准备写一个 JNI HelloWorld:
public class HelloWorld {
public native void displayHelloWorld();//所有native关键词修饰的都是对本地的声明
static {
System.loadLibrary("hello");//载入本地库
}
public static void main(String[] args) {
new HelloWorld().displayHelloWorld();
}
}没想到Javac HelloWorld.java 竟然报错:
J:\MAKER\Java源码\JNI尝试>javac Helloworld.java
Helloworld.java:2: error: unmappable character for encoding GBK
public native void displayHelloWorld();//鎵?鏈塶ative鍏抽敭璇嶄慨楗扮殑閮芥槸瀵规湰鍦扮殑澹版槑
^
Helloworld.java:4: error: unmappable character for encoding GBK
System.loadLibrary("hello");//杞藉叆鏈湴搴?
^
Helloworld.java:1: error: class, interface, or enum expected
锘縫ublic class HelloWorld {
^
3 errors
HelloWorld.java是以UTF-8格式编码的,windows在中国用的是GBK编码,(用Windows建立一个文本文档,其默认字符集就是GBK),因此出现的编码错误
然后又顺便去看了下 unicod、utf-8、ASCII 编码的相关知识:
早期是ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)编码,一个字节表示英文和其他符号,后来计算机推广后不够用了。
随着计算机的流行,其他语言也需要在计算机中表示,这时候ASCII开始拓展,出现IS0-8859-1简“Latin 1”、DBCS(double-byte character set)等字符,只不过DBCS不再是国际推行标准,弄得字符表示非常混乱
后来出现了大一统的Unicode编码(万国码,统一码,1990年颁布),Java里的字符内存记录的就是Unicode编码,每个字符4个字节(32bit)表示(相当于一张超级大表),比如汉字“张”(Unicode码为‘0x5f20‘(b0101111100100000)),正规应该是‘0x00005f20’(b00000000000000000101111100100000),这样空间太浪费了,出现了UTF-8编码,规则如下
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

再以“张”为例:0x5F20(b01011111 00100000)在0x0000800-0x000FFFF之间,因此UTF-8格式为b1110XXXX 10XXXXXX 10XXXXXX(三字节表示),因此“张” UTF-8 编码为 :b11100101 10111100 10100000(0xE5BCA0)
那么GBK又是怎么一回事?
维基百科:
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。 GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
GBK的K为汉语拼音Kuo Zhan(扩展)中“扩”字的声母。英文全称Chinese Internal Code Extension Specification。
GBK 只为“技术规范指导性文件”,不属于国家标准。国家质量技术监督局于2000年3月17日推出了GB 18030-2000标准,以取代GBK。GB 18030-2000除保留全部GBK编码汉字,在第二字节把能使用范围再度进行扩展,增加了大约一百个汉字及四位元组编码空间,但是将GBK作为子集全部保留。
也就是说,GBK是中国人自己的编码方式,刚开始只是一个技术规范,2000年推出的GB18030才是官方正式的标准且包含最初的GBK。现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施;
GB18030与Unicode的转化比较复杂:

那么'a'与'张'这两个字符是如何在GB18030中记录的呢?
其和unicode一样,也是一张大表
如:'a' -->GB18030--> 0x61; 'a' -->unicode--> 0x61 ,英文是不变的,这个像UTF-8实现unicode的方式。
' 张' -->GB18030--> 0xD5C5; '张' -->unicode--> 0x5F20,中文是不对应的。
因此以GBK方式编码的字符,如果不通过中间介unicode转化,则会出现乱码。
而若想实现GBK与unicode的转化,则必须有张类似于0xD5C5--> 0x5F20的对应(这个对应关系是没有总体规律的)的位置偏移表,然后去找下Java的位置偏移表在哪里,
Java万物皆对象,封装在Charset中,下面是寻找过程:

encode方法如下:

然后去查找Charset,即lookupCharset方法,而后调用的是Charset中lookup方法:

且这里能看到,java模式的字符编码是UTF-8
![]()

这里寻找的是GBK,发现有一个缓存cache1很有意思,
网上总说Java性能差,这里缓存两个JVM调用过的字符集以增强性能。

cache1[0]存的是字符串类型,cache1[1]存的是Charset类型,所以lookup代码是查找到了直接强转返回(Charset)a[1] ,如果没查找到,调用lookup2方法去查看cache2对象是否有:

有的话,需要维护一下缓存,没的话继续查找:
cs是我们的返回的目标Charset,他调用了standardProvider的charsetForName方法

standardProvider实例化对象是 StandardCharsets对象,这个类的源码里存了很多编码类型

然而并没有GBK。
StandardCharsets继承 FastCharsetProvider类,将上述的字符都存入以下两个map里了
![]()
回到charsetForName方法:

canonicalize(规范化的意思), 也就是你传值utf8可以,也可以传utf-8,他都给你返回utf-8

然后看lookup方法

这里他又自己写了转化小写方法,为了性能也是拼了。
lookup方法:
1、先从缓存中取var3
2、1不是再从标准库中取var4,这里没取到,刚才已经介绍过了。GBK不是国际标准。
3、2不是再看看是不是US_ASCII码(也就是最原始的ASCII码),var7
4、3不是的话就利用反射生成即sun.nio.cs.*生成相应的Charset返回。
sun.nio.cs中只要这么些个类

这里我们继续回到Charset的lookup2方法,

然后在扩展字符集中找, 
实例的是sun.nio.cs.ext.ExtendedCharsets对象,查看其源码:
它也和StandardCharset一样,有很多字符集,我查找一下GBK:
这里然后是调用父类方法查找,找到后返回GBK的Charset,然后记得缓存到cache1中。
然后再看StringCoding类中encode方法:
实例化字符串编码器:
![]()
![]()
而后主要是这段代码:

然后进入ArrayEncoder.encode方法:

var9是中文字符'张'的hashCode值。hashCode值也正好是unicode编码:24352(b101111100100000)(0x5F20)
然后进行一个目前不知道为什么的神秘操作:

24352(b101111100100000)>>8 -->(b1011111)--->95--->this.c2bIndex[95]=4864
24352&255--->(b101111100100000)
&(b000000011111111)-->b100000-->32
这个c2b的char类型数组竟然有28662个字符,
32+4864=4896 this.c2b[4896]= ![]()
即var9=54725 (b1101010111000101),暂时不知道有什么用,

var9>>8=b11010101 (前8位),强制转化为byte只保留8位,然后最高位为符号位,补码(11010101)表示为-43
var9强转为byte只保留后8位即:b11000101,补码(11000101)表示为-59
故var4是一个byte类型数组,两两一组,这里var4[0]为'张'前8位信息,var4[1]为'张'后8位信息,
而b1101010111000101 转化为16进制就是0xD5C5,即GBK中对'张'的编码
这里的c2b和c2bIndex便是位置偏移表,那么在哪个文件中呢?
在sun.nio.cs.ext.GBK中,DoubleBytes调用initC2B方法,初始化得到位置偏移表。
那么UTF-8在Java中的编码是什么过程,没有位移表了吧?
是的,此时是用sun.nio.cs.UT_8类中的encode方法

就是按照上述的两条规则而写的函数, '张'字走的核心代码为:
以“张”为例:0x5F20(b01011111 00100000)在0x0000800-0x000FFFF之间,因此UTF-8格式为b1110XXXX 10XXXXXX 10XXXXXX(三字节表示),因此“张” UTF-8 编码为 :b11100101 10111100 10100000(0xE5BCA0)
这里var8即(b01011111 00100000),var4目标数组,var6是下标,此时为0,则
var4[0]=b 11100000(224) | b 0101 = b11100101 = 0xE5
var4[1]=b 10000000(128) | b 0101111100 & b 111111 = b 10000000(128)| b 111100= b 10111100 = 0xBC (与运算大于或运算)
var4[2]=b 10000000(128) | b 01011111 00100000& b 111111 = b 10000000(128)| b 100000 = b 10100000 = 0xA0 (与运算大于或运算)
此时张的UTF-8编码就是0xE5BCA0
但我还发现:ASCII码也能编码中文了,这是因为前文所介绍的ASCII扩展编码DBCS。那么汉字使用ASCII又是如何表示的呢?
在最初的ASCII中,后7位都用英文表示了,留下了高位没用,此时有计算机的各国开始用剩下的127个码位,中国用,日本用,其他国也用,非常混乱,DBCS是高位的127个码位也不够用了,就使用双字节来表示:
规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了
大家觉得这很不错,于是就称其为GB2312 ,GB2312 是对 ASCII 的中文扩展。 后来发展为GBK,最后国家出台了标准GB18030。
那么既然有大一统的unicode编码,为什么还要有GBK呢?
这得看下时间:从GB2312(1980年)、GBK(1995年)到GB18030(2000年),这些编码方法是向下兼容的
而unicode 1990年开始研发,1994年正式公布。显然满足不了我们的需求。
最后。
UTF-8 可变长的, 1-4个字节 1-32位,但汉字是3个字节。
GB2312和GBK都是DBCS。 2个字节,1-16位
GB18030,也是可变的。
下面是证明
1、Java中对“张a”的输出:
===============GBK2310=========================
d5
c5
61
===============GBK231=========================
d5
c5
61
===============GBK18030=========================
d5
c5
61
===============utf8=========================
e5
bc
a0
61
2、UltraEdit 中的"十六进制功能":
windows中新建一个txt输入,张a,用UltraEdit的十六进制查看就是:

因此此时编码是 ASCII拓展编码 GBK
但若以UTF-8编码‘张a张’:
![]()
能看到E5BCA0,但前面的EFBBBF是什么呢?
Little endian 和 Big endian
上一节已经提到,UCS-2 格式可以存储 Unicode 码(码点不超过0xFFFF)。以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
这里的EFBBBF表示UTF8编码方式,
而unicode是:
littleEndian 张a张
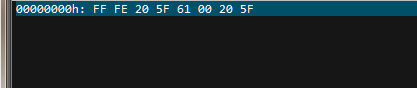
Big endian 张a张
![]()
因此java中默认是big endian。
因此刚开始的问题可以解决了,转化为ASCII扩展码就可以了