列存储的数据库更适合OLAP
行存储的数据库更适合OLTP
所谓的快只是针对于进行olap操作而言
我们知道,数据在存储中的基本单位为页,这也是进行数据读取时候基本单位,一次读取就是一次IO操作
以sql server为例,一个数据页大小为8K,数据页中存储的是数据,数据是连续存储的
那么我假设如下的4*4表格为一个数据页
再假设,有这样一个表格 字段1 字段2
字段1的值为 col1value1,col1value2.....
字段2的值为col2value1,col2value2......
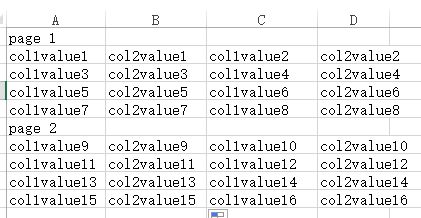
再假设一个excel的单元格为一个存储单位,数据总量占了2个页,
那么以行方式存储大概就这样的:
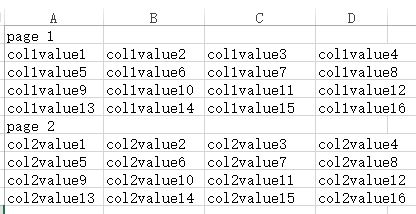
以列方式存储则是这样的:
这时,如果我需要执行如下查询(oltp典型查询)
select 字段1,字段2 from table where 字段1='col1value1'
以行方式查询(在有适当的索引情况下),那么,执行一次以上查询,只需要扫描一次page1就可以了
以列方式查询,需要投其扫描page1 和page2共2次,分别取得字段1,字段2的单行值
OK,我们换成olap的典型查询
select avg(字段2) from table
--(注意,这里假设字段2为一个整型数据,而且无where条件限制,即需要扫描全部数据)
对于行存储,这个查询需要两次IO将全部数据放入内存后,进行页间数据的跳读(类随机读取)
对于列存储,只需要一次IO将page2放入内存后进行连续读取,如果字段2还有多页的话,也都是进行的物理连续读取
也就是说,在进行olap操作时候,不仅是减小了IO次数,而且把随机读取变为了连续读取
详细归纳为如下:
选择列式存储
| 基于一列或比较少的列计算的时候 |
| 经常关注一张表某几列而非整表数据的时候 |
| 数据表拥有非常多的列的时候 |
| 数据表有非常多行数据并且需要聚集运算的时候 |
| 数据表列里有非常多的重复数据,有利于高度压缩 |
选择HANA行式存储
| 关注整张表内容,或者需要经常更新数据 |
| 需要经常读取整行数据 |
| 不需要聚集运算,或者快速查询需求 |
| 数据表本身数据行并不多 |
| 数据表的列本身有太多唯一性的数据 |