代码的框架仍然是——《https://github.com/xinntao/BasicSR》
原理
先再次缕一缕SRGAN的loss。本部分主要是对于《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial
Network》第二部分的理解
SRGAN的目标就是利用G网络来作为SR网络。所以目标就是要训练一个好的G网络。这是SR网络的loss function
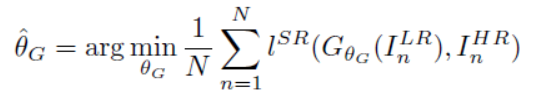
![]() 为G网络;
为G网络;

![]()
首先介绍Adversarial network architecture
The general idea behind this formulation is that it allows one to train a generative model G with the goal of fooling a differentiable discriminator D that is trained to distinguish super-resolved images from real images.G网络生成让D网络以为是真的超分的图片。


This encourages perceptually superior solutions residing in the subspace, the manifold, of natural images.这种做法可以产生更加natural的图片。
G网络和D网络的结构如下图所示

对于Perceptual loss——就是SR的loss,是用于评判G网络的性能的。


Content loss——内容上的损失
对于基于像素维度的MSE loss,就是通过下面公式来计算的。大部分的超分算法(非GAN)都是采用这个,正如本人的其他博文提到的那样,这样的loss会使得SR结果过平滑

而本文不采用这种loss,本文定义了一种称为VGG的loss

Adversarial loss——对抗损失。This encourages our network to favor solutions that reside on the manifold of natural images
理解如下,一般对于SR任务,loss会分为三种。MSE为代表的loss、perceptual loss,以及GAN的loss(Adversarial loss)。而GAN的loss就是用来训练G网络的loss,而perceptual loss就是G网络用于SR任务上,用于评估G网络的性能的loss。
训练过程的理解:
LR输入G网络,G网络输出一个SR的结果,SR跟HR在D网络上得到一个对抗损失(Adversarial loss);SR跟HR在VGG19上上得到contest loss(或者一般现在会把他称为perceptual loss)Content loss损失(或者一般现在会把他称为感知损失Perceptual loss)。两个loss同时作为优化的函数,故此会有原文中的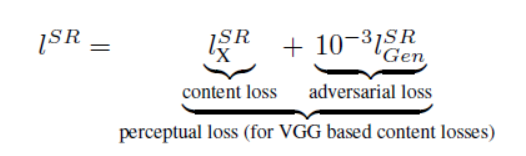

代码
好接下来给出代码的注释

python train.py -opt options/train/train_esrgan.json
python test.py -opt options/test/test_esrgan.json
先给出setting
{
"name": "SRGAN_x4_DIV2K" // please remove "debug_" during training
, "use_tb_logger": true
, "model":"srgan"
, "scale": 4
, "gpu_ids": [3,4,5]
, "datasets": {
"train": {
"name": "DIV2K"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/DIV2K800_sub_bicLRx4"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16
, "HR_size": 128
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "val_set5"
, "mode": "LRHR"
, "dataroot_HR": "/home/guanwp/BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "/home/guanwp/BasicSR_datasets/val_set5/Set5_sub_bicLRx4"
}
}
, "path": {
"root": "/home/guanwp/BasicSR-master",
"pretrain_model_G": null
,"experiments_root": "/home/guanwp/BasicSR-master/experiments/",
"models": "/home/guanwp/BasicSR-master/experiments/SRGAN_x4_DIV2K/models",
"log": "/home/guanwp/BasicSR-master/experiments/SRGAN_x4_DIV2K",
"val_images": "/home/guanwp/BasicSR-master/experiments/SRGAN_x4_DIV2K/val_images"
}
, "network_G": {
"which_model_G": "sr_resnet" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64
, "nb": 16// number of residual block
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
, "network_D": {
"which_model_D": "discriminator_vgg_128"
, "norm_type": "batch"
, "act_type": "leakyrelu"
, "mode": "CNA"
, "nf": 64
, "in_nc": 3
}
, "train": {
"lr_G": 1e-4
, "weight_decay_G": 0
, "beta1_G": 0.9
, "lr_D": 1e-4
, "weight_decay_D": 0
, "beta1_D": 0.9
, "lr_scheme": "MultiStepLR"
, "lr_steps": [50000, 100000, 200000, 300000]
, "lr_gamma": 0.5
, "pixel_criterion": "l1"
, "pixel_weight": 0//1e-2//just for the NIQE, you should set to 0
, "feature_criterion": "l1"
, "feature_weight": 1
, "gan_type": "vanilla"
, "gan_weight": 5e-3
//for wgan-gp
, "D_update_ratio": 1//for the D network
, "D_init_iters": 0
// , "gp_weigth": 10
, "manual_seed": 0
, "niter": 6e5//5e5
, "val_freq": 2000//5e3
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 5e3
}
}
先开始实验

下面解读代码
见setting中采用srgan,为此打开__init__.py文件,可以发现应该阅读SRGAN_model.py文件
def create_model(opt):
model = opt['model']##this para is came from the .json file
#the model in jason, decided which modl import
#so if you add a new model, this .py must be modified
if model == 'sr':###this is the SR model
from .SR_model import SRModel as M#take sr as an example
elif model == 'srgan':###this is the SRGAN
from .SRGAN_model import SRGANModel as M
elif model == 'srragan':
from .SRRaGAN_model import SRRaGANModel as M
elif model == 'sftgan':
from .SFTGAN_ACD_model import SFTGAN_ACD_Model as M
else:
raise NotImplementedError('Model [{:s}] not recognized.'.format(model))
m = M(opt)
print('Model [{:s}] is created.'.format(m.__class__.__name__))
return m#return the model
G网络的结构。此处的G网络也可以直接采用之前博文中给出的结构(基于pytorch的SRResNet的复现)
#####################SRResNet########################################################
class SRResNet(nn.Module):#read my CSDN for the nn.Module
#nn.Module is contain the forward and each layyer
def __init__(self, in_nc, out_nc, nf, nb, upscale=4, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):#the .jason file decide the mode is "CNA"
#input channels\output channels\the number of filters in the first layer\thw number of resduial block\upscale\ \relu\Conv -> Norm -> Act\
super(SRResNet, self).__init__()#for the super(),read my CSDN
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)#read the block.py.
resnet_blocks = [B.ResNetBlock(nf, nf, nf, norm_type=norm_type, act_type=act_type,\
mode=mode, res_scale=res_scale) for _ in range(nb)]#'nb' is the number of block, and there is 23 in the .jason
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)#here use the BN
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok##Deconvolution
elif upsample_mode == 'pixelshuffle':##there are 'pixelshuffle' in the network.py
upsample_block = B.pixelshuffle_block##the espcn
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*resnet_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
D网络的结构
# VGG style Discriminator with input size 128*128
class Discriminator_VGG_128(nn.Module):
def __init__(self, in_nc, base_nf, norm_type='batch', act_type='leakyrelu', mode='CNA'):
super(Discriminator_VGG_128, self).__init__()
# features
# hxw, c
# 128, 64
conv0 = B.conv_block(in_nc, base_nf, kernel_size=3, norm_type=None, act_type=act_type, \
mode=mode)
conv1 = B.conv_block(base_nf, base_nf, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 64, 64
conv2 = B.conv_block(base_nf, base_nf*2, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv3 = B.conv_block(base_nf*2, base_nf*2, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 32, 128
conv4 = B.conv_block(base_nf*2, base_nf*4, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv5 = B.conv_block(base_nf*4, base_nf*4, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 16, 256
conv6 = B.conv_block(base_nf*4, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv7 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 8, 512
conv8 = B.conv_block(base_nf*8, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv9 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 4, 512
self.features = B.sequential(conv0, conv1, conv2, conv3, conv4, conv5, conv6, conv7, conv8,\
conv9)
# classifier
self.classifier = nn.Sequential(
nn.Linear(512 * 4 * 4, 100), nn.LeakyReLU(0.2, True), nn.Linear(100, 1))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
结果
原文的结果是:

实验实现的结果是:

PSNR的结果要比原文稍微好一点哈~

由上图可得,虽然SRGAN的PSNR是最低的,但是却更加的sharp
补充
nn.BCEWithLogitsLoss()
https://blog.csdn.net/zhangxb35/article/details/72464152?utm_source=itdadao&utm_medium=referral(总结了pytorch中的loss function)




