案例说明
一家跨国旅游企业想对公司近8年历史消费客户做一个分析,了解客户的特征,从而针对不同客户的特征做出相应的营销策略,最大化投入产出比。通过识别高价值、高潜力的客户,实行差异化的客户管理策略,优化客户体验。为实现这一目标,通过客户分群技术,将具有相似特性的客户聚到相同类中,为每个不同特点的客户群体提供具有针对性、个性化的营销和管理活动。

建模分析思路:
1.对于有相关性的变量进行降维,减少变量数目;将变量进行分组,使得同一组的变量能尽量解释业务的一个方面。
2.由于k-means仅用于连续型变量聚类,因此需要对变量进行预处理。对于有序分类变量,如果分类水平较多可以按照连续变量处理,否则按无序分类处理,再进入模型;无序分类变量数目较少时,可以使用其哑变量编码进入模型。
3.在离散变量不多的情况下,可以做哑变量变换后进入模型。
数据预处理
1.填补缺失值
fill_cols = ['interested_travel','computer_owner','HH_adults_num']
fill_values = {col:travel[col].mode()[0] for col in fill_cols}
travel = travel.fillna(fill_values)
利用众数进行填补
2.修正错误值
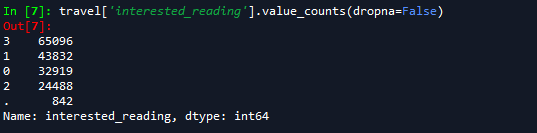
在该数据集中,HH_has_children的分类水平以字符形式表示,需要转换为整型,同时其中的缺失值应当表示没有小孩,因此替换为0;阅读爱好中包含错误信息“.”,将其以0进行替换。
travel['interested_reading'].value_counts(dropna=False)
travel['HH_has_children']=travel['HH_has_children'].replace({'N':0,'Y':1,np.NaN:0})
travel['interested_reading']=travel['interested_reading'].replace({'.':'0'}).astype('int')
3.对离散变量进行处理
_cols=['interested_travel',
'computer_owner',
'marital',
'interested_golf',
'interested_gambling',
'HH_has_children',
'interested_reading']
sample = travel[_cols].sample(3000,random_state=12345)
from itertools import combinations
from scipy import stats
for colA,colB in combinations(_cols,2):
crosstab = pd.crosstab(sample[colA],sample[colB])
pval = stats.chi2_contingency(crosstab)[1]
if pval >0.05:
print('p-value = %0.3f between "%s" and "%s" '%(pval,colA,colB))

这些有相关关系的离散变量大部分都在表述“用户爱好”这一维度,通过变换,将这些变量整合为一个连续变量。可以将旅行、电脑、高尔夫、博彩、阅读这几个分类变量综合成一个“爱好广度”指标,代表了用户休闲娱乐爱好;而连续型的interesrted_sport、HH_dieting属于健康类爱好,auto_member属于奢侈型爱好。
首先对interested_reading进行二值化
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold= 1.5)
travel['interested_reading']=binarizer.fit_transform(travel[['interested_reading']])
将旅行、电脑、高尔夫、博彩、阅读进行加总。
interest = [
'interested_travel',
'computer_owner',
'interested_golf',
'interested_gambling',
'interested_reading'
]
n_ = len(interest)
travel = travel.drop(interest, axis=1).assign(interest=travel[interest].sum(axis=1)/n_)
4.正态化、标准化
continuous_cols = ['age', 'home_value', 'risk_score', 'interested_sport',
'HH_dieting', 'auto_member', 'HH_grandparent',
'HH_head_age', 'loan_ratio']
categorical_cols = ['marital', 'interest', 'HH_adults_num']
discreate_cols = ['HH_has_children']
travel[continuous_cols].hist(bins=25)
from sklearn.preprocessing import QuantileTransformer
qt = QuantileTransformer(n_quantiles=100,output_distribution='normal')
qt_data = qt.fit_transform(travel[continuous_cols])
pd.DataFrame(qt_data,columns = continuous_cols).hist(bins=25)
plt.show()


from sklearn.preprocessing import scale
scale_data = scale(travel[categorical_cols])
data = np.hstack([qt_data, scale_data, travel[discreate_cols]])
data = pd.DataFrame(data, columns=continuous_cols + categorical_cols + discreate_cols)
5.连续变量筛选
强相关连续变量可能造成聚类结果过于注重某个方面的信息,因此需要进行处理。根据业务需求,将变量从两个大的纬度进行考虑:用户家庭属性,用户个人偏好。

household = ['age', 'marital', 'HH_adults_num', 'HH_has_children','HH_grandparent',
'home_value', 'risk_score', 'loan_ratio']
hobby = ['HH_dieting', 'auto_member', 'interest', 'interested_sport']
from sklearn.decomposition import PCA
pca_hh = PCA().fit(data[household])
pca_hh.explained_variance_ratio_.cumsum()

from fa_kit import FactorAnalysis
from fa_kit import plotting as fa_plotting
fa_hh = FactorAnalysis.load_data_samples(
data[household],
preproc_demean= True,
preproc_scale = True)
fa_hh.extract_components()
fa_hh.find_comps_to_retain(method='top_n',num_keep=4)
通过最大方差进行因子旋转,并将各个因子在8个变量上载荷绘制
fa_hh.rotate_components(method = 'varimax')
fa_plotting.graph_summary(fa_hh)


pd.DataFrame(fa_hh.comps['rot'].T,columns=household)

从因子载荷矩阵可以看出:
第一个因子在age、HH_grandparent、HH_head_age上的权重显著较高,从业务上理解这三个变量的综合可以认为是用户所处的生命周期。
第二个因子在home_value、loan_ratio上的权重显著较高,这个因子主要表示用户财务状况。
第三个因子在marital、HH_adults_num上的权重显著较高,该因子主要表示家庭人口规模
第四个因子仅在risk_score上的权重较高,因此该因子代表用户的风险。
data_hh = pd.DataFrame(
np.dot(data[household],fa_hh.comps['rot']),
columns=['life_circle','finance','HH_size','risk'])
fa_hb=FactorAnalysis.load_data_samples(
data[hobby],preproc_demean = True,preproc_scale = True)
fa_hb.extract_components()
fa_hb.find_comps_to_retain(method='top_n',num_keep=3)
fa_hb.rotate_components(method='varimax')
pd.DataFrame(fa_hb.comps['rot'].T,columns=hobby)

从载荷上来看:
第一个因子在auto_member、interested_sport上的权重较高
第二个因子在HH_dieting、interested_sport上权重较高,这是对健康生活方式的度量。
第三个因子仅在interest上权重较高,这是对休闲娱乐偏好的度量。
data_hb = pd.DataFrame(
np.dot(data[hobby],fa_hb.comps['rot']),
columns = ['sport','health','leisure'])
使用k-means聚类建模
商业分析中,有三种聚类算法的实施策略:
先对数据少量采样做层次聚类以确定分群的数量,即确定k,然后再做k-means,由于这个算法先做了层次聚类,其可解释性较高,不过步骤较繁琐。
先做k-means,聚出20-50个小类,然后通过层次聚类聚成3-8个大类,这种算法具有一定可解释性,不过需要对结果进行两次编码。
先使用采样数据通过轮廓系数确定一个最优的k值,然后在这个k值附近做k-means聚类,每次做完后,使用决策树算法进行分群后的特征探查与理解,这种方法最耗时,但是模型可解释性强。
本例中,使用簇内离差平方和及轮廓系数两个指标辅助进行k值选择。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def cluster_plot(data, k_range=range(2, 12), n_init=5, sample_size=2000,
n_jobs=-1):
scores = []
for k in k_range:
kmeans = KMeans(n_clusters=k, n_init=n_init, n_jobs=n_jobs)
kmeans.fit(data)
sil = silhouette_score(data, kmeans.labels_,
sample_size=sample_size)
scores.append([k, kmeans.inertia_, sil])
scores_df = pd.DataFrame(scores, columns=['k','sum_square_dist', 'sil'])
plt.figure(figsize=[9, 2])
plt.subplot(121, ylabel='sum_square')
plt.plot(scores_df.k, scores_df.sum_square_dist)
plt.subplot(122, ylabel='silhouette_score')
plt.plot(scores_df.k, scores_df.sil)
plt.show()
由于经过了因子分析,新获得的因子需要进行标准化,然后使用该函数分析在不同k取值时用户家庭状况指标下的聚类效果
scale_data_hh = scale(data_hh)
models_hh= cluster_plot(scale_data_hh)
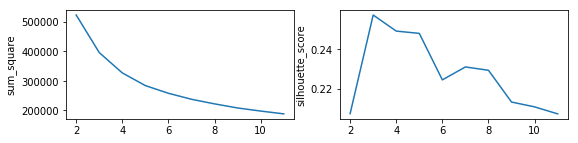
k取3时,轮廓系数最高,而簇内离差平方和的变化在k>3后有叫显著的减缓趋势,结合以上两点,确定k=4比较好。
同理,对用户偏好的因子得分进行标准化,绘制用户偏好的聚类效果如下:
scale_data_hb = scale(data_hb)
models_hb = cluster_plot(scale_data_hb)
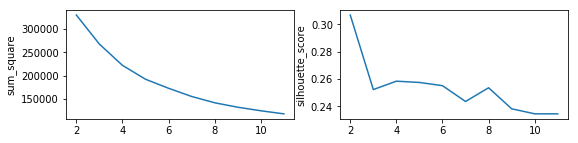
使用偏好状况进行样本聚类时,k>2比k=2的轮廓系数下降大,因此选择k=2。
选择适当k值分别在两个维度下对样本进行聚类,并将相应标签连接至原始数据集:
def k_means(data, k=2, n_init=5, n_jobs=-1):
model = KMeans(n_clusters=k, n_init=n_init, n_jobs=n_jobs)
model.fit(data)
return model.labels_
household_labels = k_means(scale_data_hh, k=4)
hobby_labels = k_means(scale_data_hb, k=2)
label_names = ['HH', 'hobby']
labels = np.vstack([household_labels, hobby_labels]).T
travel_labels = travel.join(pd.DataFrame(labels, columns=label_names))
travel_labels.head()

label_names = ['HH', 'hobby']
labels = np.vstack([household_labels, hobby_labels]).T
travel_labels = travel.join(pd.DataFrame(labels, columns=label_names))
travel_labels.head()

对各个簇的特征进行描述
from sklearn.tree import DecisionTreeClassifier
clf_hb=DecisionTreeClassifier()
clf_hh=DecisionTreeClassifier()
clf_hh.fit(travel_labels[household],travel_labels['HH'])
clf_hb.fit(travel_labels[hobby],travel_labels['hobby'])
import pydotplus
from IPython.display import Image
import sklearn.tree as tree
dot_hh = tree.export_graphviz(
clf_hh,
out_file = None,
feature_names=household,
class_names=['0','1','2','3','4'],
max_depth=2,
filled=True
)
graph_hh = pydotplus.graph_from_dot_data(dot_hh)
Image(graph_hh.create_png())

dot_hb = tree.export_graphviz(
clf_hb,
out_file = None,
feature_names=hobby,
class_names=['0','1'],
max_depth=3,
filled=True
)
graph_hb = pydotplus.graph_from_dot_data(dot_hb)
Image(graph_hb.create_png())

ana = pd.pivot_table(travel_labels,index='HH',columns='hobby',aggfunc='mean').T
ana.swaplevel('hobby',0).sortlevel(0)

