这个马氏链蒙特卡洛方法,我这实在是感觉太难了,脑阔疼。不过终于找到一本书详细介绍这个方法《模式识别与机器学习》马春鹏 这个版本的,讲得很详细。就是看不懂。只能一点点慢慢看。
在看的过程中,有许多概率论的知识忘记了。所以就重新回顾了一下这个密度函数变换的知识。

其中h(y)是y=g(x)的反函数
这是比较正统的密度函数转换公式,当然这个前提条件是g(·)必须是严格单调函数。所以说适用范围是有限的。定理证明如下:

证明就是直接利用分布函数与密度函数的关系来计算。证明并不是很难。
例题如下:
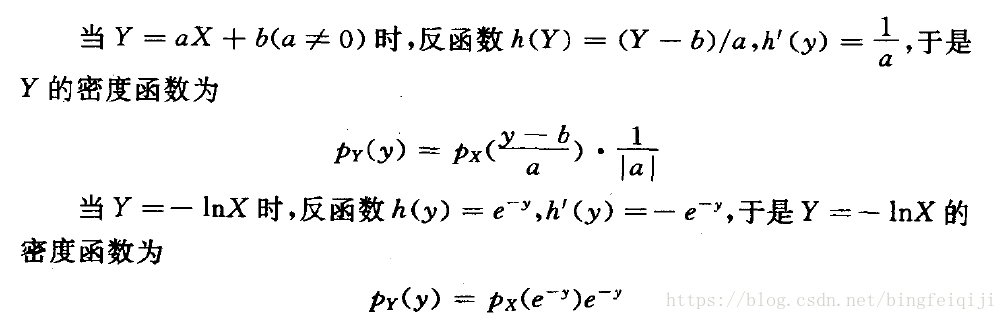
但是这个定理的前提条件要求很明确,必须是严格单调函数。所以说如果不严格,就不能用这个方法,比如说,
,对于这样的函数,这个公式就无能为力了。
对于g(·)不满足严格单调的条件下,应该直接利用分布函数与密度函数的关系进行变换


ojbk,暂时够用了,继续啃 《模式识别与机器学习》了