本人新书上市,请多多关照:《SQL Server On Linux运维实战 2017版从入门到精通》

这几天我一直在跟进公司的一个性能问题,里面涉及到聚集列存储索引的问题。跟微软的技术支持讨论了一下,他们的建议可以考虑转成非聚集的列存储索引,那我到底怎么做好呢?我觉得有必要研究一下这两者的差异,说不定可以得出一个“不用列存储索引”的结论呢。
为了感觉记录下处理过程,在本系列中先缓一下分区的内容,插播一篇关于列存储的文章。
选择列存储前需要了解的内容
在选择之前,首先要想一下下面的问题:
- 我们到底要不要用列存储索引?
- 如果要用,用在哪些表上?用哪种?
- 如果是非聚集的列存储索引,建在哪些列上?
SQL Server 2012
在SQL 2012的时候,只有非聚集的列存储索引,同时它不允许创建后更新,所以如果选择列存储,就只有非聚集可选且只适合不怎么更新的表。这种限制使得非聚集列存储索引很难被推广。其中不允许更新的限制成了绝大部分企业不使用该功能的最重要因素,虽然可以用一些方式来实现,不过确实不够完美。
SQL Server 2014
SQL Server 2014是一个开拓性的版本,不仅引入了内存技术(这是这个版本最大的亮点),还增强了列存储技术和其他比如AlwaysOn方面的高可用技术。在这个版本中,引入了聚集列存储索引且可更新,但是此时非聚集的列存储索引依旧是不可更新。可更新的聚集列存储索引的出现,一时间使得很多人认为DW只需要聚集的列存储所有,不过当然还没有什么技术是可以面面俱到的。
SQL Server 2016
SQL Server 2016,列存储索引发展成3个独立的体系:
- 基于磁盘的聚集列存储索引:主要针对DW,基于磁盘(disk-based)是相对于基于内存而言,即从SQL 2014出现的内存技术。
- 基于磁盘的可更新的非聚集列存储索引:主要针对混合场景OLTP+实时报表,终于可以更新非聚集列存储了。
- In-Memory 聚集列存储索引:主要针对基于内存技术的混合场景。
到了这个时候,列存储索引基本上就能应对所有常规场景了,聚集列存储索引已经可以应对绝大部分的需求,不过也还有一些场景不适合,比如索引视图,事务复制,CDC等,还有一些数据类型并不支持聚集列存储索引。
SQL Server 2017
SQL Server 2017正式以兼容Linux和Windows平台为主要卖点来发布,针对列存储索引,2017引入了聚集列存储索引对LOBs的支持,对非持久的计算列支持。还有非聚集列存储索引对联机重建的支持。
Azure SQL DB
Azure SQL DB本质上跟当前最新的数据库版本(本文发布时是SQL 2019)相同,并且由于云平台的特性,它具有更快的新功能发布,几乎所有技术都在Auzre上先运用然后才会更新到本地版。
什么时候适合用列存储索引
首先要注意我这里没讨论用哪种,只是考虑用列存储还是行存储(也就是常规索引)。
有几个关键因素会影响是否使用:
- 查询绝大部分表数据时:比如10亿数据的表,经常需要查询9亿数据,那么这个时候列存储索引会很高效。
- 资源比如内存/CPU/磁盘空间是查询性能的瓶颈时:因为列存储索引带有高度压缩的特性,所以对资源有大量要求的查询可以通过列存储索引的方式来减少数据集。
- 列里面包含大量相似的数据或者可以实现高度压缩的数据时。可以大幅度节省空间消耗。
- 针对ETL过程,对于归档所有数据时,聚集列存储索引可以节省大量空间。
如果是考虑聚集列存储索引,首先要考虑是否有不支持的数据类型,其次就是单纯测试性能时,可能需要其他技术来做辅助,比如内存表。
上面的内容也意味着如果你只需要查询少量数据或者高度唯一的数据时,列存储索引并不一定是最好的选择。
假设我们现在确实需要用到列存储索引,那么本文打算介绍一下如何去选择。
影响导入的因素
影响加载速度的关键因素就是尽量减少对基础结构的额外负担。说白了就是没有索引和没有压缩。但是在SQL 2014中,聚集列存储索引的Delta-Stores使用页压缩进行压缩。一开始的设计应该时为了把Delta-Stores占用的空间释放出来,但是从实践来看不见得是有效的。因为不管加载多快,都会被压缩操作拖延总体时间。
从SQL 2016开始,对如并行插入进行了改进。特别是对于具有大量文本列的宽表。它主要的做法是移除Delta-Stores上的压缩。
实验
说太多好像没什么意义,要不还是直接来看实验吧。首先创建一个表,然后通过循环插入100万随机数,看一下在CCITable中使用聚集列存储索引和聚集及非聚集行存储索引的差异。
下面的代码需要单独执行,按照Step来执行,在Step 4和Step 7 时打开实际执行计划,其他时候可以关闭,减少运行时间,不过不关闭也没关系。
第一步,创建一个表,都是BIGINT类型。此时表是堆表。
第二步,循环100万次插入随机数据。并检查表大小
第三步,创建两个非聚集索引。并检查表大小
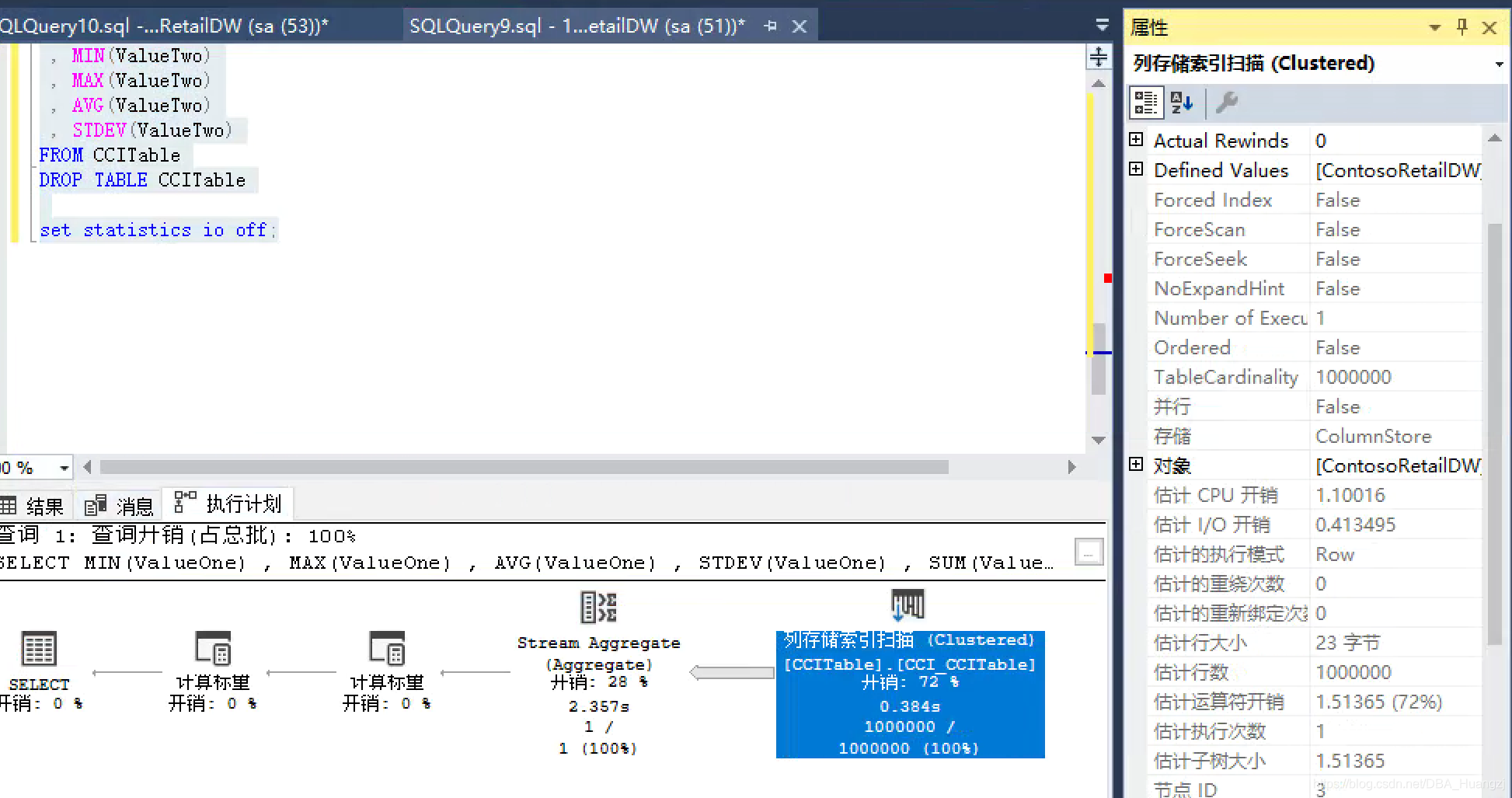
第四步,打开执行计划并包含SET STATISTICS IO命令,进行全表的扫描(实际上就是索引扫描)及聚合计算。可以得到执行计划和IO信息。
第五步,移除表上的所有索引
第六步,创建聚集列存储索引,聚集列存储索引不需要指定列,实际上就是把整个表转换成一个列存储格式。同时检查表大小。
第七步,按照四步的方式再次执行并查看结果。
--Step 1 Create Table
CREATE TABLE CCITable (ValueOne BIGINT, ValueTwo BIGINT, ValueDate DATETIME)
--Step 2 1 million data loading
DECLARE @rand1 BIGINT, @rand2 BIGINT, @b INT = 1
WHILE @b <= 1000000
BEGIN
SELECT @rand1 = CAST(((RAND()*0.00001) * ABS(CHECKSUM(NEWID()))) AS BIGINT)
SELECT @rand2 = CAST(((RAND()*0.0001) * ABS(CHECKSUM(NEWID()))) AS BIGINT)
INSERT INTO CCITable VALUES (@rand1,@rand2,DATEADD(DD,-(@rand1/10),GETDATE()))
SET @b = @b + 1
END
--check the table size
SELECT
s.Name AS SchemaName,
t.Name AS TableName,
p.rows AS RowCounts,
CAST(ROUND((SUM(a.used_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Used_MB,
CAST(ROUND((SUM(a.total_pages) - SUM(a.used_pages)) / 128.00, 2) AS NUMERIC(36, 2)) AS Unused_MB,
CAST(ROUND((SUM(a.total_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Total_MB
FROM sys.tables t
INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
INNER JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE t.name='CCITable'
GROUP BY t.Name, s.Name, p.Rows
--Step 3 create row store index and check the table size again
CREATE NONCLUSTERED INDEX IX_CCITable_ValueDate ON CCITable (ValueDate)
CREATE NONCLUSTERED INDEX IX_CCITable_Value ON CCITable (ValueOne)
SELECT
s.Name AS SchemaName,
t.Name AS TableName,
p.rows AS RowCounts,
CAST(ROUND((SUM(a.used_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Used_MB,
CAST(ROUND((SUM(a.total_pages) - SUM(a.used_pages)) / 128.00, 2) AS NUMERIC(36, 2)) AS Unused_MB,
CAST(ROUND((SUM(a.total_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Total_MB
FROM sys.tables t
INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
INNER JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE t.name='CCITable'
GROUP BY t.Name, s.Name, p.Rows
--Step 4 query
set statistics io on ;
SELECT
MIN(ValueOne)
, MAX(ValueOne)
, AVG(ValueOne)
, STDEV(ValueOne)
, SUM(ValueOne)/(AVG(ValueOne))
, MIN(ValueTwo)
, MAX(ValueTwo)
, AVG(ValueTwo)
, STDEV(ValueTwo)
FROM CCITable
set statistics io off;
--Step 5 remove indexes
DROP INDEX IX_CCITable_ValueDate ON CCITable
DROP INDEX IX_CCITable_Value ON CCITable
--Step 6 Create a clustered columnstore index and check the table size again
CREATE CLUSTERED COLUMNSTORE INDEX CCI_CCITable ON CCITable
SELECT
s.Name AS SchemaName,
t.Name AS TableName,
p.rows AS RowCounts,
CAST(ROUND((SUM(a.used_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Used_MB,
CAST(ROUND((SUM(a.total_pages) - SUM(a.used_pages)) / 128.00, 2) AS NUMERIC(36, 2)) AS Unused_MB,
CAST(ROUND((SUM(a.total_pages) / 128.00), 2) AS NUMERIC(36, 2)) AS Total_MB
FROM sys.tables t
INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
INNER JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE t.name='CCITable'
GROUP BY t.Name, s.Name, p.Rows
--Step 7 query
set statistics io on ;
SELECT
MIN(ValueOne)
, MAX(ValueOne)
, AVG(ValueOne)
, STDEV(ValueOne)
, SUM(ValueOne)/(AVG(ValueOne))
, MIN(ValueTwo)
, MAX(ValueTwo)
, AVG(ValueTwo)
, STDEV(ValueTwo)
FROM CCITable
DROP TABLE CCITable
set statistics io off;
在上面,可以看到我并没有对很多列加索引,因为对于ETL环境,很多表都具有上百个列(我刚处理的公司的情况就是有600列),这样不仅使得索引低效,也使得存储开销明显增大。
如果要查询数百列的表的几乎所有数据,对所有列加索引并使用索引扫描在大多数情况下都没有明显的用处。
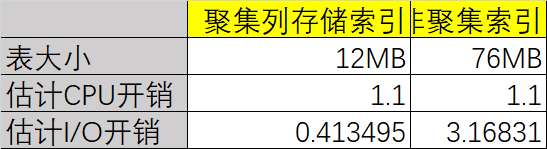
上面代码的结果如下,可以看出列存储索引在这种特定情况下更加有效。
堆表导入速度,36分钟:
堆表占据空间33.45MB

非聚集索引在扫描过程中的I/O情况:
(1 行受影响)
Table 'CCITable'. Scan count 1, logical reads 4274, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
非聚集索引扫描的执行计划:


(1 行受影响)
Table 'CCITable'. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 1177, lob physical reads 2, lob page server reads 0, lob read-ahead reads 3858, lob page server read-ahead reads 0.
Table 'CCITable'. Segment reads 1, segment skipped 0.
另外我们在这个过程中也检查了表的体积,可以看到聚集列存储索引对空间消耗更小。
非聚集索引化后表大小:

只有聚集列存储索引时的表大小:
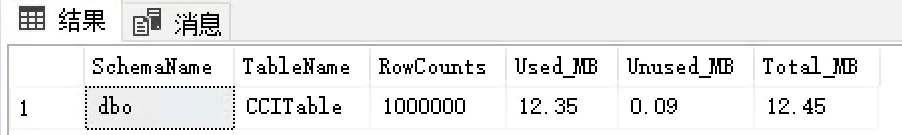
现在我们来试一下相同环境下(换一个表),变成聚集列存储索引后对导入的影响。要注意列存储索引有一个Delta-Store的特性,这个特性会影响性能,一般建议是一次导入刚好超过102400行数据。这样可以不经过Delta-Store,否则数据先进入Delta-Store然后再转换成列存储,这一步会有明显的开销。
CREATE TABLE CCITable_1 (ValueOne BIGINT, ValueTwo BIGINT, ValueDate DATETIME)
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCI_CCITable ON CCITable_1
GO
DECLARE @rand1 BIGINT, @rand2 BIGINT, @b INT = 1
WHILE @b <= 1000000
BEGIN
SELECT @rand1 = CAST(((RAND()*0.00001) * ABS(CHECKSUM(NEWID()))) AS BIGINT)
SELECT @rand2 = CAST(((RAND()*0.0001) * ABS(CHECKSUM(NEWID()))) AS BIGINT)
INSERT INTO CCITable_1 VALUES (@rand1,@rand2,DATEADD(DD,-(@rand1/10),GETDATE()))
SET @b = @b + 1
END
时间对比相差无几,也可以初步判断影响不大,不过这个可能会有很多因素影响结果,所以最好还是在实际环境测一下:

总结
从实验看到,列存储索引,虽然这里没有演示非聚集列存储索引,但是对于特定情况的ETL甚至DW环境,比普通行存储更有用。
当然,所有的决定都依赖于特定环境,如果你的I/O很好,可以考虑直接把表建成聚集列存储索引然后导入。
另外有个非常重要的影响因素就是ETL过程的方式,对于现今的大数据生态系统中各种可以实现ETL过程的软件和其他传统软件,在导入过程的行为都会影响最终的性能。
数据对比: