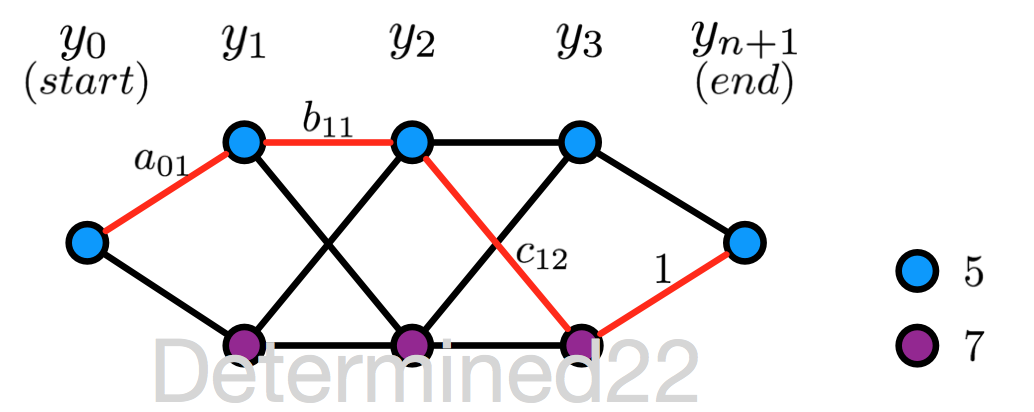
规范化因子就等于 M1(x)M2(x)M3(x)M4(x)M1(x)M2(x)M3(x)M4(x) 的行索引为5、列索引为5的值,经计算,等于所有8条路径的非规范化概率之和。
二、线性链条件随机场的计算问题
与隐马尔可夫模型类似,条件随机场也有三个基本问题:计算问题、解码问题和学习问题,其中前两个问题属于inference,第三个问题当然是learning。下面简单介绍。
CRF的计算问题是指,给定一个条件随机场 P(Y|X) 、观测序列 x 和状态序列 y ,计算P(Yi=yi|x)P(Yi=yi|x) 、P(Yi−1=yi−1,Yi=yi|x)P(Yi−1=yi−1,Yi=yi|x) 以及特征函数关于分布的期望。
回顾一下HMM,当时解决这个问题使用的是前向算法/后向算法。这里类似,对每个位置 i =0,1,...,n+1 ,定义前向向量 αi(x)αi(x) :
α0(y|x)={1,0,y=startotherwiseα0(y|x)={1,y=start0,otherwise
αi(yi|x)=∑yi−1αi−1(yi−1|x)Mi(yi−1,yi|x),i=1,2,...,n+1αi(yi|x)=∑yi−1αi−1(yi−1|x)Mi(yi−1,yi|x),i=1,2,...,n+1
αi(yi|x)αi(yi|x) 的含义是在位置 i 的标记 Yi=yiYi=yi 且从起始位置到位置 i 的局部标记序列的非规范化概率,这个递推式子可以直观地把 Mi(yi−1,yi|x)Mi(yi−1,yi|x) 理解为“转移概率”,求和号表示对 yi−1yi−1 的所有可能取值求和。写成矩阵的形式就是下式
α⊤i(x)=α⊤i−1(x)Mi(x)αi⊤(x)=αi−1⊤(x)Mi(x)
这里的 αi(x)αi(x) 是 m 维列向量,因为每个位置的标记都有 m 种可能取值,每一个维度都对应一个 αi(yi|x)αi(yi|x) 。
类似地,可以定义后向向量 βi(x)βi(x) :
βn+1(yn+1|x)={1,0,yn+1=stopotherwiseβn+1(yn+1|x)={1,yn+1=stop0,otherwise
βi(yi|x)=∑yi+1Mi+1(yi,yi+1|x)βi+1(yi+1|x),i=0,1,...,nβi(yi|x)=∑yi+1Mi+1(yi,yi+1|x)βi+1(yi+1|x),i=0,1,...,n
βi(yi|x)βi(yi|x) 的含义是在位置 i 的标记 Yi=yiYi=yi 且从位置 i+1 到位置 n 的局部标记序列的非规范化概率。写成矩阵的形式就是
β⊤i(x)=Mi+1(x)βi+1(x)βi⊤(x)=Mi+1(x)βi+1(x)
另外,规范化因子 Z(x)=α⊤n(x)1=1⊤β1(x)Z(x)=αn⊤(x)1=1⊤β1(x) 。
1. 概率值的计算
给定一个CRF模型,那么 P(Yi=yi|x)P(Yi=yi|x) 、P(Yi−1=yi−1,Yi=yi|x)P(Yi−1=yi−1,Yi=yi|x) 可以利用前向向量和后向向量计算为
P(Yi=yi|x)=αi(yi|x)βi(yi|x)Z(x)P(Yi=yi|x)=αi(yi|x)βi(yi|x)Z(x)
P(Yi−1=yi−1,Yi=yi|x)=αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)P(Yi−1=yi−1,Yi=yi|x)=αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)
2. 期望值的计算
(1)特征函数 fkfk 关于条件分布 P(Y|X) 的期望:
EP(Y|x)[fk]=∑yP(Y=y|x)fk(y,x)=∑yP(Y=y|x)∑i=1n+1fk(yi−1,yi,x,i)=∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)P(Yi−1=yi−1,Yi=yi|x)=∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)EP(Y|x)[fk]=∑yP(Y=y|x)fk(y,x)=∑yP(Y=y|x)∑i=1n+1fk(yi−1,yi,x,i)=∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)P(Yi−1=yi−1,Yi=yi|x)=∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)
第一个等号,可以看出计算代价非常大,但转化为第二个等号后,便可利用前向向量和后向向量来高效计算。
(2)特征函数 fkfk 关于联合分布 P(X,Y) 的期望:
这里假设已知边缘分布 P(X) 的经验分布为 P˜(X)P~(X) ,经验分布就是根据训练数据,用频数估计的方式得到 P˜(X=x)=#xNP~(X=x)=#xN。
EP(X,Y)[fk]=∑x,yP(x,y)fk(y,x)=∑xP˜(x)∑yP(Y=y|x)∑i=1n+1fk(yi−1,yi,x,i)=∑xP˜(x)∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)EP(X,Y)[fk]=∑x,yP(x,y)fk(y,x)=∑xP~(x)∑yP(Y=y|x)∑i=1n+1fk(yi−1,yi,x,i)=∑xP~(x)∑i=1n+1∑yi−1yifk(yi−1,yi,x,i)αi−1(yi−1|x)Mi(yi−1,yi|x)βi(yi|x)Z(x)
第二个等号那里类似于最大熵模型的条件熵的定义。
对于给定的观测序列 x 和标记序列 y ,通过一次前向扫描计算 αiαi 及 Z(x)Z(x) ,一次后向扫描计算 βiβi ,进而计算所有的概率值,以及特征的期望。
三、线性链条件随机场的解码问题
解码问题即预测问题,给定条件随机场 P(Y|X) 和观测序列 x ,求最有可能的状态序列 y* 。与 HMM 类似,使用维特比算法求解。
四、线性链条件随机场的学习问题
CRF是定义在时序数据上的对数线性模型,使用 MLE 和带正则的 MLE 来训练。类似于最大熵模型,可以用改进的迭代尺度法(IIS)和拟牛顿法(如BFGS算法)来训练。
训练数据 {(x(j),y(j))}Nj=1{(x(j),y(j))}j=1N 的对数似然函数为
L(w)=LP˜(Pw)=ln∏j=1NPw(Y=y(j)|x(j))=∑j=1NlnPw(Y=y(j)|x(j))=∑j=1Nlnexp∑Kk=1wkfk(y(j),x(j))Zw(x(j))=∑j=1N(∑k=1Kwkfk(y(j),x(j))−lnZw(x(j)))L(w)=LP~(Pw)=ln∏j=1NPw(Y=y(j)|x(j))=∑j=1NlnPw(Y=y(j)|x(j))=∑j=1Nlnexp∑k=1Kwkfk(y(j),x(j))Zw(x(j))=∑j=1N(∑k=1Kwkfk(y(j),x(j))−lnZw(x(j)))
或者可以这样写:
L(w)=LP˜(Pw)=ln∏x,yPw(Y=y|x)P˜(x,y)=∑x,yP˜(x,y)lnPw(Y=y|x)=∑x,yP˜(x,y)lnexp∑Kk=1wkfk(y,x)Zw(x)=∑x,yP˜(x,y)∑k=1Kwkfk(y,x)−∑x,yP˜(x,y)lnZw(x)=∑x,yP˜(x,y)∑k=1Kwkfk(y,x)−∑xP˜(x)lnZw(x)L(w)=LP~(Pw)=ln∏x,yPw(Y=y|x)P~(x,y)=∑x,yP~(x,y)lnPw(Y=y|x)=∑x,yP~(x,y)lnexp∑k=1Kwkfk(y,x)Zw(x)=∑x,yP~(x,y)∑k=1Kwkfk(y,x)−∑x,yP~(x,y)lnZw(x)=∑x,yP~(x,y)∑k=1Kwkfk(y,x)−∑xP~(x)lnZw(x)
最后一个等号是因为 ∑yP(Y=y|x)=1∑yP(Y=y|x)=1 。顺便求个导:
∂L(w)∂wi=∑x,yP˜(x,y)fi(x,y)−∑x,yP˜(x)Pw(Y=y|x)fi(x,y)=EP˜(X,Y)[fi]−∑x,yP˜(x)Pw(Y=y|x)fi(x,y)∂L(w)∂wi=∑x,yP~(x,y)fi(x,y)−∑x,yP~(x)Pw(Y=y|x)fi(x,y)=EP~(X,Y)[fi]−∑x,yP~(x)Pw(Y=y|x)fi(x,y)
似然函数中的 lnZw(x)lnZw(x) 项是一个指数函数的和的对数的形式。关于这一项在编程过程中需要注意的地方可以参考这篇博客。
参考:
[1] 统计学习方法
[2] Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
[3] Conditional Random Fields: An Introduction
[4] An Introduction to Conditional Random Fields for Relational Learning
[5] Introduction to Conditional Random Fields
[6] Log-Linear Models, MEMMs, and CRFs
[7] 基于条件随机场的中文命名实体识别(向晓雯,2006 thesis)
[8] CRF++: CRF++代码分析 CRF++中文分词 CRF++词性标注
[9] 数值优化:理解L-BFGS算法 牛顿法与拟牛顿法学习笔记(五)L-BFGS 算法
[10] 漫步条件随机场系列文章
对于原创博文:如需转载请注明出处http://www.cnblogs.com/Determined22/